Este glosario recoge los 47 términos que aparecen con más frecuencia cuando alguien empieza a trabajar con agentes de inteligencia artificial. Cada vez que un tutorial menciona RAG, un artículo habla de embeddings o una documentación te pide configurar guardrails, este es el lugar donde encontrar la definición precisa sin tener que buscar en cinco sitios distintos. Si estás empezando, te recomendamos leer primero qué es un agente de IA para tener el contexto global antes de profundizar en la terminología.
Los términos están organizados alfabéticamente y agrupados por letra inicial. Cada entrada incluye el nombre del concepto, una definición de entre 50 y 80 palabras y, cuando existe una guía dedicada en este sitio, un enlace a ella. Algunos términos llevan una etiqueta fundamental para indicar que son conceptos base que aparecen en casi todos los proyectos de agentes.
A
Agentic AI fundamental
Categoría de sistemas de inteligencia artificial que actúan de forma autónoma para completar objetivos complejos de varios pasos. A diferencia de un modelo de lenguaje que solo responde a una pregunta, un sistema agéntico planifica, usa herramientas, observa el resultado de sus acciones y se autocorrige en un bucle continuo hasta alcanzar la meta, sin requerir supervisión humana en cada iteración. Es el paradigma dominante en aplicaciones de IA empresarial en 2026.
API (Application Programming Interface) fundamental
Interfaz que permite a dos sistemas de software comunicarse entre sí mediante llamadas estandarizadas. En el contexto de agentes de IA, las APIs son las "manos" del agente: le permiten acceder a servicios externos como bases de datos, sistemas de pagos, plataformas de email o cualquier herramienta con una interfaz programática. La mayoría de los LLMs también se consumen a través de una API REST.
Autonomía fundamental
Grado en que un agente toma decisiones y ejecuta acciones sin intervención humana. Va desde sugerencias que requieren aprobación explícita en cada paso hasta la ejecución totalmente automática de flujos de trabajo completos. Cuanta más autonomía tenga un agente, mayor es la importancia de contar con guardrails robustos, ya que los errores se propagan sin que nadie los intercepte.
B
Bucle del agente (agentic loop) fundamental
Ciclo percibir / razonar / actuar / observar que un agente repite de forma continua hasta cumplir su objetivo. En cada iteración el agente recibe información del entorno, decide qué hacer, ejecuta una acción —a menudo mediante una herramienta— y evalúa el resultado antes de comenzar la siguiente vuelta. Es el corazón de todo sistema agéntico y lo que lo distingue de una llamada aislada a un LLM.
C
Chain of Thought (CoT)
Técnica de prompting que le pide al LLM mostrar su razonamiento paso a paso antes de dar la respuesta final. En lugar de saltar directamente a la conclusión, el modelo "piensa en voz alta": descompone el problema, evalúa opciones y llega a la respuesta de forma trazable. Mejora significativamente la precisión en tareas matemáticas, lógicas y de planificación. Es la base del patrón ReAct y de la mayoría de arquitecturas de agentes que necesitan razonamiento complejo.
Computer Use 2026
Capacidad de un agente de operar un ordenador como lo haría un humano: ver la pantalla, mover el cursor, hacer clic y teclear texto. Claude y otros modelos frontera ofrecen esta funcionalidad en 2026, lo que permite automatizar cualquier aplicación de escritorio o web aunque no tenga API. Amplía radicalmente el conjunto de tareas que un agente puede resolver sin necesidad de integraciones a medida.
Context engineering (ingeniería de contexto) avanzado
Disciplina de decidir qué información entra en la ventana de contexto del modelo en cada momento: instrucciones del sistema, datos recuperados, historial de conversación, resultados de herramientas y memoria. A diferencia del prompt engineering clásico, se ocupa del flujo dinámico de información a lo largo de todo el ciclo del agente. Una buena ingeniería de contexto mejora la calidad de las respuestas, reduce costes de tokens y evita que el modelo se pierda en información irrelevante.
