- Ollama es gratuito y de código abierto. No requiere cuenta ni suscripción.
- El instalador para Windows y macOS pesa menos de 100 MB. Los modelos se descargan después por separado.
- Mínimo recomendado: 8 GB de RAM para modelos 7B, 16 GB para 13B, 32 GB para 30B+.
- NVIDIA con driver 525+ y Apple Silicon tienen aceleración GPU nativa. AMD solo en Linux con ROCm 6.x.
- El servidor Ollama escucha en
http://localhost:11434y expone una API compatible con OpenAI.
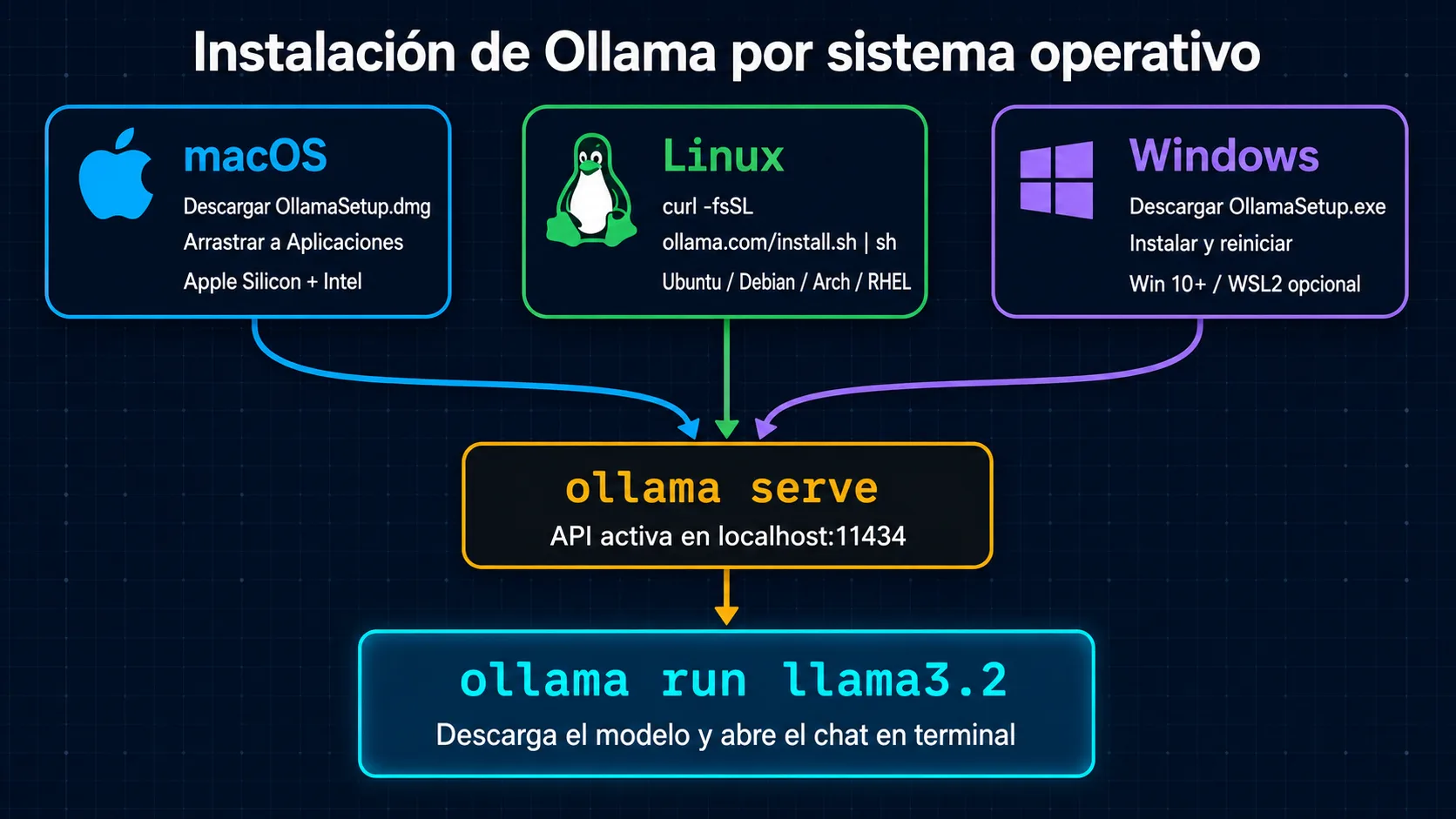
Requisitos de hardware
Ollama funciona en hardware modesto, pero el tamaño del modelo que puedas ejecutar depende directamente de tu RAM y VRAM disponibles.
