- El rango típico para un agente en producción es $20-$2.000/mes según modelo, volumen y arquitectura.
- El coste real de API es 1,5x a 3x el precio de lista por el overhead de herramientas, reintentos y contexto del sistema.
- El prompt caching reduce hasta un 90% el coste de tokens repetidos; la batch API lo reduce hasta un 50% adicional.
- Un agente de IA cuesta $0,25-$0,50 por interacción frente a $3-$6 de un agente humano, un ahorro del 85-90%.
- El ROI medio documentado es de 3,5x en 12-18 meses para empresas que sustituyen tareas repetitivas con agentes.
¿Cuánto cuesta un agente de IA?
Un agente de IA cuesta entre $20 y $2.000 al mes en la mayoría de implementaciones reales, pero esta cifra solo tiene sentido si entiendes que hay cuatro costes distintos involucrados: el API del modelo de lenguaje, la infraestructura del servidor, las APIs de herramientas externas y el tiempo de desarrollo y mantenimiento. Si solo calculas el coste de los tokens, estarás subestimando el gasto real entre un 50% y un 200%. Antes de elegir un modelo, te recomendamos leer nuestra guía sobre qué es un agente de IA para entender bien cuántas llamadas genera cada ciclo de razonamiento.
La confusión más habitual es tomar el precio de lista de la API (por ejemplo, $3 por millón de tokens de entrada con Claude Sonnet) y multiplicarlo por el número estimado de tokens. Ese cálculo ignora tres factores críticos. Primero, cada llamada a una herramienta externa genera aproximadamente 800 tokens de overhead adicional para formatear la solicitud y procesar la respuesta. Segundo, los agentes fallan y reintentan: un fallo en el paso 4 de un plan de 6 pasos significa que los primeros 4 pasos se vuelven a ejecutar. Tercero, el system prompt del agente, que puede contener instrucciones detalladas y base de conocimiento, se envía completo en cada llamada.
El multiplicador real oscila entre 1,5x y 3x sobre el coste de API puro. Para agentes sencillos con pocas herramientas y system prompts cortos, el multiplicador está cerca de 1,5x. Para agentes autónomos complejos con muchas iteraciones y documentos de referencia extensos, puede llegar a 3x o más.
La buena noticia es que hay técnicas concretas para reducir este gasto drásticamente. El prompt caching puede eliminar hasta el 90% del coste de los tokens de entrada que se repiten. La batch API reduce un 50% adicional para tareas no urgentes. Y el model tiering, usar el modelo más barato que sea capaz de resolver cada subtarea, puede reducir la factura global entre un 60% y un 80% respecto a usar siempre el modelo más capaz. La calculadora de costes de agente IA te permite calcular tu caso concreto en menos de dos minutos.
A lo largo de esta guía usamos precios de mayo de 2026. El mercado de LLMs baja de precio aproximadamente un 30-40% por año, por lo que actualizamos esta página dos veces al año. Si lees esto varios meses después, los precios pueden ser menores.
Los 4 componentes del coste de un agente
El precio de la API es solo una parte. Estos son los cuatro bloques que forman el coste total mensual de cualquier agente en producción.
1. Coste de API del modelo LLM
Es el coste más visible y variable. Se calcula por tokens procesados: tokens de entrada (el prompt completo, incluyendo system prompt, historial y resultados de herramientas) y tokens de salida (la respuesta generada). Los precios van de $0,10/MTok para modelos ultra-económicos hasta $25/MTok para modelos de máxima capacidad. Este componente supone típicamente el 40-70% del coste total.
2. Infraestructura
Servidor o contenedor donde corre el agente, base de datos para persistir memoria y estado de conversaciones, caché (Redis o similar) para almacenar contextos y reducir llamadas a la API, y cola de mensajes si el agente procesa tareas en background. Para agentes pequeños en la nube, este componente puede ser tan bajo como $5-$20/mes. Para agentes de alto tráfico puede superar los $500/mes.
