- Actualmente en versión Sonnet 4.6 (mayo 2026): el nivel "balanced" de la familia Claude, con el mejor ratio capacidad-precio para producción.
- Precio de API: $3 por millón de tokens de entrada, $15 por millón de salida. Con prompt caching: $0,30 por millón de tokens cacheados — hasta un 90% de ahorro en agentes con system prompts repetitivos.
- Ventana de contexto de 1M tokens: permite analizar repositorios de código completos, documentos extensos o historiales de conversación de agentes con decenas de pasos.
- Soporta razonamiento extendido (extended thinking), visión para análisis de imágenes y tool use con llamadas en paralelo — las tres capacidades clave para agentes autónomos modernos.
- Disponible via API de Anthropic, Claude.ai (Free con limites, Pro), AWS Bedrock y Google Cloud Vertex AI, lo que facilita la integración en cualquier infraestructura.
¿Qué es Claude Sonnet y para que está diseñado?
Claude Sonnet es el nivel intermedio de la familia de modelos Claude de Anthropic, situado entre el modelo ligero Haiku y el modelo frontier Opus. Su objetivo de diseño es claro: ofrecer la mayor capacidad posible dentro de un rango de coste que permita su uso en producción con volumen real. En la practica, esto lo convierte en el modelo que Anthropic recomienda para la mayoría de aplicaciones — desde agentes de coding hasta pipelines de análisis de documentos — salvo en los casos extremos donde o bien el precio es el único criterio (Haiku) o bien la máxima capacidad de razonamiento es no negociable (Opus).
La versión actual es Claude Sonnet 4.6, publicada en 2026. Cuenta con una ventana de contexto de 1M tokens, lo que le permite trabajar con documentos de hasta 750.000 palabras o proyectos de código con múltiples archivos en una sola llamada. A diferencia de versiones anteriores, Sonnet 4.6 integra de forma nativa el razonamiento extendido (extended thinking), mejoras en seguimiento de instrucciones en contextos muy largos y mayor precisión en la ejecución de llamadas a herramientas con esquemas JSON complejos.
En terminos de benchmarks independientes, Claude Sonnet ocupa consistentemente una posición de liderazgo en SWE-bench — el estándar de referencia para coding autónomo que mide la capacidad de resolver issues reales de GitHub — dentro de su rango de precio. Esto lo convierte en la opción de referencia para equipos de desarrollo que usan IA para asistencia de código, revisión de pull requests, generación de tests o refactorización automatizada. Además, su rendimiento en tareas de razonamiento general, matemática y seguimiento de instrucciones lo hace apto para un espectro mucho más amplio de aplicaciones empresariales que las puramente orientadas a código.
Claude Sonnet está disponible a traves de múltiples canales: la API de Anthropic para integración directa, el interfaz web Claude.ai para uso sin programación (plan Free con limites y plan Pro), y plataformas cloud de terceros como Amazon Bedrock y Google Cloud Vertex AI para equipos con infraestructura ya existente en estos proveedores. También es el modelo que impulsa Claude Code, la CLI de Anthropic para agentes de desarrollo autónomo sobre repositorios locales.
¿Qué capacidades tiene Claude Sonnet 4.6?
Todas las capacidades descritas aplican a Claude Sonnet 4.6 (mayo 2026). Consulta la documentación oficial de modelos de Anthropic para la lista actualizada de versiones.
Razonamiento extendido (Extended Thinking)
Claude Sonnet 4.6 soporta un modo de razonamiento extendido en el que el modelo
genera un bloque de pensamiento interno — visible en la respuesta de la API bajo
el campo thinking — antes de producir la respuesta final. En este
modo, el modelo explora hipótesis alternativas, verifica pasos intermedios y
corrige errores de razonamiento antes de comprometerse con una respuesta. El
resultado es una mejora significativa en precisión para problemas de lógica
compleja, matemática, planificación multi-paso y preguntas que requieren integrar
información de múltiples partes del contexto. El razonamiento extendido consume
tokens adicionales que se facturan al precio estándar de output, por lo que su
uso se recomienda para tareas donde el coste del error supera el coste del token
extra.