Context Window fundamental
Cantidad máxima de tokens que un LLM puede procesar en una sola llamada, sumando el prompt de entrada y la respuesta generada. Define cuánta información puede "ver" el modelo de una vez: instrucciones del sistema, historial de conversación, documentos recuperados y resultado de herramientas. Los modelos actuales tienen ventanas de entre 32 K y 1 M de tokens. Una ventana pequeña obliga a usar estrategias de memoria externa como RAG para proyectos con mucho contexto.
Cuantización (quantization) técnico
Técnica que reduce la precisión numérica de los pesos de un modelo —por ejemplo, de 16 bits a 4 bits— para que ocupe menos memoria y pueda ejecutarse en hardware modesto. Permite correr LLMs de forma local en GPUs de consumo o incluso en CPU. Formatos como GGUF y herramientas como Ollama o LM Studio se apoyan en la cuantización para hacer accesible la inferencia local sin sacrificar demasiada calidad.
D
Destilación (distillation) técnico
Proceso de entrenar un modelo pequeño para que imite el comportamiento de uno grande, conservando gran parte de su capacidad con un coste de inferencia muy inferior. El modelo grande actúa como "profesor" generando datos de entrenamiento o señales de supervisión. La destilación es clave en el desarrollo de modelos ligeros que pueden desplegarse en dispositivos con recursos limitados manteniendo una calidad razonable.
E
Embedding fundamental
Representación numérica de un texto (o imagen, audio, etc.) como un vector de cientos o miles de dimensiones. Los textos con significado similar producen vectores cercanos en ese espacio matemático, lo que permite buscar por similitud semántica en lugar de por coincidencia exacta de palabras. Los embeddings son la pieza clave que hace funcionar la búsqueda semántica, la memoria de largo plazo de los agentes y el sistema RAG para recuperar documentos relevantes.
Evaluación (evals) técnico
Medición sistemática de la calidad de un modelo o agente mediante conjuntos de pruebas y métricas definidas. Las evals permiten cuantificar si un agente responde correctamente, si sigue las instrucciones, si produce alucinaciones y si mantiene su rendimiento tras cambios en el sistema prompt o el modelo base. Son imprescindibles antes de poner un agente en producción y para detectar regresiones durante el ciclo de desarrollo.
F
Few-shot learning
Técnica en la que se incluyen ejemplos de entrada y salida directamente dentro del prompt para enseñarle al LLM el formato o estilo de respuesta esperado, sin necesidad de reentrenar el modelo. Si incluyes tres pares de ejemplo (pregunta / respuesta ideal) antes de tu pregunta real, el modelo imita ese patrón. Es más efectivo que dar instrucciones abstractas y es una de las herramientas fundamentales del prompt engineering para adaptar comportamientos de LLMs en producción.
Fine-tuning
Proceso de reentrenar un modelo preentrenado con un conjunto de datos propio para especializarlo en una tarea concreta o en un estilo específico. A diferencia del prompting, el fine-tuning modifica los pesos del modelo, lo que permite resultados más consistentes con menos tokens en el prompt. Requiere datos etiquetados de calidad, coste computacional y conocimiento técnico. Para la mayoría de casos de uso empresarial, RAG + buen prompting da mejores resultados con mucho menor coste.
Function calling / Tool use fundamental
Capacidad de un LLM para invocar funciones o herramientas externas de forma estructurada en lugar de solo generar texto libre. El modelo recibe una lista de herramientas disponibles con su descripción y esquema de parámetros, decide cuál usar y genera una llamada con los argumentos correctos. El resultado de la herramienta se devuelve al modelo para que continúe razonando. Es el mecanismo que convierte un LLM en un agente capaz de actuar en el mundo real.
