- El modelo es el cerebro del agente: determina la calidad del razonamiento, el coste por operación y los límites de lo que el agente puede hacer.
- La ventana de contexto decide cuánta información puede procesar el agente de una sola vez. A mayo de 2026, Claude Sonnet 4.6 ofrece 1M de tokens y Gemini 3.1 Pro hasta 2M, suficiente para analizar documentos completos.
- El coste real de un agente multiplica el precio por token entre 1,5x y 5x por contexto repetido, pasos de razonamiento y llamadas a herramientas. No compares solo el precio base.
- Los modelos propietarios (Claude, GPT, Gemini) son los más capaces pero requieren enviar datos a la nube. Los modelos open weight (Llama, Mistral) permiten ejecución local con privacidad total.
- Para la mayoría de agentes en producción, la elección óptima es un modelo BALANCED como Claude Sonnet o Gemini Flash: equilibran calidad, velocidad y coste sin el precio premium de los modelos frontier.
Qué son los modelos LLM y por qué importan en los agentes de IA
Un modelo de lenguaje grande (LLM) es el núcleo de cualquier agente de IA: el sistema que recibe instrucciones, razona sobre ellas y decide qué acción tomar. A mayo de 2026, los principales modelos para agentes son Claude Sonnet 4.6 y Opus 4.7 de Anthropic, GPT-5.5 y o3 de OpenAI, y Gemini 3.1 Pro y el nuevo Gemini 3.5 Flash de Google, todos con ventanas de contexto de 1M de tokens o más. La elección del modelo determina directamente la calidad del razonamiento, el coste por operación y los límites del agente.
A diferencia de un chatbot que solo responde preguntas, un agente usa el LLM en un bucle continuo: recibe una tarea, razona sobre qué herramientas necesita, las ejecuta, observa el resultado y replantea su estrategia si algo falla. Esto significa que cada tarea puede implicar entre 3 y 20 llamadas al modelo. El coste total de un agente no es el precio de una sola llamada, sino la suma de todas las llamadas en el ciclo de razonamiento, incluido el contexto acumulado que crece en cada paso.
El ecosistema de modelos ha evolucionado hacia una estructura de tiers clara. Cada proveedor ofrece tres niveles: un modelo frontier para tareas de máxima complejidad (Opus, GPT-5.4, Gemini Pro), un modelo balanced como caballo de batalla en producción (Sonnet, GPT-5.4 en uso moderado, Gemini Flash), y un modelo fast para tareas de baja complejidad donde la latencia y el coste son prioritarios (Haiku, GPT-4.1-nano, Flash-Lite). Esta estructura permite asignar el modelo correcto según el paso del agente: razonamiento con el modelo frontier, ejecución con el balanced, y tareas de clasificación con el fast.
Los tres factores clave al elegir un modelo para agentes
Elegir el modelo adecuado para un agente implica equilibrar tres dimensiones que a menudo entran en conflicto:
1. Coste por operación
El precio de los modelos se mide en dólares por millón de tokens (MTok), diferenciando entre tokens de entrada (input) y de salida (output). Los tokens de salida cuestan entre 3x y 10x más que los de entrada porque requieren más cómputo generativo. En un agente típico, el contexto acumulado (instrucciones del sistema, historial de conversación, resultados de herramientas) domina los tokens de entrada, mientras que el razonamiento y las respuestas estructuradas generan los tokens de salida.
La buena noticia es que tanto Anthropic como Google ofrecen prompt caching: si el inicio del contexto no cambia entre llamadas (lo cual ocurre típicamente con las instrucciones del sistema), las llamadas cacheadas cuestan entre un 80% y un 90% menos. Un agente bien diseñado con prompt caching activo puede reducir su coste real a una fracción del precio de lista. Consulta la guía de costes de agentes IA para ver cálculos reales por caso de uso.
2. Ventana de contexto
La ventana de contexto determina cuánta información puede procesar el modelo de una sola vez. A , Claude Sonnet 4.6 y Opus 4.7 ofrecían 1M de tokens de contexto, equivalente a aproximadamente 750.000 palabras o varios libros completos. Gemini 3.1 Pro y Flash alcanzaban también 1M de tokens. Esta capacidad es crítica para agentes que necesitan analizar documentos largos, mantener un historial de conversación extenso o razonar sobre grandes bases de código sin fragmentar el contenido.