Visión — análisis de imágenes y documentos visuales
Claude Sonnet soporta visión nativa: puede recibir imágenes como parte del mensaje en formato base64 o URL y analizarlas con el mismo nivel de capacidad linguistica que aplica al texto. Sus aplicaciones practicas incluyen: leer texto en capturas de pantalla de interfaces o documentos escaneados, interpretar gráficos de barras o series temporales y extraer datos numericos, describir diagramas de arquitectura o flujos de proceso, y comparar versiones visuales de documentos. En pipelines de automatización de documentos — facturas, contratos, formularios — la visión de Sonnet permite procesar imágenes sin necesidad de un paso previo de OCR externo.
Tool use — llamadas a herramientas y function calling
Claude Sonnet soporta tool use nativo con definición de herramientas mediante esquemas JSON. El modelo puede invocar múltiples herramientas en paralelo en una sola respuesta, reduciendo la latencia en agentes que necesitan varios datos al mismo tiempo. También gestiona correctamente la recuperación ante errores de herramientas: cuando una llamada devuelve un error, Claude lo procesa, ajusta los parámetros y reintenta sin intervensión humana. Esta combinación — paralelismo + recuperación ante errores — es lo que hace de Sonnet la base de la mayoría de agentes autónomos de producción construidos con el Claude Agent SDK.
Rendimiento en coding — benchmarks SWE-bench
SWE-bench es el benchmark de referencia para coding autónomo: mide el porcentaje de issues reales de repositorios de GitHub que el modelo puede resolver de forma autónoma, sin ayuda humana. Claude Sonnet 4.6 se situa entre los mejores modelos del mercado en SWE-bench para su rango de precio, superando a competidores como GPT-4 en la mayoría de categorías de complejidad. Más allá de los benchmarks, su rendimiento práctico en tareas de coding se traduce en mayor precisión al generar código funcional a la primera, mejor seguimiento de patrones y convenciones del repositorio existente, y menor tasa de alucinaciones en nombres de funciones, imports y APIs específicas de un proyecto.
Prompt caching — reducción de costes en producción
La API de Anthropic soporta prompt caching para Claude Sonnet: si el inicio del mensaje — típicamente el system prompt y los documentos de contexto — no cambia entre llamadas, esos tokens se almacenan en cache y se facturan a $0,30 por millón en lugar de $3,00. En un agente con un system prompt de 8.000 tokens que ejecuta 100 pasos por sesión, esto puede reducir el coste de entrada en un 90%. Para pipelines RAG donde los documentos de contexto son fijos, el ahorro es equivalente. Implementar prompt caching es la optimización de coste de mayor impacto disponible para aplicaciones Sonnet en producción con volumen.
Contexto de 1M tokens — análisis de documentos completos
La ventana de 1M tokens equivale a aproximadamente 750.000 palabras de texto, suficiente para incluir en una sola llamada a la API: un repositorio de código de gran tamaño, un expediente juridico complejo de varios cientos de páginas, el historial de cientos de turnos de una conversación con llamadas a herramientas, o varios informes financieros anuales para análisis comparativo. Esta capacidad elimina la necesidad de chunking en la mayoría de casos de uso reales, lo que simplifica significativamente la arquitectura de los sistemas que procesan documentos largos.
Precios de Claude Sonnet y planes de acceso — mayo 2026
Precios en dolares por millón de tokens (MTok). Verifica los precios actuales en anthropic.com/pricing antes de estimar costes de producción, ya que Anthropic los actualiza periodicamente.

