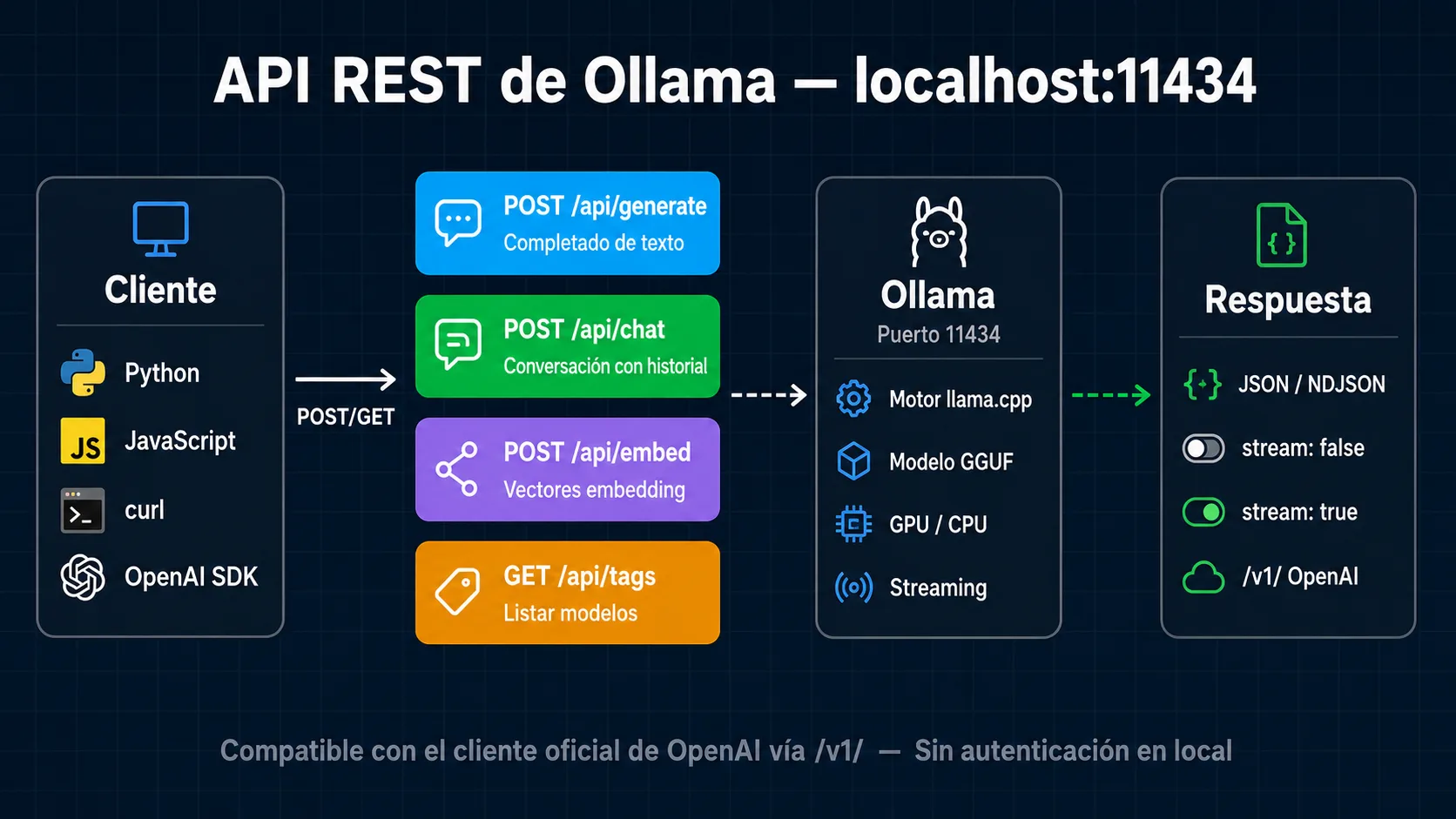
- La API REST de Ollama escucha en
http://localhost:11434por defecto. No requiere autenticación en entornos locales. - Los endpoints principales son /api/generate (texto a texto), /api/chat (conversacional con historial) y /api/embed (vectores).