Sin embargo, un contexto mayor no siempre es mejor: los modelos tienden a perder precisión cuando el contexto está cerca de su límite máximo, y el coste crece linealmente con el número de tokens. Para la mayoría de aplicaciones, una ventana de 200K tokens (como la de Claude Haiku 4.5) es más que suficiente. Reserva los modelos de 1M de contexto para casos de uso que genuinamente los necesitan.
3. Capacidades de razonamiento
No todos los modelos razonan igual. Los modelos frontier (Opus 4.7, o3, Gemini 3.1 Pro) son capaces de razonamiento multi-paso complejo, planificación a largo plazo y resolución de problemas que requieren mantener múltiples hipótesis en paralelo. Los modelos balanced (Sonnet 4.6, GPT-5.4 en uso estándar) manejan con solvencia la mayoría de tareas de agentes: llamadas a herramientas, extracción de datos estructurados, generación de código y toma de decisiones con contexto moderado. Los modelos fast (Haiku 4.5, GPT-4.1-nano, Flash-Lite) son excepcionales para clasificación, routing y tareas donde la respuesta correcta no requiere razonamiento profundo.
Para la arquitectura de un agente en producción, lo más eficiente es usar un framework que permita enrutar cada paso al modelo adecuado según su complejidad, en lugar de pasar todo por el modelo más caro. Esta estrategia puede reducir el coste total entre un 40% y un 70% manteniendo la misma calidad de resultado.
Comparativa de precios y contexto — mayo 2026
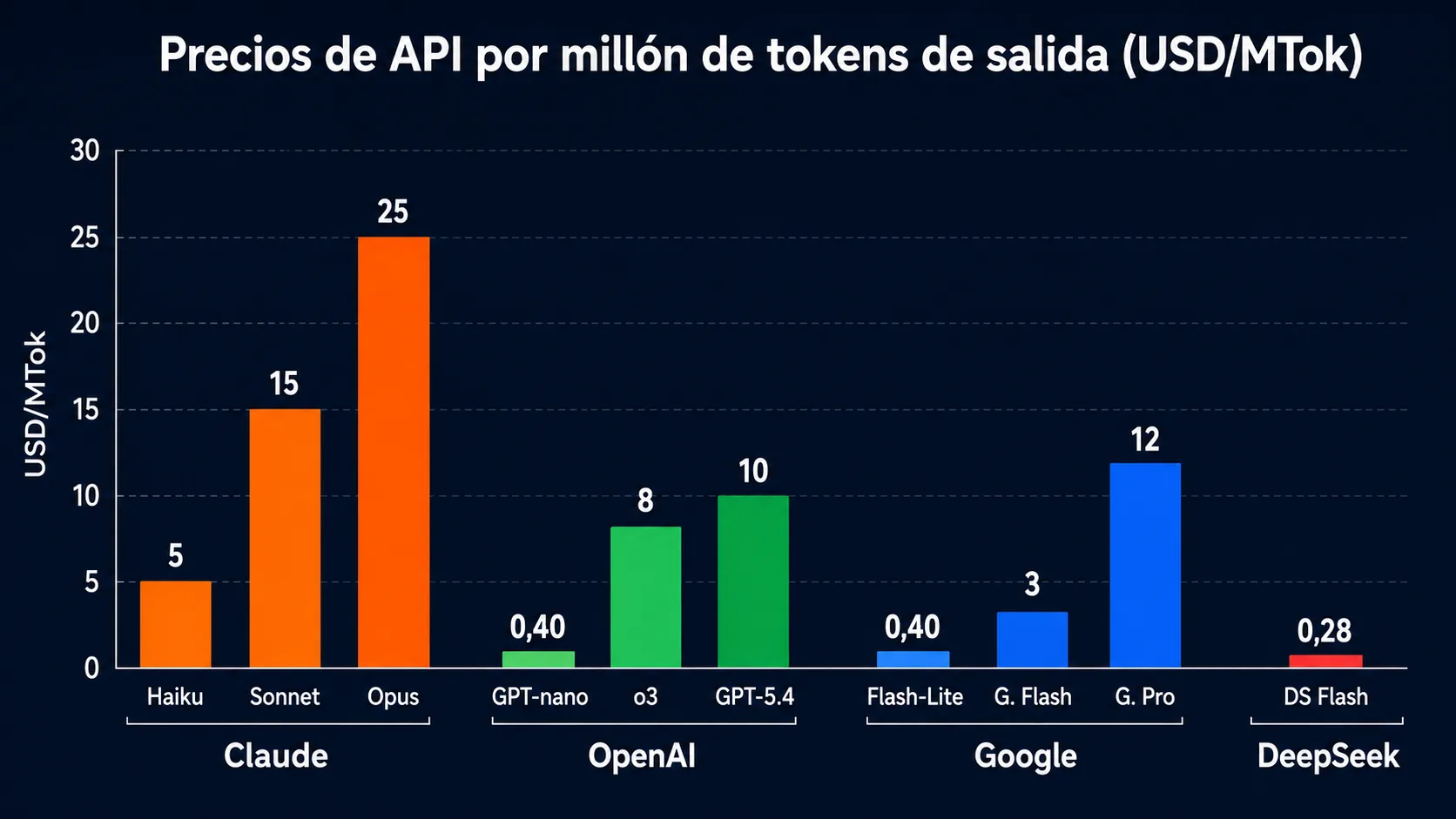
Precios de API en dólares por millón de tokens (MTok). Fuente: páginas oficiales de cada proveedor.
| Modelo | Proveedor | Input ($/MTok) | Output ($/MTok) | Contexto | Mejor para |
|---|---|---|---|---|---|
| Claude Haiku 4.5 | Anthropic | $1,00 | $5,00 | 200K | Tareas rápidas, clasificación, routing |
| Claude Sonnet 4.6 | Anthropic | $3,00 | $15,00 | 1M | Producción, agentes complejos, código |
