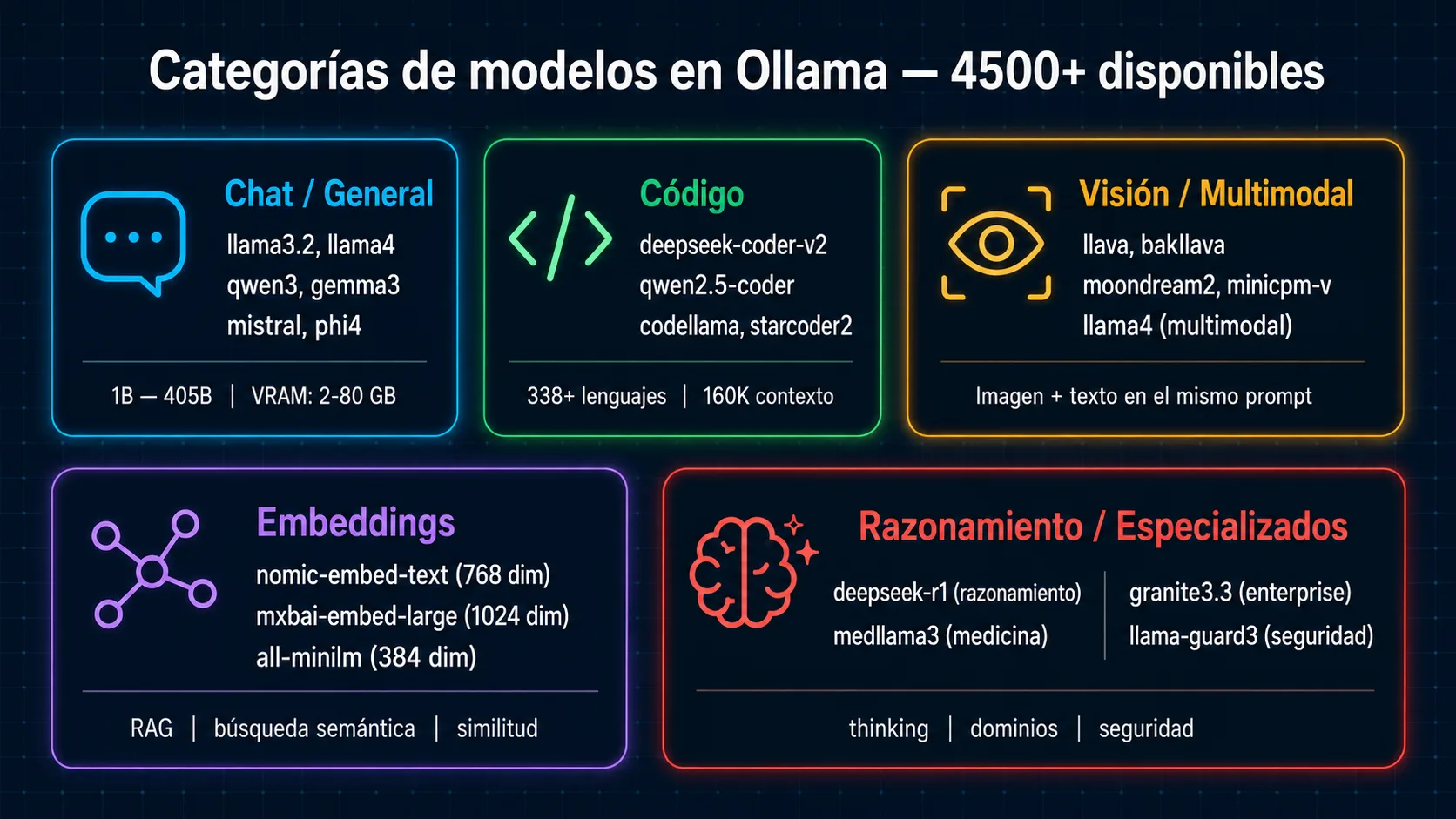
- Más de 4 500 modelos disponibles en ollama.com/library, incluyendo Llama 4, Qwen3, Mistral, DeepSeek-R1 y Gemma 2.
- Un solo comando descarga y ejecuta cualquier modelo:
ollama run nombre:tag. - Ollama selecciona automáticamente la cuantización Q4_K_M por defecto, el mejor equilibrio calidad/tamaño.
- Los modelos de embeddings como
nomic-embed-textgeneran vectores a través del endpoint/api/embeddings. - Con Modelfile puedes crear asistentes personalizados sobre cualquier modelo base en menos de 10 líneas.
Cómo descargar modelos con ollama pull
Todos los modelos del catálogo de Ollama se descargan con el mismo patrón de comandos.
