- Claude Opus 4.7 es el modelo de mayor capacidad de Anthropic: líder en SWE-bench Verified (más del 72% de tasa de resolución), GPQA y MATH a mayo de 2026.
- Extended thinking nativo: el modelo genera un proceso de razonamiento interno antes de responder, explorando hipótesis y verificando inferencias para tareas de máxima complejidad.
- Precio: $5/MTok de entrada y $25/MTok de salida. Con prompt caching, los tokens cacheados cuestan $0,50/MTok — un 90% menos en system prompts repetidos.
- Ventana de contexto de 1M tokens: suficiente para analizar bases de código completas, contratos extensos o documentos de cientos de páginas sin fragmentar el contenido.
- Disponible via Anthropic API, Claude.ai Pro/Team/Enterprise, Amazon Bedrock y Google Cloud Vertex AI, con soporte de visión y tool use paralelo en todas las plataformas.
¿Qué es Claude Opus y para quien está diseñado?
Dentro de la familia de modelos explicada en detalle en la página de Claude AI de Anthropic, Opus ocupa el nivel frontier: el modelo con mayor capacidad de razonamiento y el precio más elevado. La versión activa a mayo de 2026 es Claude Opus 4.7, disponible via la API de Anthropic y en los planes de consumidor de Claude.ai Pro, Team y Enterprise.
La distinción clave de Opus frente a Claude Sonnet no es de función sino de profundidad. Ambos modelos pueden redactar, razonar y generar código. La diferencia aparece en tareas donde la calidad del primer razonamiento importa: análisis de contratos con cláusulas contradictorias, investigación que requiere síntesis de evidencias ambiguas, arquitectura de sistemas con múltiples restricciones técnicas, o código que debe cumplir invariantes de seguridad no triviales. En esos contextos, Opus produce respuestas con mayor precisión y menos necesidad de iteración correctiva, lo que justifica su precio premium.
Opus no es el modelo para todo. En un agente de producción típico, la mayoría de los pasos — routing de intenciones, extracción de datos, generación de texto estructurado — los resuelve Sonnet con calidad equivalente y a un tercio del coste. La regla practica es reservar Opus para las decisiones criticas: el paso del agente donde un error tiene consecuencias directas en el negocio, donde el razonamiento multi-paso debe sostenerse durante muchas inferencias, o donde el dominio es tan especializado que la precisión marginal de Opus marca la diferencia entre un resultado útil y uno incorrecto.
Claude Opus también es el modelo que impulsa Claude Code en su modo de máxima capacidad: cuando el agente necesita planificar cambios arquitectonicos complejos, refactorizar sistemas legados o tomar decisiones de diseño con impacto a largo plazo en el código. Para tareas de ejecución rutinaria dentro del mismo agente, Claude Code delega en Sonnet para mantener el coste operativo bajo control.
¿Qué puede hacer Claude Opus 4.7?
Capacidades técnicas del modelo frontier de Anthropic disponibles via API y Claude.ai.
Extended thinking — razonamiento profundo antes de responder
Claude Opus 4.7 soporta extended thinking de forma nativa: antes de generar la respuesta visible, el modelo ejecuta un proceso de razonamiento interno en el que plantea hipótesis, las evalúa, considera casos extremos y verifica sus propias inferencias. Este proceso puede durar desde unos pocos segundos hasta varios minutos dependiendo de la complejidad de la tarea. Los tokens de thinking se facturan como tokens de salida, pero la mejora en precisión en problemas complejos — matemática, lógica formal, planificación multi-paso — es sustancial. El razonamiento interno puede exponerse al usuario final o mantenerse oculto según la configuración de la llamada a la API.
Coding autónomo de alto nivel — líder en SWE-bench
Claude Opus 4.7 lidera SWE-bench Verified con más del 72% de tasa de resolución a mayo de 2026. SWE-bench mide la capacidad de resolver issues reales de GitHub en proyectos Python con tests automatizados — el benchmark más representativo para coding autónomo en condiciones de producción real. La ventaja de Opus frente a modelos alternativos es especialmente pronunciada en issues que requieren entender la arquitectura de un proyecto completo, rastrear dependencias entre módulos y generar código que pase tests de integración sin modificar los tests en si. Para coding de alto nivel con impacto en producción, Opus es la elección más segura.