| Tipo de token | Precio ($/MTok) | Cuando aplica |
|---|---|---|
| Input estándar | $3,00 | Tokens de entrada en llamadas normales sin cache activo |
| Input cacheado | $0,30 | Tokens de entrada que coinciden con un prefijo en cache (ahorro del 90%) |
| Output | $15,00 | Todos los tokens generados por el modelo en la respuesta |
| Output de thinking | $15,00 | Tokens del bloque de razonamiento extendido (si está activado) |
Planes de acceso a Claude Sonnet
| Plan | Acceso a Sonnet | Precio | Mejor para |
|---|---|---|---|
| Claude.ai Free | Si, con limites de uso | Gratis | Uso personal ocasional, evaluación |
| Claude.ai Pro | Si, acceso ampliado | ~$20/mes | Uso intensivo sin programación, Claude Projects |
| API de Anthropic | Si, sin limites de uso (por credito) | $3 input / $15 output MTok | Integración en aplicaciones, agentes, producción |
| AWS Bedrock | Si, mismo modelo | Similar a API directa | Equipos con infraestructura AWS existente |
| Google Vertex AI | Si, mismo modelo | Similar a API directa | Equipos con infraestructura Google Cloud existente |
Para aplicaciones en producción, la via recomendada es la API directa de Anthropic o las plataformas cloud si ya se tiene una relación contractual con AWS o Google. Los planes de Claude.ai (Free y Pro) no están diseñados para integración en aplicaciones — no tienen acceso programatico directo — y sus limites de uso no son adecuados para volumen de producción. Puedes comparar todas las opciones de precios en nuestra guía detallada de precios de Claude.
¿Para qué tareas es Claude Sonnet la mejor opción?
Escenarios donde el equilibrio de Sonnet entre capacidad y coste ofrece la mayor ventaja frente a Haiku (insuficiente) y Opus (demasiado caro).
Claude Sonnet vs Opus vs Haiku — en que se diferencian?
Comparativa de los tres modelos de la familia Claude a mayo de 2026. Los tres comparten las capacidades de visión y tool use. Haiku tiene 200K tokens de contexto; Sonnet y Opus tienen 1M. Las diferencias principales son capacidad de razonamiento y precio.