El formato es nombre:tag donde el tag específica el tamaño y la cuantización.
# Descargar un modelo (sin ejecutarlo aún)
ollama pull llama3.2
# Descargar un tamaño específico
ollama pull llama3.1:8b
ollama pull llama3.1:70b
# Descargar una cuantización específica
ollama pull llama3.1:8b-instruct-q8_0 # mayor calidad
ollama pull llama3.1:8b-instruct-q4_K_M # por defecto (recomendado)
ollama pull llama3.1:8b-instruct-q2_K # más comprimido, menos calidad
# Descargar y ejecutar directamente (descarga si no existe)
ollama run mistral
# Ver el progreso de descarga
# Ollama muestra una barra de progreso por capa del modeloTags y convención de nombres
El tag de un modelo en Ollama sigue el patrón
nombre:tamaño-variante-cuantización. Los tags más frecuentes:
| Tag | Significado | Ejemplo |
|---|---|---|
latest |
Versión por defecto del modelo | ollama pull mistral |
:7b, :8b, :13b |
Número de parámetros del modelo | ollama pull qwen2.5:7b |
-instruct |
Modelo ajustado para instrucciones y chat | llama3.1:8b-instruct |
-text |
Modelo base preentrenado (no ajustado) | llama3.1:8b-text |
q4_K_M |
Cuantización 4-bit (por defecto) | qwen3:8b-q4_K_M |
q8_0 |
Cuantización 8-bit (mayor calidad) | mistral:7b-instruct-q8_0 |
La librería oficial: ollama.com/library
Puedes explorar el catálogo también desde la línea de comandos con
ollama search nombre para buscar modelos que coincidan con un
término, o visitando directamente ollama.com/library
para ver las fichas completas con todos los tags y cuantizaciones disponibles.
Familia Llama: el modelo de referencia de Meta
Los modelos Llama de Meta son los más descargados en Ollama y el punto de partida para la mayoría de desarrolladores. La serie Llama 3 y Llama 4 cubren un amplio rango de tamaños y casos de uso.
ollama pull llama3.2:1b # ~800 MB ollama pull llama3.2:3b # ~2.0 GB1–2 GB VRAM
ollama pull llama3.1:8b # ~4.7 GB ollama pull llama3.1:70b # ~40 GB5–40 GB VRAM
ollama pull llama4:scout10–16 GB VRAM activa
ollama pull codellama:7b ollama pull codellama:13bCódigo
Familia Qwen: multilingüe y muy competente
Los modelos Qwen de Alibaba Cloud destacan por su excelente soporte multilingüe (incluyendo español y chino), contexto largo y rendimiento que compite con modelos mucho más grandes.
ollama pull qwen3:8b ollama pull qwen3:14b ollama pull qwen3:32bRecomendado 2026
ollama pull qwen2.5:7b ollama pull qwen2.5:14bMultilingüe
ollama pull qwen2.5-coder:7b ollama pull qwen2.5-coder:14bCódigo
Mistral y Mixtral: eficiencia europea
Los modelos de Mistral AI destacan por su eficiencia: el modelo 7B original superó a Llama 2 70B en muchas tareas. Mixtral usa arquitectura Mixture-of-Experts para ofrecer calidad de 45B con coste de 12B activos.
ollama pull mistral # equivale a: mistral:7b-instruct-v0.34 GB VRAM
ollama pull mixtral:8x7b # ~26 GB ollama pull mixtral:8x22b # ~80 GBMoE
DeepSeek: razonamiento avanzado en local
DeepSeek-R1 sorprendió al mundo en enero 2026 al igualar el rendimiento de modelos propietarios de primer nivel en benchmarks de razonamiento matemático y científico. Disponible en Ollama en varios tamaños.
ollama pull deepseek-r1:7b ollama pull deepseek-r1:14b ollama pull deepseek-r1:32bRazonamiento
ollama pull deepseek-coder-v2 ollama pull deepseek-coder-v2:16bCódigo
ollama pull deepseek-v3Alta VRAM
Gemma y Phi: ligeros y muy eficientes
Google Gemma 2 y Microsoft Phi-3 representan la mejor opción cuando el hardware es limitado. Modelos pequeños con rendimiento desproporcionado para su tamaño.
ollama pull gemma2:2b # ~1.6 GB ollama pull gemma2:9b # ~5.4 GB ollama pull gemma2:27b # ~16 GBGoogle
ollama pull phi3:mini # ~2.2 GB ollama pull phi3:medium # ~8.5 GBMicrosoft
Modelos de embeddings para RAG
Ollama incluye modelos especializados en generar embeddings (vectores de texto) para pipelines RAG, búsqueda semántica y clasificación. Son mucho más eficientes que los modelos de generación para esta tarea.