| Claude Opus 4.7 | Anthropic | $5,00 | $25,00 | 1M | Razonamiento frontier, análisis crítico |
| GPT-4.1-nano | OpenAI | $0,10 | $0,40 | 1M | Volumen alto, coste mínimo |
| OpenAI o3 | OpenAI | $2,00 | $8,00 | 200K | Razonamiento matemático y científico |
| GPT-5.4 | OpenAI | $1,25 | $10,00 | 1M | Casos de uso generales con OpenAI |
| GPT-5.5 | OpenAI | $5,00 | $30,00 | 1M | Modelo insignia 2026: coding agéntico y razonamiento |
| GPT-5.5 Pro | OpenAI | $30,00 | $180,00 | 1M | Razonamiento extremo en problemas de alta dificultad |
| Gemini Flash-Lite | $0,10 | $0,40 | 1M | Alta velocidad, bajo coste, contexto largo | |
| Gemini 3 Flash | $0,50 | $3,00 | 1M | Producción con contexto largo y coste bajo | |
| Gemini 3.5 Flash | $1,50 | $9,00 | 1M | Nuevo modelo por defecto 2026: agentes y multimodal | |
| Gemini 3.1 Pro | $2,00 | $12,00 | 2M | Integración con Google Workspace, multimodal | |
| DeepSeek V4 Flash | DeepSeek | $0,14 | $0,28 | 1M | Alternativa económica a modelos cloud |
| DeepSeek V4 Pro | DeepSeek | $1,74 | $3,48 | 1M | Razonamiento avanzado a coste reducido |
| Mistral Small 4 | Mistral AI | $0,15 | $0,60 | 32K | Open weight, autoalojado, bajo coste |
| Mistral Large 3 | Mistral AI | $0,50 | $1,50 | 128K | Tareas complejas con modelo europeo |
| Llama 4 Maverick | Meta (open weight) | Autoalojado | Autoalojado | 128K | Privacidad total, sin coste por token |
| Llama 4 Scout | Meta (open weight) | Autoalojado | Autoalojado | 10M | Contexto extremadamente largo, on-premise |
Claude — el modelo de referencia para agentes complejos
La familia Claude destaca por su capacidad de seguir instrucciones largas y complejas, su ventana de contexto de 1M de tokens en los modelos principales y su soporte nativo para llamadas a herramientas estructuradas. Es el modelo más utilizado en agentes de producción que requieren razonamiento multi-paso y fiabilidad alta a mayo de 2026.