- Todas las respuestas de generación son streaming por defecto via server-sent events. Añadir
"stream": falsepara respuesta completa en un JSON. - Ollama expone una capa compatible con la API de OpenAI en
/v1/: migra aplicaciones existentes cambiando solo la base URL. - Los parámetros de inferencia (temperature, top_p, num_ctx) se pasan en el objeto
"options"de la petición.
Introducción a la API REST de Ollama
Cuando ejecutas ollama serve (o cuando Ollama arranca automáticamente
al instalar el cliente de escritorio), se levanta un servidor HTTP en
http://localhost:11434. Este servidor expone una API
REST que cualquier aplicación puede consumir: desde un script Python sencillo hasta
una aplicación web completa con backend Node.js o un pipeline de datos en producción.
La API no requiere autenticación por defecto cuando se usa en local. Si necesitas
exponerla en red (por ejemplo, para que otros contenedores Docker la consuman),
configura la variable de entorno OLLAMA_HOST=0.0.0.0:11434. Para
entornos de producción expuestos a internet, coloca un proxy inverso (nginx,
Caddy) delante con autenticación básica o tokens.
Verificar que la API está activa
Antes de hacer cualquier petición, comprueba que el servidor está corriendo:
# Verificar que Ollama esta activo (debe devolver "Ollama is running")
curl http://localhost:11434/
# Listar modelos disponibles
curl http://localhost:11434/api/tags
Si el primer comando devuelve Ollama is running, el servidor está
activo. Si no hay respuesta, ejecuta ollama serve en una terminal
o reinicia el servicio de Ollama.
POST /api/generate: completado de texto
El endpoint más básico de Ollama. Acepta un prompt y devuelve la respuesta generada por el modelo. Ideal para tareas de completado de texto, resumen, clasificación y extracción de información puntual.
Petición mínima con curl
curl http://localhost:11434/api/generate \
-H "Content-Type: application/json" \
-d '{
"model": "llama3.2",
"prompt": "Explica qué es un agente de IA en dos párrafos",
"stream": false
}'Estructura de la respuesta
{
"model": "llama3.2",
"created_at": "2026-05-13T10:00:00.000Z",
"response": "Un agente de IA es un sistema software que...",
"done": true,
"done_reason": "stop",
"context": [1, 2, 3, ...],
"total_duration": 4823811250,
"load_duration": 1234567,
"prompt_eval_count": 26,
"prompt_eval_duration": 234567890,
"eval_count": 298,
"eval_duration": 3456789012
}
El campo context contiene el estado interno del modelo tras
procesar el prompt. Puedes pasarlo de vuelta en la siguiente petición para
mantener el contexto sin usar /api/chat.
Respuesta con streaming (por defecto)
Sin "stream": false, el endpoint devuelve una serie de objetos
JSON separados por saltos de línea (newline-delimited JSON). Cada objeto
contiene un fragmento de la respuesta en el campo "response":
{"model":"llama3.2","created_at":"...","response":"Un ","done":false}
{"model":"llama3.2","created_at":"...","response":"agente ","done":false}
{"model":"llama3.2","created_at":"...","response":"de IA ","done":false}
...
{"model":"llama3.2","created_at":"...","response":"","done":true,"total_duration":4823811250,...}Petición con imagen (modelos multimodales)
# Con modelos como llava o moondream2 puedes incluir imágenes en base64
curl http://localhost:11434/api/generate \
-H "Content-Type: application/json" \
-d '{
"model": "llava",
"prompt": "¿Qué hay en esta imagen?",
"images": ["'$(base64 -w0 imagen.jpg)'"],
"stream": false
}'POST /api/chat: conversación con historial
A diferencia de /api/generate, el endpoint de chat mantiene el
historial completo de la conversación. Es el endpoint recomendado para construir
asistentes, chatbots y aplicaciones conversacionales.