3. Herramientas externas y APIs
Cada herramienta que usa el agente tiene su propio coste: APIs de búsqueda web ($5-$50/mes según volumen), servicios de email ($0,001-$0,01 por envío), bases de datos de terceros, APIs de OCR, servicios de voz o cualquier otra integración. El agente de atención al cliente que consulta el estado de pedidos en una API externa está pagando por cada consulta. Este componente es muy variable y depende completamente del caso de uso.
4. Desarrollo y mantenimiento
El coste menos visible pero muchas veces el mayor. Incluye el tiempo de un desarrollador para construir el agente inicial (típicamente 2-8 semanas para un agente de producción sólido), las iteraciones de prompt engineering, los tests de calidad, el monitoreo de errores en producción y las actualizaciones cuando el modelo subyacente cambia. Para equipos con desarrolladores propios, este coste se amortiza rápidamente. Para proyectos que requieren consultoría externa, puede ser de $5.000 a $50.000 de inversión inicial.

Tabla de precios por modelo LLM
Todos los precios en USD por millón de tokens (MTok). Input = tokens de entrada, Output = tokens de salida. Los precios de modelos de API son a mayo de 2026 — consulta nuestra guía de modelos LLM para análisis completos.
| Modelo | Input ($/MTok) | Output ($/MTok) | Contexto | Tipo | Mejor para |
|---|---|---|---|---|---|
| Claude Haiku | $1,00 | $5,00 | 1M tokens | API | Tareas repetitivas, clasificación, triaje |
| Claude Sonnet | $3,00 | $15,00 | 1M tokens | API | Agentes de producción, equilibrio óptimo |
| Claude Opus | $5,00 | $25,00 | 1M tokens | API | Razonamiento complejo, investigación |
| GPT-5.4-mini | $0,25 | $2,00 | 1M tokens | API | Alto volumen, tareas simples |
| GPT-5.4 | $1,25 | $10,00 | 1M tokens | API | Agentes de proposito general |
| o3 | $2,00 | $8,00 | 200K tokens | API | Razonamiento matemático y lógico |
| Gemini Flash-Lite | $0,10 | $0,40 | 1M tokens | API | Volumen masivo, coste mínimo |
| Gemini 3.5 Flash | $1,50 | $9,00 | 1M tokens | API | Mejor relación precio-calidad del mercado |
| Gemini 3.1 Pro | $2,00 | $12,00 | 2M tokens | API | Contexto muy largo, documentos extensos |
| DeepSeek V4 Flash | $0,14 | $0,28 | 1M tokens | API + Open | Alternativa económica con licencia MIT |
| DeepSeek V4 Pro | $1,74 | $3,48 | 1M tokens | API + Open | Calidad alta con precio competitivo |
| Mistral Small 4 | $0,15 | $0,60 | 32K tokens | Open weight | Despliegue local, privacidad, coste fijo |
| Mistral Large 3 | $0,50 | $1,50 | 128K tokens | Open weight | Calidad frontier con opción de self-hosting |
Nota sobre el caching: Claude, GPT y Gemini ofrecen descuentos de hasta el 90% para tokens en caché (partes del prompt que no cambian entre llamadas). DeepSeek y Mistral en self-hosting no aplican coste por token. Los precios con caché pueden reducir drásticamente el coste real de la API en agentes con system prompts largos.
Ejemplos reales de coste mensual
Tres escenarios típicos con cálculo detallado. Los costes de API incluyen el multiplicador de overhead (1,5x-2x) por llamadas a herramientas y contexto de sistema.
Estos cálculos son estimaciones con los parámetros indicados. Tu caso puede variar según la longitud real de tus conversaciones, el número de herramientas que usa el agente y si aplicas optimizaciones como caching o batch API. Usa la calculadora de costes de agente IA para obtener un número personalizado con tus parámetros exactos.
Cómo reducir costes hasta un 90%
Estas seis técnicas son las que usan los equipos con agentes en producción a gran escala. Aplicadas en conjunto, pueden reducir la factura mensual entre un 60% y un 90%.
Coste vs valor: el ROI de los agentes de IA
El coste de un agente solo tiene sentido si se compara con el valor que genera. Estos son los datos que reportan las empresas que han implementado agentes en producción.
