- La imagen oficial es
ollama/ollamaen Docker Hub. Para AMD usaollama/ollama:rocm. No hay imagen para Windows containers. - Los modelos se guardan en
/root/.ollama/modelsdentro del contenedor. Monta siempre un volumen en esa ruta para que persistan entre reinicios. - Para GPU NVIDIA: instala el NVIDIA Container Toolkit en el host y añade
--gpus=allal comando docker run. - Para que otros contenedores accedan a la API, configura
OLLAMA_HOST=0.0.0.0y usa el nombre del servicio como hostname en docker-compose. - Nunca expongas el puerto 11434 en internet sin autenticación. Ollama no tiene control de acceso nativo; usa un proxy inverso.
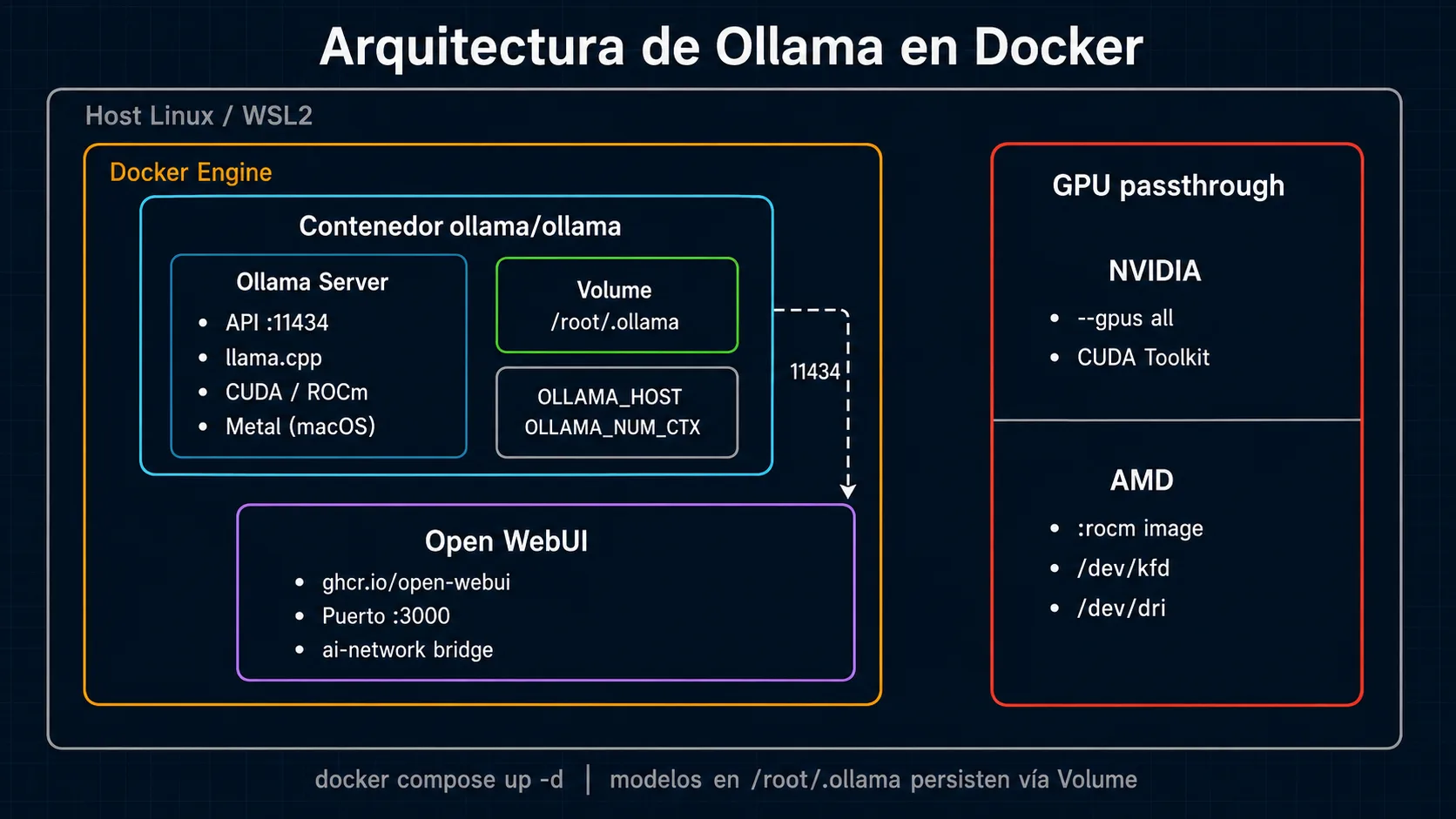
La imagen oficial de Ollama en Docker Hub
Ollama publica imágenes Docker oficiales en
hub.docker.com/r/ollama/ollama .