| Dimensión | Claude Haiku 4.5 | Claude Sonnet 4.6 | Claude Opus 4.7 |
|---|---|---|---|
| Tier | Fast (económico) | Balanced (equilibrado) | Frontier (máximo) |
| Input API | $1,00 / MTok | $3,00 / MTok | $5,00 / MTok |
| Output API | $5,00 / MTok | $15,00 / MTok | $25,00 / MTok |
| Cached input | ~$0,10 / MTok | $0,30 / MTok | ~$0,50 / MTok |
| Contexto | 200K tokens | 1M tokens | 1M tokens |
| Razonamiento extendido | No | Si | Si |
| Visión | Si | Si | Si |
| Tool use paralelo | Si | Si | Si |
| SWE-bench coding | Bajo | Alto (líder en su precio) | Máximo |
| Velocidad de respuesta | Muy rápido | Rápido | Moderado |
| Mejor para | Clasificación, routing, alto volumen | Coding, agentes, análisis, escritura | Razonamiento crítico, planificación compleja |
| No recomendado para | Razonamiento multi-paso, coding complejo | Tareas frontier de misión critica | Alto volumen o tareas simples (demasiado caro) |
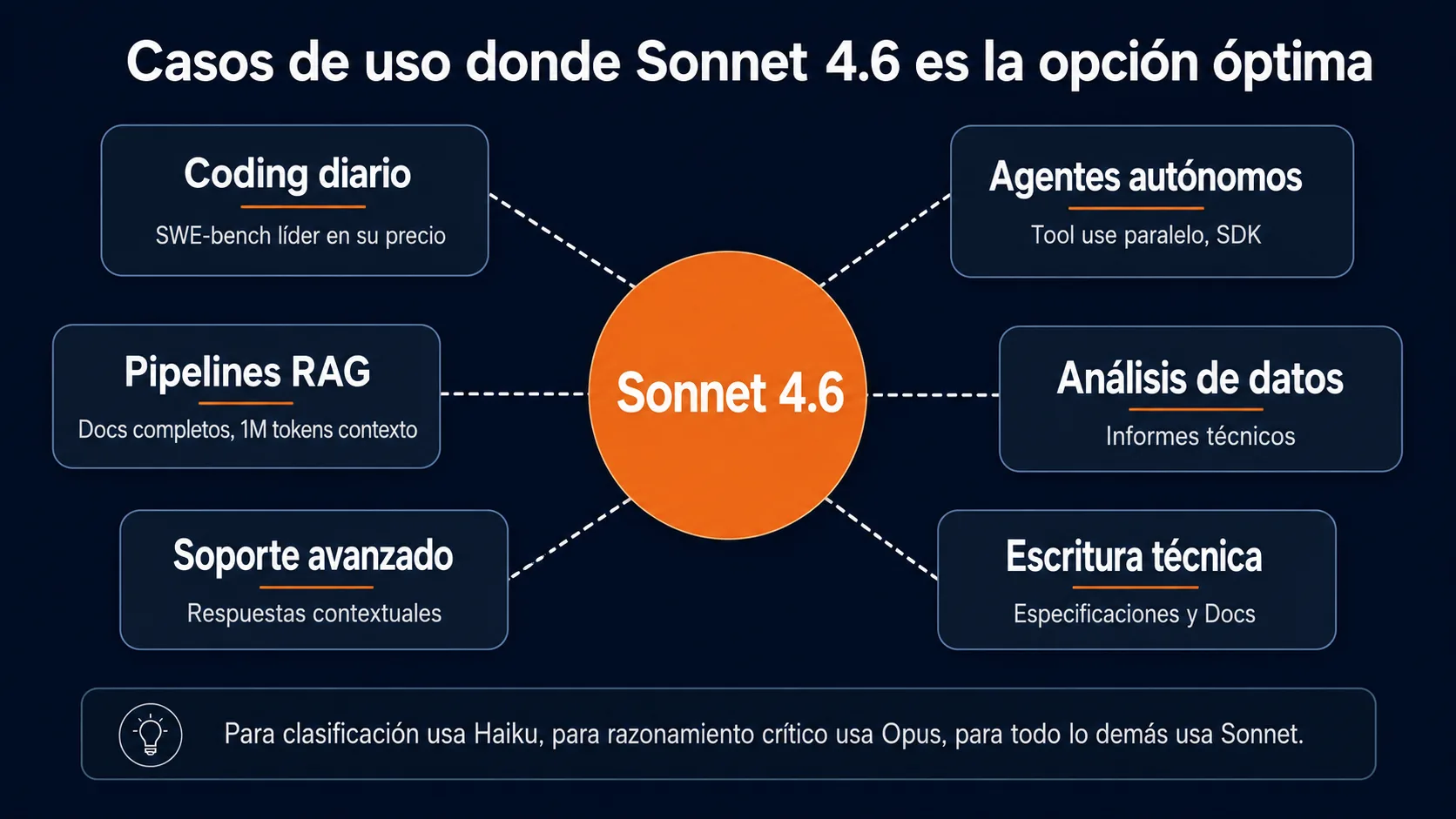
Cuando elegir Sonnet en lugar de Opus o Haiku
La regla practica de la familia Claude es: usa Haiku para clasificar, Sonnet para ejecutar y Opus para decidir. Claude Sonnet es la opción correcta cuando la tarea requiere razonamiento real — generar código funcional, analizar un documento con precisión, redactar contenido técnico de calidad — pero no necesita el nivel frontier de Opus, que está justificado principalmente para decisiones con consecuencias directas en el negocio (análisis juridico, razonamiento sobre información ambigua, planificación estrategica multi-paso).
En terminos prácticos, la mayoría de agentes en producción pueden construirse combinando Haiku para los pasos de clasificación y routing (60-70% de las llamadas) y Sonnet para los pasos de ejecución (25-35%). Reservar Opus solo para los pasos críticos (5-10%) puede reducir el coste total del agente entre un 50% y un 70% sin degradar la calidad del resultado final percibida por el usuario.