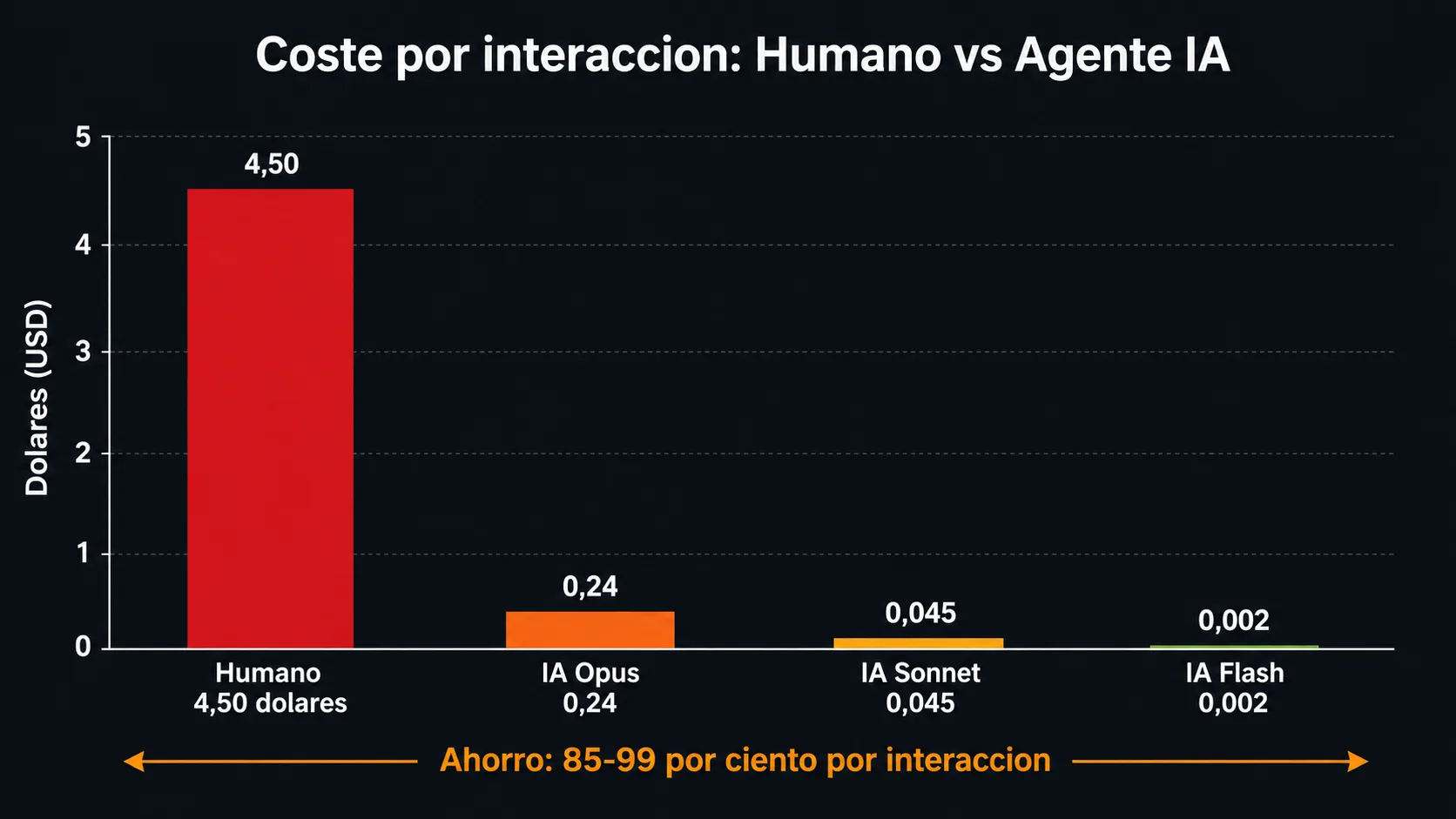
La reducción de coste por interacción del 85-90% (de $4,50 a $0,35) no es el único beneficio económico. Los agentes operan 24/7 sin coste adicional por horas nocturnas o festivos, escalan instantáneamente a picos de demanda sin necesidad de contratar y mantienen consistencia en la calidad de respuesta sin variabilidad humana. Para muchas empresas, el caso de negocio es evidente incluso antes de hacer el cálculo formal.