G
Grounding
Técnica que conecta las salidas del modelo con fuentes de información verificables y actuales, reduciendo la probabilidad de alucinaciones. Un modelo "anclado" (grounded) no inventa datos: basa sus respuestas en documentos recuperados, resultados de búsqueda web o bases de conocimiento propias. El grounding es esencial en aplicaciones donde la precisión factual es crítica, como atención al cliente, soporte técnico o aplicaciones legales y médicas.
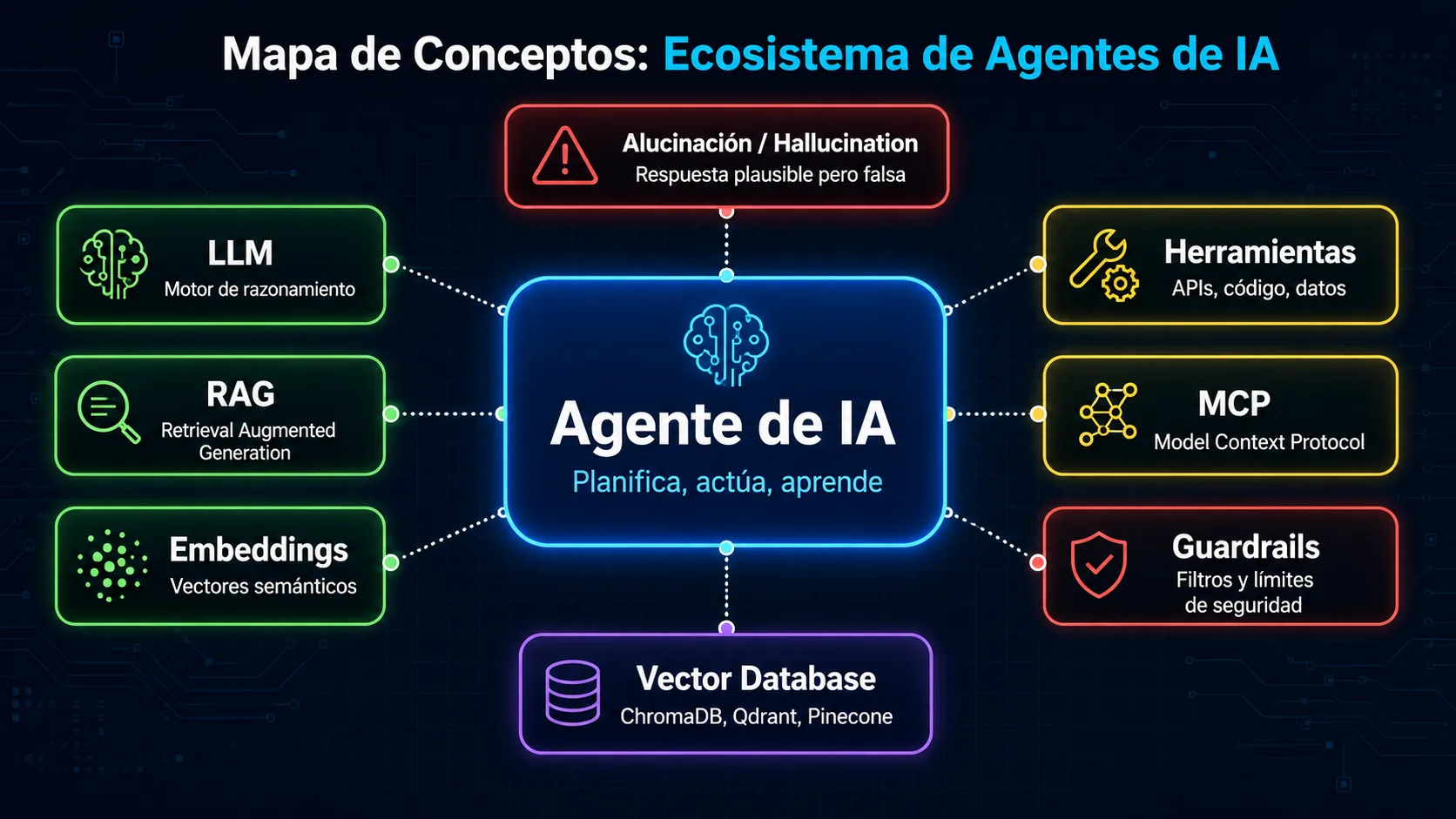
Guardrails
Restricciones de seguridad y comportamiento que se imponen a un agente para limitar lo que puede hacer, decir o acceder. Los guardrails pueden ser instrucciones en el system prompt ("nunca reveles datos personales"), filtros de entrada y salida, validaciones de acciones antes de ejecutarlas o límites de presupuesto de tokens. Son la diferencia entre un agente en producción seguro y uno que puede causar daños accidentales por seguir instrucciones maliciosas o ambiguas.