Preguntas frecuentes sobre Claude Sonnet
¿Qué es Claude Sonnet y en que se diferencia de Opus y Haiku?
Claude Sonnet es el nivel intermedio de la familia Claude de Anthropic. Actualmente en la versión 4.6 (mayo 2026), ofrece el mejor equilibrio entre capacidad de razonamiento y coste. Frente a Claude Haiku (rápido y económico, $1/$5 por millón de tokens), Sonnet tiene mayor capacidad de razonamiento, coding y seguimiento de instrucciones complejas. Frente a Claude Opus (frontier, $5/$25), Sonnet es significativamente más económico — $3/$15 — siendo la opción recomendada para la mayoría de casos de uso en producción donde Opus seria excesivo en coste.
¿Cuánto cuesta usar Claude Sonnet 4.6 por API?
A mayo de 2026, Claude Sonnet 4.6 cuesta $3 por millón de tokens de entrada y $15 por millón de tokens de salida. Con prompt caching activado, los tokens de entrada cacheados se reducen a $0,30 por millón — un ahorro del 90%. Para una aplicación de soporte al cliente con un system prompt de 5.000 tokens y 200 llamadas diarias, el ahorro mensual con caching puede superar los $500 frente al precio estándar. Puedes ver una comparativa completa de planes y precios en la guía de precios de Claude.
¿Cuál es la ventana de contexto de Claude Sonnet 4.6?
Claude Sonnet 4.6 tiene una ventana de contexto de 1.000.000 tokens (1M), equivalente a aproximadamente 750.000 palabras. Esto permite incluir en una sola llamada a la API: un repositorio de código completo de gran tamaño, un expediente juridico extenso, el historial de cientos de turnos de una conversación de agente con llamadas a herramientas, o varios informes financieros anuales para análisis comparativo. Esta capacidad elimina la necesidad de chunking en la mayoría de casos.
Soporta Claude Sonnet visión e imágenes?
Si. Claude Sonnet 4.6 soporta visión nativa: puede recibir imágenes como parte del mensaje en formato base64 o URL y analizarlas con la misma capacidad linguistica que aplica al texto. Sus aplicaciones practicas incluyen leer texto en capturas de pantalla, interpretar gráficos y extraer datos numericos, describir diagramas de arquitectura y procesar documentos escaneados sin OCR externo. La capacidad de visión no tiene un coste adicional específico — los tokens de imagen se cuentan como tokens de entrada al precio estándar.
Es Claude Sonnet mejor que GPT-4 para programar?
En los benchmarks independientes de coding (SWE-bench), Claude Sonnet 4.6 supera a GPT-4 en la mayoría de categorías de complejidad, especialmente en proyectos donde se necesita leer y modificar múltiples archivos relacionados. Su ventana de 1M tokens le permite analizar bases de código completas sin tener que fragmentar el contexto, lo que resulta en código generado más coherente con las convenciones del proyecto existente. Para snippets simples y aislados, ambos modelos ofrecen resultados equivalentes. Para tareas de agente autónomo sobre repositorios reales, Sonnet tiene una ventaja medible.
¿Cómo activo el razonamiento extendido en Claude Sonnet?
El razonamiento extendido se activa a traves de la API de Anthropic incluyendo
el parámetro thinking en la llamada, con un presupuesto de tokens
de razonamiento (budget_tokens). Por ejemplo, con el SDK de Python:
thinking={"type": "enabled", "budget_tokens": 10000}. La respuesta
incluira un bloque de tipo thinking con el razonamiento interno,
seguido del bloque text con la respuesta final. Los tokens de
razonamiento se facturan al precio estándar de output ($15/MTok). Consulta la
documentación oficial de extended thinking
para el ejemplo de código completo.
Compara todos los precios de Claude en detalle
Guía completa con precios de API, planes de Claude.ai, comparativa con AWS Bedrock y Google Vertex AI, y calculadora de coste estimado para tu caso de uso.
Ver guía de precios de Claude