La imagen base incluye la última versión estable de Ollama con soporte para
CPU y GPU NVIDIA (CUDA). Para GPU AMD se usa la variante :rocm.
ollama/ollama se actualiza con cada nueva versión.
Consulta los tags disponibles en Docker Hub o en la
documentación oficial de Docker .
| Imagen | GPU soportada | Cuando usarla |
|---|---|---|
ollama/ollama:latest |
NVIDIA CUDA + CPU | Uso general con NVIDIA o solo CPU |
ollama/ollama:rocm |
AMD ROCm + CPU | GPUs AMD (RX 6000+, Instinct) |
ollama/ollama:0.x.y |
NVIDIA CUDA + CPU | Versión específica para entornos fijos |
Inicio rápido: Ollama en Docker en tres comandos
El flujo mínimo para tener Ollama funcionando en Docker: arrancar el contenedor, descargar un modelo y hacer la primera llamada a la API.
Paso 1: arrancar el contenedor
docker run -d \
--name ollama \
-v ollama:/root/.ollama \
-p 11434:11434 \
ollama/ollamaPaso 2: descargar un modelo
docker exec -it ollama ollama pull llama3.2:3bPaso 3: verificar que la API responde
curl http://localhost:11434/api/generate \
-H "Content-Type: application/json" \
-d '{"model":"llama3.2:3b","prompt":"Hola","stream":false}'
El flag -v ollama:/root/.ollama crea un volumen Docker con nombre
ollama que persiste los modelos descargados. Sin este flag, los
modelos se perderán cada vez que elimines el contenedor. El flag -p 11434:11434
expone la API REST en el puerto 11434 del host.
GPU passthrough NVIDIA: NVIDIA Container Toolkit
Para usar la GPU NVIDIA con Ollama en Docker necesitas instalar el NVIDIA Container Toolkit en el host. Este toolkit actua como puente entre Docker y los drivers de NVIDIA, sin modificar la imagen base de Ollama.
Requisitos previos
- Linux (Ubuntu 20.04+, Debian 11+, RHEL 8+). En Windows usar WSL2.
- Driver NVIDIA instalado en el host (versión 525+ para CUDA 12.x).
- Docker Engine 20.10+ o Docker Desktop 4.x.
Instalación del NVIDIA Container Toolkit
# Añadir el repositorio de NVIDIA
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | \
sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# Instalar
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
# Configurar Docker para usar el runtime de NVIDIA
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
# Verificar que Docker puede ver la GPU
docker run --rm --gpus all nvidia/cuda:12.3-base nvidia-smiArrancar Ollama con GPU NVIDIA
# Con acceso a todas las GPUs del sistema
docker run -d \
--name ollama \
--gpus all \
-v ollama:/root/.ollama \
-p 11434:11434 \
ollama/ollama
# Solo con la GPU 0 (en sistemas con varias GPUs)
docker run -d \
--name ollama \
--gpus '"device=0"' \
-v ollama:/root/.ollama \
-p 11434:11434 \
ollama/ollama
# Verificar que Ollama detecta la GPU
docker exec -it ollama ollama run llama3.2:3b "Di hola" 2>&1 | head -20
Para confirmar que Ollama está usando la GPU, observa la salida al cargar un
modelo: deberá indicar el nombre de la GPU y la VRAM disponible. Si ves
no GPU detected, revisa que el NVIDIA Container Toolkit esté
instalado correctamente y que los drivers del host estén actualizados.
GPU AMD con ROCm
Ollama soporta GPUs AMD usando la plataforma ROCm. La imagen
ollama/ollama:rocm incluye los binarios ROCm necesarios y
requiere pasar los dispositivos de la GPU al contenedor manualmente.