H
Hallucination (alucinación) fundamental
Fenómeno por el que un LLM genera información falsa con total confianza, sin indicar ninguna incertidumbre. El modelo no "sabe que no sabe": si no tiene la respuesta correcta en sus pesos, puede inventar datos, citas, fechas o hechos con el mismo tono seguro que cuando responde correctamente. Es el riesgo principal en aplicaciones donde la precisión importa. El grounding, el RAG y la verificación de fuentes son las estrategias principales para mitigarlo.
Harness (agent harness) técnico
El armazón de software ejecutable que envuelve al LLM y lo convierte en un agente operativo. Gestiona el bucle del agente, conecta las herramientas, administra el contexto y la memoria, aplica permisos y captura los resultados de cada acción. Está relacionado con el scaffolding, pero el término harness se refiere específicamente al entorno de ejecución completo, no solo a la estructura de código. Claude Code es un ejemplo de harness que añade skills, hooks y permisos sobre el modelo base.
Hooks técnico
Puntos de enganche que permiten ejecutar código propio en momentos concretos del ciclo del agente: antes o después de usar una herramienta, al iniciar una sesión, al recibir una respuesta del modelo, etc. Los hooks son el mecanismo de extensibilidad que permite personalizar el comportamiento del agente sin modificar su núcleo. Claude Code, por ejemplo, expone hooks configurables en su fichero de ajustes para automatizar tareas repetitivas del flujo de desarrollo.
I
Inferencia (inference) técnico
Proceso de generar una respuesta a partir de un modelo ya entrenado. Cada llamada a un LLM es una inferencia: el modelo recibe tokens de entrada, ejecuta sus operaciones matemáticas y produce tokens de salida. Su coste y latencia dependen del tamaño del modelo, el número de tokens procesados y el hardware disponible. Optimizar la inferencia —mediante cuantización, batching o caché de KV— es clave para mantener los costes operativos bajo control en sistemas agénticos con alto volumen de llamadas.
L
LLM (Large Language Model) fundamental
Red neuronal de gran escala entrenada sobre enormes corpus de texto que aprende a predecir el siguiente token en una secuencia. Es el motor de razonamiento y generación de lenguaje de cualquier agente de IA: recibe instrucciones y contexto, razona sobre ellos y decide qué acción tomar o qué texto generar. Claude, GPT, Gemini, Llama y Mistral son ejemplos de LLMs. La calidad del LLM determina en gran medida la capacidad de razonamiento y la fiabilidad del agente completo.
M
MCP (Model Context Protocol) fundamental
Estándar abierto creado por Anthropic para conectar agentes de IA con herramientas, servicios y fuentes de datos externas de forma interoperable. Define cómo exponer recursos (archivos, resultados de consultas), herramientas (funciones invocables) y prompts de forma que cualquier agente compatible pueda usarlos. El objetivo es evitar integraciones a medida para cada par modelo-herramienta: con MCP, una herramienta implementada una vez funciona con todos los agentes que soportan el protocolo.