| Tamaño del modelo | RAM mínima | RAM recomendada | Ejemplos |
|---|---|---|---|
| 1B – 3B parámetros | 4 GB | 8 GB | Llama 3.2:1b, Phi-3 Mini, Gemma 2:2b |
| 7B – 8B parámetros | 8 GB | 16 GB | Llama 3.1:8b, Mistral 7b, Qwen2.5:7b |
| 13B – 14B parámetros | 16 GB | 24 GB | Phi-3 Medium, Qwen2.5:14b |
| 30B – 34B parámetros | 32 GB | 48 GB | Qwen2.5:32b, DeepSeek-R1:32b |
| 70B parámetros | 48 GB | 64 GB | Llama 3.1:70b, Qwen2.5:72b |
GPU AMD: en Linux con ROCm 6.x, las GPUs AMD RX 6000, RX 7000 y RDNA3 tienen soporte completo. En Windows, AMD no tiene aceleración GPU nativa para Ollama a mayo de 2026 — los modelos corren en CPU. En macOS no aplica (solo Intel o Apple Silicon).
CPU pura: Ollama funciona sin GPU, pero la velocidad cae a 3–10 tokens por segundo en modelos 7B con un procesador moderno de 8 núcleos. Es útil para pruebas, pero no para uso interactivo intensivo.
Instalar Ollama en Windows
El instalador oficial para Windows descarga y configura el binario, registra el servicio de fondo y añade Ollama al PATH del sistema en menos de dos minutos.
Requisitos de sistema para Windows
- Windows 10 versión 1903 (mayo 2019) o superior, o Windows 11.
- Para aceleración GPU NVIDIA: driver 525.60.13 o superior.
- Para aceleración GPU AMD en Windows: no disponible de forma nativa (mayo 2026).
- Arquitectura x86-64 (AMD64). No hay versión nativa para ARM en Windows todavía.
Instalación con el instalador gráfico
Paso 1: descargar el instalador
Accede a ollama.com/download/windows
y descarga OllamaSetup.exe. El archivo pesa aproximadamente 90 MB.
Paso 2: ejecutar el instalador
Haz doble clic en OllamaSetup.exe. Windows puede mostrar un aviso
de SmartScreen — haz clic en "Más información" y luego "Ejecutar de todas formas".
El instalador no requiere permisos de administrador en la mayoría de configuraciones.
Paso 3: finalizar la instalación
El instalador coloca el binario en %LOCALAPPDATA%\Programs\Ollama\,
lo añade al PATH del sistema y arranca el servicio de fondo automáticamente.
Verás el icono de Ollama en la bandeja del sistema cuando esté listo.
Instalación con winget (línea de comandos)
Si prefieres no usar el instalador gráfico, puedes instalar Ollama con el gestor
de paquetes de Windows winget disponible en Windows 10 y 11:
# Instalar Ollama con winget
winget install Ollama.Ollama
# Verificar que se instaló correctamente
ollama --versionCaptura: página de descarga oficial
OllamaSetup.exe.