Requisitos
- GPU AMD compatible con ROCm: RX 6000 (RDNA 2), RX 7000 (RDNA 3), RX 9000 (RDNA 4) o Instinct.
- Driver AMDGPU instalado en el host.
- El usuario que ejecuta Docker debe pertenecer al grupo
videoyrender.
Arrancar Ollama con GPU AMD
# Imagen ROCm con acceso a los dispositivos necesarios
docker run -d \
--name ollama-amd \
--device /dev/kfd \
--device /dev/dri \
-v ollama:/root/.ollama \
-p 11434:11434 \
ollama/ollama:rocm
# Si tienes varias GPUs y quieres usar solo una especifica
docker run -d \
--name ollama-amd \
--device /dev/kfd \
--device /dev/dri/renderD128 \
-v ollama:/root/.ollama \
-p 11434:11434 \
-e HSA_OVERRIDE_GFX_VERSION=10.3.0 \
ollama/ollama:rocm
La variable HSA_OVERRIDE_GFX_VERSION puede ser necesaria
para GPUs cuya arquitectura no está completamente soportada por ROCm.
Por ejemplo, la RX 6700 XT usa 10.3.0, la RX 7900 XTX usa
11.0.0. Consulta la
documentación oficial de Ollama
para la tabla de compatibilidad actualizada.
Volúmenes: persistir modelos entre reinicios
Sin un volumen configurado, los modelos descargados se pierden cuando el contenedor se elimina. Un volumen Docker con nombre o un bind mount son las dos opciones para mantener los datos persistentes.
Volumen con nombre (recomendado)
La forma más sencilla y portable. Docker gestiona el volumen automáticamente.
# Crear el volumen (opcional, se crea automáticamente si no existe)
docker volume create ollama-models
# Arrancar el contenedor con el volumen
docker run -d \
--name ollama \
-v ollama-models:/root/.ollama \
-p 11434:11434 \
ollama/ollama
# Ver donde esta el volumen en el host
docker volume inspect ollama-modelsBind mount (ruta del host)
Útil cuando quieres tener los modelos en una ruta específica del host (por ejemplo, en un disco con más espacio o un NAS montado).
# Preparar la carpeta en el host
mkdir -p /data/ollama-models
# Arrancar con bind mount
docker run -d \
--name ollama \
-v /data/ollama-models:/root/.ollama \
-p 11434:11434 \
ollama/ollama
# En Linux el propietario debe ser uid 0 (root dentro del contenedor)
# La imagen de Ollama corre como root por defecto, asi que no hay problema.Ubicación de los modelos dentro del contenedor
Variables de entorno de Ollama
Ollama se configura a traves de variables de entorno. Estas se pasan al
contenedor con el flag -e o en la sección environment
del docker-compose.
| Variable | Defecto | Descripción |
|---|---|---|
OLLAMA_HOST |
127.0.0.1:11434 |
IP y puerto en que escucha la API. Usar 0.0.0.0 para aceptar conexiones externas al contenedor. |
OLLAMA_MODELS |
/root/.ollama/models |
Ruta donde se almacenan los modelos descargados dentro del contenedor. |
OLLAMA_NUM_PARALLEL |
1 |
Número de peticiones de inferencia paralelas. Aumentar si tienes varios clientes simultáneos. |
OLLAMA_MAX_LOADED_MODELS |
1 |
Número máximo de modelos cargados en VRAM al mismo tiempo. |
OLLAMA_NUM_CTX |
2048 |
Tamaño de contexto por defecto para todos los modelos. Sobreescribible por petición. |
OLLAMA_KEEP_ALIVE |
5m |
Tiempo que un modelo permanece cargado en memoria sin peticiones. Usar -1 para mantenerlo siempre cargado. |
OLLAMA_DEBUG |
false |
Habilita logs detallados de depuración. Útil para diagnosticar problemas de carga de modelos. |
OLLAMA_ORIGINS |
* |
Orígenes CORS permitidos. Restringir en producción a los dominios concretos de tu aplicación. |
Ejemplo con múltiples variables
docker run -d \
--name ollama \
--gpus all \
-v ollama:/root/.ollama \
-p 11434:11434 \
-e OLLAMA_HOST=0.0.0.0:11434 \
-e OLLAMA_NUM_PARALLEL=4 \
-e OLLAMA_MAX_LOADED_MODELS=2 \
-e OLLAMA_KEEP_ALIVE=10m \
-e OLLAMA_NUM_CTX=4096 \
ollama/ollamaDocker Compose: Ollama con un fichero declarativo
Docker Compose permite definir toda la configuración en un fichero YAML versionable. Es la forma recomendada para entornos de desarrollo compartido y para que el setup sea reproducible entre maquinas.