El cálculo más honesto incluye también los costes ocultos: el tiempo de desarrollo inicial, la curva de aprendizaje del equipo, los fallos del agente que requieren intervención humana y el mantenimiento continuo cuando los modelos o las APIs cambian. Un agente que funciona bien el primer mes puede necesitar ajustes cuando el proveedor actualiza el modelo o cuando el comportamiento cambia sutilmente con una nueva versión. Planifica al menos un 20% del coste de desarrollo inicial como presupuesto anual de mantenimiento.
Consulta nuestra guía sobre frameworks para agentes IA para elegir la arquitectura que minimiza el tiempo de desarrollo y los costes de mantenimiento a largo plazo. Y si tienes dudas sobre qué modelo usar para tu caso concreto, la comparativa de modelos LLM incluye recomendaciones por caso de uso.
Preguntas frecuentes sobre el coste de agentes IA
El rango típico es $20 a $2.000 al mes, dependiendo del modelo LLM, el volumen de conversaciones y la arquitectura. Un agente básico de atención al cliente con 1.000 conversaciones mensuales usando Claude Sonnet cuesta aproximadamente $45/mes sumando API e infraestructura. Un agente de investigación con Opus puede llegar a $120/mes. Un agente de automatización masivo con 50.000 interacciones usando Gemini Flash-Lite puede quedarse en torno a $115/mes. Usa la calculadora para tu caso concreto.
Los modelos más económicos en mayo de 2026 son Gemini Flash-Lite ($0,10/$0,40 por MTok), DeepSeek V4 Flash ($0,14/$0,28) y Mistral Small 4 ($0,15/$0,60). Para casos donde la calidad importa más, Gemini 3.5 Flash ($1,50/$9) ofrece el mejor equilibrio calidad-precio del mercado actualmente. Claude Haiku 4.5 ($1/$5) es la opción de Anthropic más accesible para agentes de producción que requieren las capacidades de tool use de Claude.
Los proveedores cobran por millones de tokens procesados (MTok), con precios distintos para tokens de entrada (el prompt completo: instrucciones del sistema, historial de conversación y resultados de herramientas) y tokens de salida (la respuesta generada por el modelo). En agentes, el coste real es 1,5x a 3x el precio de lista de la API porque hay que sumar:
- Overhead de llamadas a herramientas: ~800 tokens por llamada
- Reintentos cuando el agente comete errores
- System prompt completo enviado en cada llamada
- Historial de conversación acumulado
El prompt caching puede reducir drásticamente el coste de los tokens de entrada que se repiten entre llamadas.
El prompt caching permite reutilizar partes del contexto que no cambian entre llamadas (como el system prompt, documentos de referencia o ejemplos few-shot) sin pagarlas al precio normal. Los tokens en caché cuestan hasta un 90% menos. Para agentes con system prompts largos de 5.000-10.000 tokens o con bases de conocimiento fijas, el caching puede reducir la factura de API a la mitad o más. Claude, GPT-5.4 y Gemini ofrecen caching. DeepSeek y Mistral en API también, aunque con parámetros distintos.
Depende del volumen y de tus requisitos de privacidad. Los modelos locales eliminan el coste por token pero requieren hardware propio: al menos una GPU con 8 GB de VRAM para modelos útiles (16-24 GB para modelos de mayor calidad). A partir de 100.000 tokens diarios, la amortización del hardware empieza a ser competitiva con APIs de bajo coste. Para volúmenes menores, los modelos de API económicos como Gemini Flash-Lite o DeepSeek V4 Flash suelen ser más baratos que mantener infraestructura GPU propia. Si tienes datos sensibles (médicos, legales, financieros), el argumento de privacidad puede justificar el self-hosting independientemente del coste.