Variables de entorno útiles en Windows
Puedes personalizar el comportamiento de Ollama con variables de entorno en Windows. Configurarlas antes de iniciar el servicio:
# En PowerShell (sesión actual)
$env:OLLAMA_MODELS = "D:\mis-modelos-ollama" # carpeta personalizada para modelos
$env:OLLAMA_HOST = "0.0.0.0:11434" # escuchar en todas las interfaces
$env:OLLAMA_NUM_PARALLEL = "2" # peticiones paralelas
# Para hacer permanentes, editarlas en: Configuración del sistema > Variables de entornoInstalar Ollama en macOS
macOS es la plataforma con mejor soporte para Ollama fuera de Linux. Los chips Apple Silicon ofrecen aceleración Metal nativa con la memoria unificada como VRAM.
Requisitos de sistema para macOS
- macOS 14 Sonoma o superior (recomendado). macOS 12 Monterey y 13 Ventura también funcionan.
- Apple Silicon (M1, M2, M3, M4): aceleración Metal automática. Sin configuración adicional.
- Intel Mac: funciona pero sin aceleración GPU. La memoria unificada no aplica.
Instalación con la app de escritorio
Paso 1: descargar Ollama.app
Ve a ollama.com/download/mac
y descarga el archivo Ollama-darwin.zip (compatible con Apple Silicon e Intel).
Paso 2: instalar la aplicación
Descomprime el ZIP y arrastra Ollama.app a tu carpeta
/Applications. Al abrirla por primera vez, macOS puede pedir
confirmar la apertura de una aplicación descargada de internet.
Paso 3: ejecutar y acceder al CLI
Abre Ollama.app desde Launchpad o Applications. La app instala
el binario de línea de comandos en /usr/local/bin/ollama
automáticamente. Abre Terminal y escribe ollama --version.
Instalación con Homebrew
Si ya usas Homebrew, esta es la opción más cómoda para mantener Ollama actualizado:
# Instalar Ollama con Homebrew
brew install ollama
# Iniciar el servidor Ollama como servicio de fondo
brew services start ollama
# Ver estado del servicio
brew services info ollama
# Actualizar a la última versión
brew upgrade ollamaRendimiento en Apple Silicon
Los chips Apple Silicon (M1, M2, M3, M4) son especialmente adecuados para Ollama gracias a su arquitectura de memoria unificada. Un Mac Mini M4 con 16 GB ejecuta modelos de 13B a 40–60 tokens por segundo, rendimiento que en el mundo PC solo lograrían GPUs discretas de gama media-alta.
Para maximizar el rendimiento en Apple Silicon, asegúrate de que no hay otras aplicaciones intensivas en GPU corriendo simultáneamente. Ollama detecta automáticamente el hardware disponible y configura el número de capas en GPU para maximizar el rendimiento.
Instalar Ollama en Linux
Linux es la plataforma más potente para desplegar Ollama, especialmente en servidores con GPUs NVIDIA o AMD. El instalador automático configura el servicio systemd y las dependencias de driver en un solo comando.