Estructura de mensajes
curl http://localhost:11434/api/chat \
-H "Content-Type: application/json" \
-d '{
"model": "llama3.2",
"messages": [
{
"role": "system",
"content": "Eres un asistente técnico experto en Python. Responde siempre en español."
},
{
"role": "user",
"content": "¿Cómo ordeno una lista de diccionarios por un campo específico?"
}
],
"stream": false
}'Estructura de la respuesta de chat
{
"model": "llama3.2",
"created_at": "2026-05-13T10:00:00.000Z",
"message": {
"role": "assistant",
"content": "Para ordenar una lista de diccionarios en Python..."
},
"done": true,
"done_reason": "stop",
"total_duration": 5312678234,
"eval_count": 312
}Conversación multi-turno
Para mantener el contexto entre turnos, debes enviar el historial completo de mensajes en cada petición. El cliente es responsable de acumular el historial:
import requests
BASE_URL = "http://localhost:11434"
historial = [
{"role": "system", "content": "Eres un asistente de programación en español."}
]
def chat(mensaje: str) -> str:
historial.append({"role": "user", "content": mensaje})
respuesta = requests.post(
f"{BASE_URL}/api/chat",
json={
"model": "llama3.2",
"messages": historial,
"stream": False,
}
)
contenido = respuesta.json()["message"]["content"]
historial.append({"role": "assistant", "content": contenido})
return contenido
# Conversacion de ejemplo
print(chat("¿Qué es una list comprehension en Python?"))
print(chat("¿Puedes darme un ejemplo con filtrado?"))
print(chat("¿Y cómo la transformaría en un bucle for equivalente?")Chat con herramientas (tool calling)
curl http://localhost:11434/api/chat \
-H "Content-Type: application/json" \
-d '{
"model": "llama3.2",
"messages": [
{"role": "user", "content": "¿Cuál es el tiempo en Madrid ahora mismo?"}
],
"tools": [
{
"type": "function",
"function": {
"name": "obtener_tiempo",
"description": "Obtiene el tiempo actual para una ciudad",
"parameters": {
"type": "object",
"properties": {
"ciudad": {
"type": "string",
"description": "Nombre de la ciudad"
}
},
"required": ["ciudad"]
}
}
}
],
"stream": false
}'POST /api/embed: generación de embeddings
El endpoint de embeddings convierte texto en vectores numéricos de alta dimensión. Estos vectores son la base de las búsquedas semánticas, pipelines RAG y sistemas de recomendación basados en similitud de contenido.
Embedding de un texto
curl http://localhost:11434/api/embed \
-H "Content-Type: application/json" \
-d '{
"model": "nomic-embed-text",
"input": "Ollama permite ejecutar modelos de lenguaje en local"
}'Respuesta
{
"model": "nomic-embed-text",
"embeddings": [
[0.010071029, -0.0017594862, 0.05007221, 0.04692972, 0.054916814, ...]
],
"total_duration": 14143917,
"load_duration": 1019180,
"prompt_eval_count": 8
}Embeddings de múltiples textos en batch
curl http://localhost:11434/api/embed \
-H "Content-Type: application/json" \
-d '{
"model": "nomic-embed-text",
"input": [
"Ollama ejecuta modelos localmente",
"Docker permite contenerizar aplicaciones",
"Python es un lenguaje de programacion versatil"
]
}'| Modelo | Dimensiones | Tamaño | Mejor para |
|---|---|---|---|
nomic-embed-text |
768 | 274 MB | Uso general, RAG, búsqueda semántica |
mxbai-embed-large |
1024 | 669 MB | Mayor precisión, colecciones grandes |
all-minilm |
384 | 46 MB | Prototipos rápidos, recursos limitados |
snowflake-arctic-embed |
1024 | 669 MB | Documentos técnicos, código |
Gestión de modelos via API
Ollama expone endpoints para descargar, inspeccionar, copiar y eliminar modelos desde la API REST. Estos endpoints son útiles para automatizar la gestión de modelos en scripts de configuración y pipelines de CI/CD.
GET /api/tags — listar modelos
Devuelve todos los modelos disponibles localmente con su tamaño, fecha de modificación y digest. Equivalente a ollama list en la CLI.