| Modelo | Dimensiones | Tamaño | Recomendado para | Comando |
|---|---|---|---|---|
| nomic-embed-text | 768 | ~274 MB | Uso general, RAG, inicio rápido | ollama pull nomic-embed-text |
| mxbai-embed-large | 1024 | ~670 MB | Alta precisión, colecciones grandes | ollama pull mxbai-embed-large |
| all-minilm | 384 | ~46 MB | Prototipado rápido, datasets pequeños | ollama pull all-minilm |
| snowflake-arctic-embed | 1024 | ~670 MB | Recuperación de documentos empresarial | ollama pull snowflake-arctic-embed |
Los embeddings se generan a través del endpoint POST /api/embeddings
de Ollama. Este endpoint es independiente del de generación de texto y permite
procesar textos en lote de forma muy eficiente:
# Generar embeddings con curl
curl http://localhost:11434/api/embeddings \
-d '{
"model": "nomic-embed-text",
"prompt": "Este es el texto del que quiero obtener el embedding"
}'
# Respuesta: {"embedding": [0.123, -0.456, ...]} (768 valores)Cuantización: cómo elegir el nivel correcto
La cuantización reduce la precisión numérica de los pesos del modelo para ahorrar memoria. Ollama usa el formato GGUF con varios niveles de cuantización. Elegir el nivel correcto según tu VRAM es crucial para el rendimiento.
| Cuantización | Bits por peso | Calidad relativa | Tamaño vs FP16 | Cuándo usar |
|---|---|---|---|---|
| FP16 | 16 bits | 100% (referencia) | 100% | Cuando tienes VRAM suficiente y quieres máximo rendimiento |
| Q8_0 | 8 bits | ~99% | ~50% | Cuando el tamaño importa pero la calidad es crítica |
| Q4_K_M | 4 bits (mixto) | ~95–97% | ~25% | Por defecto de Ollama. El mejor equilibrio general |
| Q4_0 | 4 bits (uniforme) | ~93% | ~25% | Similar a Q4_K_M pero ligeramente menor calidad |
| Q2_K | 2 bits | ~80% | ~13% | Solo cuando la VRAM es muy limitada y la calidad es secundaria |
Recomendación general: usa Q4_K_M (el valor por
defecto de Ollama) a menos que tengas una razón específica para cambiar. Si tu GPU
tiene VRAM suficiente para el modelo completo, considera Q8_0 para
recuperar el 2-4% de calidad que se pierde con Q4. Evita Q2_K salvo
en situaciones donde la memoria es crítica y la precisión no importa.
Crear modelos custom con Modelfile
Un Modelfile es un archivo de configuración que te permite crear un asistente personalizado sobre cualquier modelo base: sistema de instrucciones, temperatura, tamaño de contexto y parámetros de generación, en menos de 10 líneas.
Estructura de un Modelfile
# Modelfile -- asistente de soporte en español
FROM qwen2.5:7b # modelo base
SYSTEM """
Eres un asistente de soporte técnico en español.
Responde siempre en español, de forma clara y concisa.
Si no sabes la respuesta, dilo explícitamente en vez de inventar.
Evita respuestas de más de 200 palabras salvo que el usuario lo pida.
"""
PARAMETER temperature 0.3 # respuestas más deterministas (0.0 a 1.0)
PARAMETER num_ctx 8192 # ventana de contexto en tokens
PARAMETER num_predict 512 # máximo de tokens a generar por respuesta
PARAMETER top_p 0.9 # nucleus sampling
# Para crear el modelo:
# ollama create soporte-es -f Modelfile
# Para ejecutarlo:
# ollama run soporte-esCrear y gestionar el modelo custom
# Crear el modelo a partir del Modelfile
ollama create mi-asistente -f Modelfile
# Verificar que se creó correctamente
ollama list
# Debería aparecer: mi-asistente latest ...
# Ejecutar el modelo personalizado
ollama run mi-asistente
# Ver los detalles del Modelfile de cualquier modelo
ollama show mi-asistente --modelfile
# Actualizar el modelo (re-ejecutar create con el mismo nombre)
ollama create mi-asistente -f Modelfile
# Eliminar el modelo custom
ollama rm mi-asistenteParámetros disponibles en Modelfile
| Parámetro | Descripción | Valor típico |
|---|---|---|
temperature |
Controla la aleatoriedad. 0 = determinista, 1 = muy creativo | 0.7 (general), 0.3 (técnico) |
num_ctx |
Ventana de contexto en tokens (cuánto "recuerda" el modelo) | 4096, 8192, 32768 |
num_predict |
Máximo de tokens a generar por respuesta (-1 = sin límite) | 512, 2048, -1 |
top_p |
Nucleus sampling: probabilidad acumulada de tokens a considerar | 0.9 |
top_k |
Limita el sampleo a los K tokens más probables | 40 |
repeat_penalty |
Penaliza la repetición de tokens recientes | 1.1 |
num_gpu |
Número de capas a cargar en GPU (-1 = todas) | -1 |
Ejemplo: asistente de código Python
# Modelfile para un asistente especializado en Python
FROM qwen2.5-coder:7b
SYSTEM """
Eres un experto en Python con más de 10 años de experiencia.