Memoria (memory) fundamental
Capacidad del agente de retener información entre pasos o entre sesiones. La memoria a corto plazo es la propia ventana de contexto, que el agente pierde al terminar la conversación. La memoria a largo plazo se apoya en bases de datos vectoriales, archivos o registros externos que el agente consulta cuando los necesita. Diseñar bien la estrategia de memoria es uno de los retos principales al construir agentes que deben mantener coherencia a lo largo de tareas prolongadas.
Multi-agent system (sistema multi-agente)
Arquitectura donde varios agentes especializados colaboran para completar una tarea compleja. Cada agente tiene su propio LLM, su conjunto de herramientas y su rol definido. Un agente orquestador coordina el flujo y sintetiza los resultados. Este enfoque permite paralelizar trabajo, especializar cada agente en su dominio y escalar a tareas que un solo agente no puede manejar eficientemente. Frameworks como CrewAI y LangGraph están diseñados específicamente para construir estos sistemas.
Multimodal 2026
Modelo capaz de procesar y combinar varios tipos de entrada y salida: texto, imagen, audio y vídeo. Los modelos frontera de 2026 son multimodales por defecto, lo que permite a los agentes analizar capturas de pantalla, transcribir audio, describir imágenes o generar contenido en distintos formatos dentro del mismo flujo. Esta capacidad es la base de funcionalidades como Computer Use o la monitorización visual de interfaces.
O
Orquestación (orchestration) avanzado
Coordinación de varios agentes, pasos o herramientas para resolver una tarea compleja. El orquestador decide qué componente actúa en cada momento, cómo fluye la información entre ellos y cuándo se considera que el objetivo está cumplido. Puede implementarse como un agente LLM con capacidad de delegar o como un flujo de trabajo codificado. Frameworks como LangGraph o CrewAI proporcionan primitivas de orquestación para construir estos sistemas de forma estructurada.
P
Inyección de prompt (prompt injection) seguridad
Ataque en el que se insertan instrucciones maliciosas dentro de los datos que procesa el agente —una página web, un documento, un correo electrónico— para alterar su comportamiento y hacerle ignorar sus instrucciones originales. Es el principal riesgo de seguridad de los agentes con acceso a contenido externo, ya que el modelo puede confundir datos del entorno con instrucciones legítimas. Mitigarlo requiere separación estricta entre instrucciones de sistema y datos de usuario, además de validaciones de salida.
Planificación (planning) avanzado
Fase en la que el agente descompone un objetivo en una secuencia de pasos concretos antes de empezar a ejecutarlos. Un agente que planifica primero comete menos errores de razonamiento que uno que actúa de forma puramente reactiva, ya que puede detectar dependencias entre pasos y anticipar posibles fallos. Técnicas como chain of thought y tree of thought son mecanismos para inducir planificación explícita en los LLMs.
Prompt engineering fundamental
Disciplina de diseñar instrucciones (prompts) para obtener el comportamiento deseado de un LLM. Incluye técnicas como few-shot learning (dar ejemplos), chain of thought (pedir razonamiento explícito), role prompting (asignar un rol al modelo) e instrucciones negativas (decirle al modelo qué no haga). En agentes, el system prompt es la pieza crítica que define personalidad, límites, herramientas disponibles y formato de salida. Un buen prompt puede valer más que cambiar de modelo.
R
RAG (Retrieval Augmented Generation) fundamental
Arquitectura que combina recuperación de información con generación de texto. Antes de que el LLM responda, el sistema busca en una base de conocimiento (documentos, PDFs, una web entera) los fragmentos más relevantes para la pregunta y los incluye en el contexto del modelo. Así el modelo responde con información actualizada y específica, no solo con lo que aprendió durante el entrenamiento. Es la solución estándar para reducir alucinaciones en dominios especializados y para dar acceso al modelo a información propia de la empresa.