POST /api/pull — descargar modelo
Descarga un modelo desde la biblioteca de Ollama. Soporta streaming para mostrar el progreso de la descarga. Equivalente a ollama pull.
POST /api/show — información del modelo
Devuelve los metadatos completos del modelo: Modelfile, parámetros, template, licencia y detalles de la arquitectura (familia, contexto, cuantización).
DELETE /api/delete — eliminar modelo
Elimina un modelo del almacenamiento local. Libera el espacio en disco ocupado por los pesos del modelo. Equivalente a ollama rm.
GET /api/ps — modelos en ejecución
Lista los modelos actualmente cargados en memoria (VRAM o RAM). Muestra el tiempo de expiración de cada modelo en el caché de Ollama.
Ejemplos de gestión de modelos con curl
# Listar todos los modelos instalados
curl http://localhost:11434/api/tags
# Descargar un modelo (con streaming de progreso)
curl http://localhost:11434/api/pull \
-H "Content-Type: application/json" \
-d '{"model": "llama3.2:3b"}'
# Informacion detallada de un modelo
curl http://localhost:11434/api/show \
-H "Content-Type: application/json" \
-d '{"model": "llama3.2"}'
# Eliminar un modelo
curl -X DELETE http://localhost:11434/api/delete \
-H "Content-Type: application/json" \
-d '{"model": "llama3.2"}'
# Ver modelos cargados en memoria ahora mismo
curl http://localhost:11434/api/psParámetros avanzados de inferencia
El objeto "options" permite ajustar el comportamiento del modelo
en cada petición. Estos parámetros son equivalentes a los que se configuran
en el Modelfile pero pueden sobreescribirse por petición.
curl http://localhost:11434/api/generate \
-H "Content-Type: application/json" \
-d '{
"model": "llama3.2",
"prompt": "Escribe un haiku sobre la programación",
"stream": false,
"options": {
"temperature": 0.9,
"top_p": 0.95,
"top_k": 50,
"num_ctx": 4096,
"num_predict": 200,
"repeat_penalty": 1.1,
"seed": 42
}
}'| Parámetro | Defecto | Rango | Descripción |
|---|---|---|---|
temperature |
0.8 | 0.0 – 2.0 | Controla la aleatoriedad. Más alto = más creativo, más bajo = más determinista. |
top_p |
0.9 | 0.0 – 1.0 | Muestreo nucleus. Solo considera tokens cuya probabilidad acumulada supera top_p. |
top_k |
40 | 1 – N | Limita el vocabulario candidato a los top_k tokens más probables. |
num_ctx |
2048 | 512 – max | Tamaño de la ventana de contexto en tokens. Valores altos requieren más VRAM. |
num_predict |
128 | -1 = sin limite | Número máximo de tokens a generar. -1 para sin límite, -2 para llenar el contexto. |
repeat_penalty |
1.1 | 1.0 – 2.0 | Penaliza la repetición de tokens recientes. Mayor valor = menos repetición. |
seed |
0 | entero | Semilla aleatoria. Con el mismo seed y prompt se obtiene siempre la misma respuesta. |
stop |
[] | array strings | Secuencias de parada. La generación se detiene cuando el modelo produce alguna de ellas. |
num_gpu |
auto | 0 – N | Capas del modelo a enviar a la GPU. 0 fuerza CPU. -1 usa todas las GPUs disponibles. |
Integración con Python, JavaScript y curl
Ejemplos completos y listos para usar en los tres entornos más comunes. Todos los ejemplos usan la API nativa de Ollama sin dependencias adicionales.