ChatGPT / GPT — el ecosistema más amplio de herramientas
OpenAI ofrece el ecosistema de integraciones más amplio del mercado: function calling nativo desde GPT-3.5, Assistants API con memoria y archivos gestionados, y el modelo de razonamiento o3 para problemas que requieren múltiples pasos de verificación lógica.
Gemini — contexto masivo e integración con Google Workspace
La familia Gemini de Google combina ventanas de contexto de 1M de tokens con capacidades multimodales nativas y una integración profunda con el ecosistema de Google: Drive, Docs, Gmail, Search. La opción natural cuando el agente necesita razonar sobre datos de Google o procesar archivos multimedia.
Modelos open source: privacidad total y coste cero por token
DeepSeek, Llama y Mistral son modelos de pesos abiertos que puedes ejecutar en tu propia infraestructura. Sin coste por token, sin enviar datos a terceros y con la posibilidad de hacer fine-tuning para tu caso de uso específico. La contrapartida es el coste de infraestructura y la mayor complejidad operativa.
Como elegir el modelo correcto para tu agente
Cinco criterios concretos para evitar elegir el modelo equivocado y reescribir la arquitectura cuando el coste o la calidad no se ajustan a lo esperado.
Estima el coste total, no el precio por llamada
Multiplica el precio por token por el número estimado de llamadas por tarea y por el volumen mensual. Un agente que ejecuta 10 pasos con Claude Sonnet cuesta 10x más por tarea que un chatbot de una sola llamada. Usa la calculadora de costes para obtener cifras reales antes de comprometerte con un modelo.
Asigna el modelo según la complejidad del paso
No todos los pasos de un agente requieren el modelo frontier. El paso de clasificación de intención usa Haiku o Flash-Lite. El paso de extracción estructurada usa Sonnet o Flash. Solo el paso de razonamiento final usa Opus o Pro. Esta estrategia de tiers reduce el coste entre un 40% y un 70% sin penalizar la calidad del resultado.
Evalúa el requisito de privacidad de los datos
Si tu agente procesa datos médicos, contratos confidenciales o información financiera sensible, necesitas ejecución local con Llama 4, Mistral o DeepSeek descargado, servido con Ollama en tu propia infraestructura. Los modelos cloud (Claude, GPT, Gemini) envían los datos a los servidores del proveedor, lo que puede incumplir GDPR u otras normativas.
Comprueba el contexto que realmente necesitas
Si tu agente analiza documentos de más de 200 páginas o mantiene conversaciones muy largas, necesitas 1M de tokens de contexto: Claude Sonnet 4.6, Gemini Flash o Llama Scout. Para la mayoría de agentes de soporte, ventas o automatización de tareas, 200K tokens son más que suficientes y a menor coste.
Verifica el soporte de herramientas del modelo
No todos los modelos tienen el mismo soporte para llamadas a herramientas (function calling). Claude y GPT tienen implementaciones muy maduras con esquemas JSON estrictos y manejo de errores robusto. Los modelos open source varían: Llama 4 y Mistral Large tienen soporte sólido; modelos más pequeños pueden necesitar prompting adicional para estructurar correctamente las llamadas a herramientas.
Prioriza modelos con prompt caching si el contexto se repite
Si las instrucciones del sistema de tu agente son largas y no cambian entre llamadas (lo habitual), el prompt caching de Claude y Gemini puede reducir el coste de los tokens de entrada entre un 80% y un 90%. Esto es especialmente relevante en agentes con instrucciones detalladas de 5.000 a 20.000 tokens que se repiten en cada paso del bucle de razonamiento.
- Agente de producción con razonamiento complejo y presupuesto moderado → Claude Sonnet 4.6
- Tareas de clasificación, routing o validación de alto volumen → Claude Haiku 4.5 o Gemini Flash-Lite
- Análisis matemático, científico o lógico muy riguroso → OpenAI o3
- Integración con Google Drive, Docs o Gmail → Gemini 3.1 Pro
- Contexto de más de 200K tokens a bajo coste → Gemini 3.5 Flash
- Privacidad total, datos on-premise → Llama 4 Maverick via Ollama
- Datos en Europa, cumplimiento GDPR → Mistral Large 3
- Rendimiento frontier a precio reducido → DeepSeek V4 Pro