Instalación con el script oficial (recomendado)
El método recomendado para la mayoría de distribuciones (Ubuntu, Debian, Fedora, Arch, etc.) es el script de instalación oficial:
# Descargar y ejecutar el instalador oficial
curl -fsSL https://ollama.com/install.sh | sh
# El script:
# 1. Detecta tu arquitectura (x86_64, aarch64)
# 2. Descarga el binario apropiado
# 3. Instala en /usr/local/bin/ollama
# 4. Crea el usuario de sistema "ollama"
# 5. Registra el servicio systemd ollama.service
# 6. Inicia el servicio automáticamenteTras la instalación, el servicio arranca automáticamente y se configura para iniciarse con el sistema. Puedes verificarlo con:
# Verificar que el servicio está activo
sudo systemctl status ollama
# Ver los logs del servicio
sudo journalctl -u ollama -fInstalación manual (sin script)
Si prefieres instalar manualmente o necesitas mayor control sobre la configuración:
# Descargar el binario directamente (Linux x86_64)
curl -L https://ollama.com/download/ollama-linux-amd64 -o /usr/local/bin/ollama
chmod +x /usr/local/bin/ollama
# Para Linux ARM64 (Raspberry Pi 5, servidores ARM)
curl -L https://ollama.com/download/ollama-linux-arm64 -o /usr/local/bin/ollama
chmod +x /usr/local/bin/ollama
# Crear servicio systemd manualmente
sudo tee /etc/systemd/system/ollama.service > /dev/null <<'EOF'
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
[Install]
WantedBy=default.target
EOF
sudo systemctl daemon-reload
sudo systemctl enable ollama
sudo systemctl start ollamaConfiguración GPU NVIDIA en Linux
Si tienes una GPU NVIDIA, verifica que el driver está instalado antes de ejecutar el script de Ollama. El instalador detectará automáticamente CUDA y configurará las capas en GPU:
# Verificar que el driver NVIDIA está instalado
nvidia-smi
# Si no está instalado, en Ubuntu/Debian:
sudo apt install nvidia-driver-550
# Tras instalar Ollama, verificar que detecta la GPU
ollama run llama3.2:3b
# Debería mostrar: "using NVIDIA GPU" en los logs del servicioConfiguración GPU AMD (ROCm) en Linux
# Instalar ROCm 6.x (Ubuntu 22.04 / 24.04)
wget https://repo.radeon.com/amdgpu-install/latest/ubuntu/focal/amdgpu-install_6.x.xxx.deb
sudo dpkg -i amdgpu-install_6.x.xxx.deb
sudo amdgpu-install --usecase=rocm
# Agregar el usuario al grupo render y video
sudo usermod -aG render,video $USER
# Reiniciar el sistema y verificar
rocminfo | grep -i "device type"
# Ollama detecta ROCm automáticamente si está bien instaladoVariables de entorno en Linux
Para personalizar el comportamiento del servicio, edita el archivo de servicio systemd:
# Editar la configuración del servicio
sudo systemctl edit ollama
# Agregar en la sección [Service]:
[Service]
Environment="OLLAMA_MODELS=/datos/mis-modelos"
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_NUM_PARALLEL=4"
# Aplicar los cambios
sudo systemctl daemon-reload
sudo systemctl restart ollamaVerificación post-instalación
Tras instalar Ollama en cualquier sistema operativo, realiza estas comprobaciones para confirmar que el servidor está funcionando y listo para recibir peticiones.
Comprobaciones básicas
# 1. Verificar la versión instalada
ollama --version
# Salida esperada: ollama version 0.6.x
# 2. Iniciar el servidor manualmente (si no arranca como servicio)
ollama serve
# Salida esperada: Listening on 127.0.0.1:11434 (version 0.6.x)
# 3. En otra terminal, verificar que el endpoint responde
curl http://localhost:11434/api/tags
# Salida esperada: {"models":[]} (lista vacía si no tienes modelos aún)
# 4. Verificar la versión del servidor via API
curl http://localhost:11434/api/version
# Salida esperada: {"version":"0.6.x"}Comprobación de GPU
# Ver si Ollama detecta la GPU al cargar un modelo
ollama run llama3.2:1b --verbose 2>&1 | grep -i "gpu\|cuda\|metal\|rocm"
# En NVIDIA debería aparecer algo como:
# "llama_model_load: using CUDA for GPU computation"
# "ggml_cuda_init: found 1 CUDA devices: GeForce RTX 3060"
# En Apple Silicon:
# "llama_model_load: using Metal for GPU computation"ollama --version muestra un número de versión.
curl localhost:11434/api/tags devuelve JSON (aunque sea vacío).
ollama list ejecuta sin errores.
El icono de Ollama aparece en la bandeja del sistema (Windows/macOS).
ollama serve manualmente o inicia el servicio.
En Linux, comprueba sudo systemctl status ollama.
En Windows, busca el icono en la bandeja del sistema.
Descargar y ejecutar tu primer modelo
Con Ollama instalado y funcionando, descargar y probar un modelo es cuestión de un solo comando.