Python con httpx (asíncrono)
import httpx
import asyncio
import json
OLLAMA_URL = "http://localhost:11434"
async def generar_streaming(prompt: str, modelo: str = "llama3.2"):
"""Genera texto con streaming y va imprimiendo los tokens conforme llegan."""
async with httpx.AsyncClient(timeout=60.0) as client:
async with client.stream(
"POST",
f"{OLLAMA_URL}/api/generate",
json={
"model": modelo,
"prompt": prompt,
"stream": True,
"options": {"temperature": 0.7, "num_predict": 500},
}
) as respuesta:
async for linea in respuesta.aiter_lines():
if linea:
datos = json.loads(linea)
print(datos["response"], end="", flush=True)
if datos.get("done"):
print() # salto de linea al terminar
print(f"\nTokens generados: {datos.get('eval_count', 0)}")
break
asyncio.run(generar_streaming("Explica los beneficios de usar Docker en desarrollo"))JavaScript con fetch nativo
const OLLAMA_URL = 'http://localhost:11434';
// Funcion para chat con streaming en el navegador o Node.js
async function chat(mensajes, modelo = 'llama3.2') {
const respuesta = await fetch(`${OLLAMA_URL}/api/chat`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
model: modelo,
messages: mensajes,
stream: true,
}),
});
const lector = respuesta.body.getReader();
const decodificador = new TextDecoder();
let textoCompleto = '';
while (true) {
const { done, value } = await lector.read();
if (done) break;
const lineas = decodificador.decode(value).split('\n').filter(Boolean);
for (const linea of lineas) {
const datos = JSON.parse(linea);
if (datos.message?.content) {
textoCompleto += datos.message.content;
process.stdout.write(datos.message.content); // o actualiza el DOM
}
if (datos.done) break;
}
}
return textoCompleto;
}
// Uso
const mensajes = [
{ role: 'system', content: 'Eres un asistente útil en español.' },
{ role: 'user', content: '¿Qué es Ollama y para qué sirve?' },
];
chat(mensajes).then(respuesta => {
console.log('\n\nRespuesta completa:', respuesta.length, 'caracteres');
});Python con requests (síncrono, sin streaming)
import requests
def consulta_simple(prompt: str, modelo: str = "llama3.2") -> dict:
"""Peticion sincrona que devuelve la respuesta completa."""
respuesta = requests.post(
"http://localhost:11434/api/generate",
json={
"model": modelo,
"prompt": prompt,
"stream": False,
"options": {
"temperature": 0.7,
"num_ctx": 4096,
"num_predict": 1000,
}
},
timeout=120,
)
respuesta.raise_for_status()
datos = respuesta.json()
return {
"texto": datos["response"],
"tokens": datos.get("eval_count", 0),
"duracion_ms": datos.get("total_duration", 0) // 1_000_000,
}
resultado = consulta_simple("Resume en tres puntos las ventajas de los LLMs locales")
print(resultado["texto"])
print(f"Tokens: {resultado['tokens']} | Duracion: {resultado['duracion_ms']} ms")Compatibilidad con la API de OpenAI
Ollama expone una capa de compatibilidad con la API de OpenAI en
http://localhost:11434/v1/. Las aplicaciones que usan el cliente
oficial de OpenAI pueden migrar a Ollama cambiando solo dos líneas de código.
Migración del cliente de Python
# Antes (con OpenAI)
from openai import OpenAI
client = OpenAI(api_key="sk-...")
# Despues (con Ollama, cambios minimos)
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1", # <- unico cambio
api_key="ollama", # <- cualquier string no vacio
)
# El resto del codigo es identico
respuesta = client.chat.completions.create(
model="llama3.2", # nombre del modelo en Ollama
messages=[
{"role": "system", "content": "Eres un asistente en español."},
{"role": "user", "content": "Hola, como estas?"},
],
temperature=0.7,
max_tokens=500,
)
print(respuesta.choices[0].message.content)Migración del cliente de JavaScript
import OpenAI from 'openai';
const openai = new OpenAI({
baseURL: 'http://localhost:11434/v1', // <- unico cambio
apiKey: 'ollama', // <- cualquier string
});
const completion = await openai.chat.completions.create({
model: 'llama3.2',
messages: [
{ role: 'user', content: 'Explica el concepto de embeddings en dos párrafos' }
],
temperature: 0.8,
});
console.log(completion.choices[0].message.content);Endpoints compatibles con OpenAI
POST /v1/chat/completionsPOST /v1/completionsPOST /v1/embeddingsGET /v1/modelsGET /v1/models/:model
- Fine-tuning (
/v1/fine_tuning/) - Files API (
/v1/files/) - Assistants API (
/v1/assistants/) - Images (
/v1/images/) - Audio (
/v1/audio/)
API de Ollama vs APIs de proveedores en la nube
Cuándo elegir la API local de Ollama frente a las APIs comerciales de OpenAI, Anthropic o Google. La decisión depende del caso de uso, la privacidad y el presupuesto.