Razonamiento (modelos de razonamiento) 2026
Familia de modelos que dedican cómputo adicional a "pensar" paso a paso antes de emitir su respuesta, mejorando notablemente tareas complejas de lógica, matemáticas y código. En lugar de generar texto de inmediato, el modelo explora caminos de razonamiento internos antes de comprometerse con una respuesta. En 2026, o3 de OpenAI, los modos de razonamiento de Claude y las variantes "thinking" de Gemini son los exponentes más destacados de este paradigma.
ReAct (Reasoning + Acting)
Patrón de arquitectura para agentes que intercala ciclos de razonamiento (Thought) y acción (Action / Observation). El agente piensa qué debe hacer, ejecuta una acción con una herramienta, observa el resultado y vuelve a razonar sobre qué hacer a continuación. Este bucle explícito hace que el comportamiento del agente sea más trazable y depurable que generaciones de texto sin estructura. Es el patrón que sigue la mayoría de frameworks de agentes modernos, incluido el Claude Agent SDK.
Retrieval (recuperación)
Paso de un sistema RAG o de memoria de agente que consiste en encontrar los fragmentos de información más relevantes para una consulta. Puede hacerse por búsqueda exacta (palabras clave), búsqueda semántica (similitud de embeddings) o técnicas híbridas que combinan ambas. La calidad del retrieval determina en gran medida la calidad de la respuesta final: si el sistema no recupera el fragmento correcto, el LLM no tiene la información para responder bien aunque sea un modelo excelente.
S
Scaffolding
El código de infraestructura que rodea y sostiene al LLM dentro de un agente: gestión del bucle de ejecución, ensamblado del prompt, llamada a la API del modelo, parseo de la respuesta, invocación de herramientas, almacenamiento en memoria y gestión de errores. El scaffolding es la diferencia entre un LLM y un agente completo. Frameworks como LangChain, CrewAI o el Claude Agent SDK son esencialmente scaffolding empaquetado que evita tener que construir todo esto desde cero.
Semantic search (búsqueda semántica)
Búsqueda que encuentra documentos relevantes por similitud de significado, no por coincidencia exacta de palabras clave. Funciona convirtiendo la consulta y los documentos en embeddings (vectores numéricos) y calculando qué vectores están más cercanos en el espacio matemático. Permite encontrar el párrafo correcto aunque el usuario use sinónimos o formule la pregunta de forma distinta a como está escrito el documento. Es la tecnología que hace posible la memoria de largo plazo en agentes y el RAG eficiente.
Skills 2026
Capacidades reutilizables y empaquetadas que amplían lo que un agente sabe hacer: instrucciones, scripts o flujos que se invocan cuando la situación lo requiere. A diferencia de las herramientas —que conectan con sistemas externos—, los skills encapsulan conocimiento o comportamiento específico del agente. Claude Code, por ejemplo, implementa sus funcionalidades avanzadas como skills invocables mediante comandos de barra, lo que facilita su mantenimiento y extensión por parte del equipo.
Slash command (comando de barra) técnico
Comando que comienza por una barra inclinada (/) y que dispara una acción o skill predefinido dentro de un agente o herramienta de IA. Actúan como atajos rápidos que evitan describir en lenguaje natural una acción compleja: en lugar de explicar qué hacer, el usuario escribe /checkpoint y el agente sabe exactamente qué ejecutar. Son el mecanismo principal de extensión de agentes como Claude Code y muchas plataformas de IA conversacional.
Subagente (subagent) técnico
Agente secundario que otro agente lanza para delegar una subtarea concreta: investigar un tema, revisar código, buscar información o ejecutar una serie de pasos especializados. El subagente trabaja de forma independiente y devuelve solo el resultado al agente principal, manteniendo limpio el contexto de este y permitiendo paralelizar trabajo. Es el patrón que hace posibles los sistemas multi-agente eficientes a gran escala.