# Descargar y ejecutar Llama 3.2 (3B, ~2 GB) -- buena opción para empezar
ollama run llama3.2
# Alternativas más ligeras
ollama run gemma2:2b # Gemma 2 de Google, muy eficiente
ollama run phi3:mini # Phi-3 Mini de Microsoft, 3.8B parámetros
# Ver todos los modelos descargados
ollama list
# Eliminar un modelo que no necesitas
ollama rm llama3.2
El comando ollama run descarga el modelo si no está disponible localmente
y abre una sesión de chat interactiva en el terminal. Para salir, escribe
/bye o presiona Ctrl+D.
Si quieres explorar el catálogo completo de modelos disponibles, visita la guía de modelos disponibles en Ollama, donde encontrarás el catálogo completo con requisitos de hardware y recomendaciones por caso de uso.
Cómo desinstalar Ollama completamente
Si necesitas retirar Ollama del sistema, sigue los pasos según tu sistema operativo para eliminar el binario, el servicio y los datos de modelos descargados.
2. Busca "Ollama" y haz clic en Desinstalar.
3. Para borrar los modelos descargados, elimina manualmente la carpeta:
C:\Users\TuUsuario\.ollama\models4. Reinicia el sistema para asegurarte de que el servicio no queda registrado.
2. Mueve
Ollama.app a la Papelera.3. Borra los archivos residuales en Terminal:
rm -rf ~/.ollamasudo rm /usr/local/bin/ollamarm -rf ~/Library/Application\ Support/Ollama
sudo systemctl stop ollama2. Desactivar el servicio:
sudo systemctl disable ollama3. Borrar el binario:
sudo rm $(which ollama)4. Borrar el archivo de servicio:
sudo rm /etc/systemd/system/ollama.service5. Borrar modelos:
sudo rm -rf /usr/share/ollama ~/.ollama
Preguntas frecuentes sobre la instalación de Ollama
El mínimo práctico es 8 GB de RAM para modelos de 7B parámetros. Con 16 GB puedes usar modelos de 13B con comodidad. Para modelos de 30B o más, lo recomendable es contar con 32 GB o más. Si tu GPU tiene suficiente VRAM, el modelo se carga ahí y la RAM del sistema influye menos en el rendimiento.
Sí. Ollama funciona en CPU pura, aunque la velocidad de generación es significativamente más lenta. En un procesador moderno de 8 núcleos puedes esperar entre 3 y 10 tokens por segundo con modelos de 7B, frente a los 30–80 tokens por segundo con una GPU dedicada. Para uso interactivo en producción, una GPU es muy recomendable.
En Linux, Ollama soporta GPUs AMD con ROCm 6.x. Las series RX 6000, RX 7000 y tarjetas de la arquitectura RDNA3 tienen soporte verificado. En Windows, la aceleración GPU para AMD no está disponible de forma nativa a mayo de 2026 — los modelos se ejecutan en CPU. En macOS, los chips Apple Silicon usan aceleración Metal nativa sin depender de ROCm.
Ejecuta ollama --version para ver la versión instalada. Luego
comprueba que el servidor responde con
curl http://localhost:11434/api/tags: si ves un JSON (aunque sea
con la lista de modelos vacía), la instalación es correcta y el servidor está
escuchando en el puerto 11434.
Ve a Configuración > Aplicaciones > Aplicaciones instaladas, busca "Ollama"
y haz clic en Desinstalar. Esto elimina el binario y el servicio. Para borrar
también los modelos descargados, elimina manualmente la carpeta
C:\Users\TuUsuario\.ollama\models. Sin este paso, los modelos
siguen ocupando espacio en disco aunque Ollama esté desinstalado.
No. Ollama es software de código abierto que se instala y ejecuta completamente en local. No requiere cuenta, registro ni conexión permanente a internet. Solo necesitas conexión para descargar el instalador y los modelos la primera vez. Una vez descargados, todo funciona sin internet.