| Dimensión | Ollama (local) | OpenAI GPT-5 | Anthropic Claude |
|---|---|---|---|
| Coste por token | 0 € (hardware propio) | ~0.0025 €/1k tokens (input) | ~0.003 €/1k tokens (input) |
| Privacidad de datos | Total — datos nunca salen de tu maquina | Datos enviados a servidores de OpenAI | Datos enviados a servidores de Anthropic |
| Latencia | Depende del hardware local (GPU) | Baja y consistente en centros de datos | Baja y consistente en centros de datos |
| Calidad de modelos top | Buena con modelos 7B-70B cuantizados | Excelente (GPT-5, o3) | Excelente (Claude Opus 4.7) |
| Disponibilidad | Sin limite de rate ni cuotas | Rate limits por tier de cuenta | Rate limits por tier de cuenta |
| Configuración | Requiere hardware compatible y setup inicial | Solo API key, listo en segundos | Solo API key, listo en segundos |
| Modelos personalizados | Si — Modelfiles, LoRA, fine-tuning local | Fine-tuning disponible (coste adicional) | No disponible publicamente |
| Mejor para | Datos sensibles, desarrollo, alto volumen | Producción, calidad máxima, multimodal | Razonamiento complejo, textos largos |
Preguntas frecuentes sobre la API de Ollama
La API REST de Ollama escucha por defecto en http://localhost:11434. Puedes cambiar el host y el puerto con la variable de entorno OLLAMA_HOST. Por ejemplo, OLLAMA_HOST=0.0.0.0:11434 hace que la API sea accesible desde otras máquinas en la red local o desde otros contenedores Docker.
/api/generate acepta un prompt de texto plano y devuelve una respuesta de texto, sin mantener historial de conversación. Es el endpoint más simple y directo. /api/chat acepta un array de mensajes con roles (system, user, assistant) y mantiene el contexto de la conversación entre turnos. Usa /api/chat cuando construyas asistentes conversacionales y /api/generate para tareas de completado de texto puntual o pipelines de procesamiento de datos.
Incluye "stream": false en el cuerpo de la petición. Por ejemplo: {"model": "llama3.2", "prompt": "Hola", "stream": false}. El servidor devolverá un único objeto JSON con la respuesta completa en el campo "response" (en /api/generate) o "message" (en /api/chat).
Sí. Ollama expone un endpoint compatible con la API de OpenAI en /v1/. Puedes usar el cliente oficial openai de Python apuntando a http://localhost:11434/v1 con api_key="ollama". La mayoría de las aplicaciones que usan GPT-3.5 o GPT-4 se pueden migrar a modelos locales de Ollama cambiando solo la base_url y el nombre del modelo.
Los parámetros principales, todos pasados en el objeto "options", son: temperature (0.0-2.0, controla la aleatoriedad; defecto 0.8), top_p (muestreo nucleus; defecto 0.9), top_k (limita vocabulario candidato; defecto 40), num_predict (tokens máximos a generar; -1 para sin límite), num_ctx (tamaño de la ventana de contexto en tokens; defecto 2048). Usa seed para obtener respuestas deterministas y reproducibles.
Usa el endpoint POST /api/embed con el cuerpo {"model": "nomic-embed-text", "input": "tu texto aquí"}. Para múltiples textos en batch, pasa un array en "input". Ollama también soporta /v1/embeddings con el formato compatible con OpenAI. Los modelos recomendados son nomic-embed-text (274 MB, 768 dimensiones) para uso general y mxbai-embed-large para mayor precisión.