docker-compose.yml básico con GPU NVIDIA
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
environment:
- OLLAMA_HOST=0.0.0.0:11434
- OLLAMA_NUM_PARALLEL=2
- OLLAMA_KEEP_ALIVE=10m
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
volumes:
ollama_data:
Guarda este fichero como docker-compose.yml y ejecuta
docker compose up -d para arrancar el servicio en segundo plano.
Para detenerlo usa docker compose down. Los modelos en el volumen
ollama_data persisten aunque uses docker compose down -v
solo si no eliminas el volumen explícitamente.
docker-compose.yml para GPU AMD (ROCm)
services:
ollama:
image: ollama/ollama:rocm
container_name: ollama
restart: unless-stopped
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
devices:
- /dev/kfd
- /dev/dri
environment:
- OLLAMA_HOST=0.0.0.0:11434
- OLLAMA_KEEP_ALIVE=10m
# Descomentar para GPUs que necesiten override de version
# - HSA_OVERRIDE_GFX_VERSION=11.0.0
volumes:
ollama_data:Comandos de gestión con docker compose
# Arrancar en segundo plano
docker compose up -d
# Ver logs en tiempo real
docker compose logs -f ollama
# Descargar un modelo
docker compose exec ollama ollama pull llama3.2
# Listar modelos instalados
docker compose exec ollama ollama list
# Reiniciar el servicio
docker compose restart ollama
# Detener sin eliminar el volumen
docker compose down
# Ver el uso de VRAM de la GPU
docker compose exec ollama nvidia-smiDocker Compose con Open WebUI
Open WebUI es la interfaz gráfica de referencia para Ollama: chat estilo ChatGPT, gestión de modelos, historial de conversaciones y herramientas RAG. Este docker-compose levanta ambos servicios con un solo comando.
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
volumes:
- ollama_data:/root/.ollama
environment:
- OLLAMA_HOST=0.0.0.0:11434
- OLLAMA_NUM_PARALLEL=2
- OLLAMA_KEEP_ALIVE=10m
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
networks:
- ai-network
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
restart: unless-stopped
ports:
- "3000:8080"
volumes:
- webui_data:/app/backend/data
environment:
- OLLAMA_BASE_URL=http://ollama:11434
- WEBUI_AUTH=true
- ENABLE_SIGNUP=false
- WEBUI_SECRET_KEY=cambia-esto-por-un-valor-aleatorio-largo
depends_on:
- ollama
networks:
- ai-network
networks:
ai-network:
driver: bridge
volumes:
ollama_data:
webui_data:
Con este fichero, Ollama y Open WebUI se comunican a través de la red
interna ai-network usando el nombre de servicio como hostname
(http://ollama:11434). El puerto 11434 de Ollama no
se expone al host en esta configuración: solo Open WebUI puede
acceder a la API de Ollama, lo que es más seguro.
Open WebUI estará disponible en http://localhost:3000. El
primer usuario que se registre se convierte en administrador. Activa
ENABLE_SIGNUP=false después del primer registro para evitar
que otros usuarios creen cuentas.
Uso de Ollama en producción con Docker
Consideraciones de seguridad, rendimiento y disponibilidad para entornos de producción donde Ollama atiende peticiones reales de usuarios o pipelines automatizados.