Cuando escribas código:
- Usa siempre type hints.
- Incluye docstrings en funciones y clases.
- Prefiere código idiomático y pythonic.
- Si el usuario no especifica, asume Python 3.11+.
Responde en español, pero el código siempre en inglés.
"""
PARAMETER temperature 0.2
PARAMETER num_ctx 16384
PARAMETER num_predict 2048Gestión de modelos instalados
# Ver todos los modelos descargados con su tamaño
ollama list
# Salida ejemplo:
# NAME ID SIZE MODIFIED
# llama3.2:3b a80c4f17acd5 2.0 GB 2 days ago
# qwen2.5:7b 845dbda0ea48 4.7 GB 5 days ago
# nomic-embed-text:latest 0a109f422b47 274 MB 1 week ago
# Ver los modelos que están corriendo actualmente
ollama ps
# Detener un modelo que está en memoria
ollama stop llama3.2:3b
# Eliminar un modelo del disco
ollama rm qwen2.5:7b
# Copiar un modelo (para crear una variante sin Modelfile)
ollama cp llama3.2:3b mi-llama-copia
# Actualizar un modelo a la última versión disponible
ollama pull llama3.2 # si hay versión nueva, la descargaC:\Users\<usuario>\.ollama\models\macOS/Linux:
~/.ollama/models/Puedes cambiar la ubicación con la variable de entorno
OLLAMA_MODELS=/ruta/personalizada antes de iniciar el servidor.
OLLAMA_KEEP_ALIVE=30m (o -1 para mantenerlo
siempre cargado). Útil cuando usas el mismo modelo intensivamente.
Preguntas frecuentes sobre los modelos de Ollama
A mayo de 2026, la librería oficial de Ollama en ollama.com/library contiene más de 4 500 modelos entre variantes de tamaño, cuantizaciones y versiones especializadas. Las familias principales son Llama, Qwen, Mistral, Gemma, DeepSeek, Phi y decenas de modelos de embeddings y visión.
ollama pull descarga el modelo sin ejecutarlo, útil para preparar
modelos antes de necesitarlos o en scripts de configuración. ollama run
descarga el modelo si no existe localmente y abre inmediatamente una sesión de
chat interactiva. Para pipelines automatizados es preferible usar
ollama pull primero para garantizar que el modelo esté disponible
antes de lanzar peticiones a la API.
La versión cuantizada Q4_K_M de Llama 3.1:8b (la que descarga Ollama por defecto) ocupa aproximadamente 4.7 GB de VRAM. Con una GPU de 6 GB como una RTX 3060 o GTX 1660 Super puedes ejecutarla cómodamente. La versión completa en FP16 requiere 16 GB de VRAM. Para el modelo 70B cuantizado a Q4_K_M necesitas aproximadamente 40 GB de VRAM.
Crea un archivo llamado Modelfile con las instrucciones
FROM (modelo base), SYSTEM (prompt del sistema) y
PARAMETER (temperatura, contexto, etc.). Luego ejecuta
ollama create nombre-modelo -f Modelfile para registrar el modelo.
Una vez creado, aparece en ollama list y puedes ejecutarlo con
ollama run nombre-modelo.
Ollama incluye modelos de embeddings especializados: nomic-embed-text
(768 dimensiones, menos de 300 MB, el más popular), mxbai-embed-large
(1024 dimensiones, mayor precisión para colecciones grandes) y all-minilm
(384 dimensiones, muy rápido para prototipado). Estos modelos generan vectores
a través del endpoint POST /api/embeddings y son ideales para
pipelines RAG sin necesidad de APIs externas.
Q4_K_M es una cuantización de 4 bits con precisión mixta: algunas capas críticas del modelo se mantienen en mayor precisión para minimizar la pérdida de calidad. Ollama la usa como valor por defecto porque ofrece el mejor equilibrio: conserva el 95–97% de la calidad del modelo original en FP16, pero ocupa solo el 25% del espacio en VRAM. Para un modelo 7B, esto significa pasar de ~14 GB (FP16) a ~4 GB (Q4_K_M).