System prompt (prompt de sistema) fundamental
Instrucción base, invisible para el usuario final, que define el papel, las reglas y el comportamiento del agente durante toda la conversación. Establece qué herramientas puede usar, qué tono debe mantener, qué información no puede revelar y cómo debe estructurar sus respuestas. Es la pieza más determinante del comportamiento de un agente: un system prompt bien diseñado puede compensar limitaciones del modelo, mientras que uno mal redactado produce comportamientos impredecibles aunque el modelo sea excelente.
T
Temperature (temperatura)
Parámetro que controla la aleatoriedad de las salidas de un LLM durante la generación. Con temperatura 0 el modelo es determinista: siempre elige el token más probable. Con temperatura alta (0.7-1.0) introduce variabilidad, generando respuestas más creativas pero menos predecibles. Para agentes que toman decisiones críticas o generan JSON estructurado se recomienda temperatura 0 o cercana a 0. Para generación creativa de contenido, valores entre 0.5 y 0.9 suelen dar mejores resultados.
Token fundamental
Unidad básica de texto que procesa un LLM. No equivale exactamente a una palabra: en inglés, un token representa aproximadamente tres cuartos de una palabra; en español la relación varía por la morfología más rica del idioma. "Hola" es un token; "Reconocimiento" puede ser dos o tres. El coste de usar una API de LLM se mide en tokens (de entrada y de salida). Gestionar el número de tokens es crítico para controlar costes y no superar la ventana de contexto del modelo.
Tool calling (llamada a herramienta)
Momento específico dentro del bucle de un agente en el que el LLM decide invocar una herramienta externa y genera la llamada con los parámetros correctos. El término distingue el acto de la decisión (el modelo elige usar una herramienta) de la capacidad general (function calling). Un agente puede hacer múltiples tool calls en la misma tarea: buscar en la web, luego ejecutar código con los datos encontrados y finalmente escribir los resultados en una base de datos, todo en una sola sesión sin intervención humana.
V
Vector database (base de datos vectorial) fundamental
Base de datos diseñada y optimizada para almacenar y buscar embeddings de forma eficiente. A diferencia de una base de datos relacional que busca por coincidencia exacta, una vector DB encuentra los vectores más cercanos a una consulta (búsqueda por similitud o ANN: Approximate Nearest Neighbor). Pinecone, Weaviate, Chroma y pgvector son ejemplos. Son la pieza de infraestructura que hace posible la memoria de largo plazo en agentes y los sistemas RAG a escala con millones de documentos.
Vibe coding 2026
Forma de programar en la que el desarrollador describe en lenguaje natural lo que quiere conseguir y deja que un agente de IA escriba, corrija e itere el código por él. El término se popularizó en 2025-2026 con la explosión de agentes de desarrollo como Claude Code, Cursor y Copilot Workspace. Reduce la barrera de entrada para construir software, aunque exige revisar el código generado para garantizar calidad, seguridad y mantenibilidad a largo plazo.
W
Workflow (flujo de trabajo) avanzado
Secuencia de pasos predefinida y determinista que siempre sigue el mismo camino, a diferencia de un agente autónomo que decide su ruta en tiempo real. Los workflows son más predecibles y fáciles de auditar, pero menos flexibles ante situaciones imprevistas. Muchos sistemas reales combinan ambos enfoques: un workflow fijo para las partes críticas del proceso y agentes autónomos para los pasos que requieren adaptación o razonamiento complejo.
Z
Zero-shot
Capacidad de un LLM para realizar una tarea sin haber visto ningún ejemplo de esa tarea en el prompt. El modelo aplica su conocimiento general para inferir qué se espera de él basándose solo en la descripción de la tarea. Contrasta con few-shot (con ejemplos en el prompt) y con fine-tuning (con reentrenamiento). Los LLMs modernos son notablemente buenos en zero-shot para tareas comunes, pero el rendimiento puede mejorar significativamente al añadir ejemplos con few-shot learning en tareas más especializadas.