Proxy inverso con autenticación básica (nginx)
Ollama no tiene autenticación nativa. Si necesitas exponerlo fuera de la red local, pon un proxy inverso delante:
# nginx.conf (fragmento relevante)
server {
listen 443 ssl;
server_name ollama.tudominio.com;
ssl_certificate /etc/letsencrypt/live/ollama.tudominio.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/ollama.tudominio.com/privkey.pem;
auth_basic "Ollama API";
auth_basic_user_file /etc/nginx/.htpasswd;
location / {
proxy_pass http://ollama:11434;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_read_timeout 300s; # timeout largo para inferencias lentas
proxy_buffering off; # necesario para streaming
}
}docker-compose.yml de producción completo
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: always
volumes:
- ollama_data:/root/.ollama
environment:
- OLLAMA_HOST=0.0.0.0:11434
- OLLAMA_NUM_PARALLEL=4
- OLLAMA_MAX_LOADED_MODELS=2
- OLLAMA_KEEP_ALIVE=-1
- OLLAMA_NUM_CTX=4096
- OLLAMA_ORIGINS=https://tuapp.com
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
networks:
- internal
# Sin exposicion directa de puertos al exterior
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:11434/"]
interval: 30s
timeout: 10s
retries: 3
nginx:
image: nginx:alpine
container_name: nginx-proxy
restart: always
ports:
- "443:443"
- "80:80"
volumes:
- ./nginx.conf:/etc/nginx/conf.d/default.conf:ro
- /etc/letsencrypt:/etc/letsencrypt:ro
networks:
- internal
- external
depends_on:
- ollama
networks:
internal:
driver: bridge
internal: true # solo accesible desde los contenedores, no desde el host
external:
driver: bridge
volumes:
ollama_data:Descarga automática de modelos al arrancar
# Script de inicializacion: init-models.sh
#!/bin/bash
set -e
echo "Esperando a que Ollama esté listo..."
until curl -sf http://ollama:11434/ > /dev/null; do
sleep 2
done
echo "Descargando modelos..."
curl -X POST http://ollama:11434/api/pull \
-H "Content-Type: application/json" \
-d '{"model": "llama3.2:3b"}'
curl -X POST http://ollama:11434/api/pull \
-H "Content-Type: application/json" \
-d '{"model": "nomic-embed-text"}'
echo "Modelos listos."
Puedes ejecutar este script como un contenedor init en
docker-compose usando depends_on con condition
service_healthy, o como un cron job que verifica periódicamente
que los modelos necesarios estén disponibles.
Preguntas frecuentes sobre Ollama en Docker
Necesitas instalar el NVIDIA Container Toolkit en el host y arrancar el contenedor con --gpus=all. En docker-compose, usa la sección deploy.resources.reservations.devices con driver nvidia y capabilities ["gpu"]. Verifica la instalación con docker run --rm --gpus all nvidia/cuda:12.3-base nvidia-smi.
Ollama guarda los modelos en /root/.ollama/models dentro del contenedor. Para persistirlos, monta un volumen Docker en esa ruta: -v ollama:/root/.ollama. Sin este volumen, los modelos se pierden cuando eliminas el contenedor. Un modelo de 3B cuantizado ocupa aproximadamente 2 GB; uno de 70B sin cuantizar puede superar los 40 GB.
La imagen base ollama/ollama:latest incluye soporte para NVIDIA CUDA y CPU. La imagen ollama/ollama:rocm incluye soporte para GPUs AMD usando la plataforma ROCm. Si tienes una GPU AMD (RX 6000, RX 7000, RX 9000 o Instinct) usa la versión :rocm. Para NVIDIA o CPU usa la imagen base. No existe una imagen que soporte ambas GPUs simultáneamente.
En docker-compose, los servicios se comunican por nombre de servicio. Si tu servicio se llama ollama, la URL de la API desde otro contenedor en la misma red es http://ollama:11434. Asegúrate de que ambos servicios están en la misma red Docker y de que Ollama tenga configurado OLLAMA_HOST=0.0.0.0:11434 para escuchar en todas las interfaces.
Sí. Ollama funciona en modo CPU sin ningún cambio en la imagen. Simplemente omite el flag --gpus y la sección deploy en docker-compose. La inferencia será más lenta: en CPU puro, un modelo de 3B genera entre 2 y 10 tokens por segundo dependiendo del hardware. Los modelos de 1B-3B cuantizados (Qwen 2.5 1.5B, Llama 3.2 1B) son los más adecuados para entornos sin GPU.
Tienes dos opciones: ejecutar directamente en el contenedor con docker exec -it ollama ollama pull llama3.2, o usar la API REST desde fuera del contenedor con curl -X POST http://localhost:11434/api/pull -d '{"model": "llama3.2"}'. La segunda opción es más adecuada para scripts de automatización y admite seguimiento del progreso a través del streaming de la respuesta.