Investigación y síntesis de información compleja
Opus destaca en tareas de investigación donde la información disponible es incompleta, contradictoria o altamente especializada. Su capacidad de mantener una cadena de razonamiento coherente a lo largo de miles de tokens de contexto le permite comparar fuentes, identificar inconsistencias y producir síntesis que reconocen explicitamente la incertidumbre en lugar de colapsar a una conclusión simplificada. Para investigación en dominios como medicina, derecho, finanzas o ciencia aplicada, donde la matización importa tanto como la respuesta, Opus produce resultados cualitativamente superiores a los de modelos de menor tier.
Visión — análisis avanzado de imágenes y documentos visuales
Claude Opus 4.7 analiza imágenes directamente: capturas de pantalla, diagramas de arquitectura, gráficos de datos, tablas escaneadas, mockups de interfaz o documentos con formato visual complejo. La precisión de Opus en visión es la más alta de la familia Claude — supera a Sonnet en tareas que requieren razonamiento sobre el contenido visual (no solo descripción), como identificar errores en un diagrama de entidad-relación, extraer datos de una tabla con formato irregular o analizar el estado de una interfaz y proponer cambios específicos. Las imágenes pueden incluirse directamente en las llamadas a la API junto con texto.
Tool use paralelo — orquestación de herramientas en cadena
Claude Opus soporta tool use nativo con llamadas en paralelo: puede ejecutar múltiples herramientas simultaneamente en una sola llamada a la API, reduciendo la latencia en agentes que necesitan consultar varias fuentes de datos al mismo tiempo. El esquema de herramientas es JSON tipado, y Opus es especialmente fiable para rellenar parámetros correctamente incluso con instrucciones complejas en lenguaje natural. Compatible con el protocolo MCP (Model Context Protocol) de Anthropic para integraciones estandarizadas con servicios externos. En agentes multi-paso con muchas herramientas en cadena, Opus mantiene mejor el estado lógico del plan a medida que el contexto crece.
Contexto de 1M tokens — proyectos y documentos completos
Los 1M tokens de contexto de Claude Opus equivalen a aproximadamente 750.000 palabras. En la practica, esto permite analizar contratos extensos, leer bases de código de gran tamaño o procesar el historial completo de un proyecto sin necesidad de fragmentar el contenido. El contexto largo elimina los errores de coordinación entre fragmentos que introducen los sistemas RAG clásicos y permite a Opus mantener coherencia en el razonamiento a lo largo de todo el documento. Para documentos críticos donde el detalle en cualquier cláusula importa, la ventana de 1M tokens es un requisito, no una ventaja marginal.
Escritura creativa y técnica de alta calidad
Opus produce texto con mayor densidad conceptual y menor "relleno" que modelos de menor tier. En documentos técnicos — especificaciones de arquitectura, análisis de requisitos, informes de seguridad — la diferencia es perceptible: las respuestas son más precisas en la terminologia, más cuidadosas en la distinción entre lo que se sabe y lo que se infiere, y más coherentes en estilo a lo largo de documentos largos. Para escritura creativa compleja — narrativa estructurada, guiones con múltiples hilos, contenido con voz de autor específica — Opus mantiene mejor la coherencia tematica y de personaje a lo largo de contextos extensos.
¿Cuánto cuesta Claude Opus por API? Tabla de precios
Precios en dolares por millón de tokens (MTok). Consulta anthropic.com/pricing para confirmar precios actuales antes de estimar costes de producción. Para un análisis detallado del coste por caso de uso, consulta la página de precios de la API de Claude.
| Concepto | Precio sin caching | Precio con prompt caching | Contexto máximo |
|---|---|---|---|
| Tokens de entrada (input) | $5,00 / MTok | $0,50 / MTok (tokens cacheados) $5,00 / MTok (no cacheados) |
1.000.000 tokens (1M) |
| Tokens de salida (output) | $25,00 / MTok | $25,00 / MTok |
Como calcular el coste real de Claude Opus en producción
El coste de Opus depende de dos factores principales: el volumen de tokens consumidos y el uso del prompt caching. En un agente típico, el system prompt puede ocupar entre 2.000 y 15.000 tokens y se envia en cada llamada. Sin caching, esos tokens de entrada cuestan $5/MTok por llamada. Con caching activado, las llamadas posteriores pagan $0,50/MTok por los tokens cacheados — el 90% menos. En un agente con 50 pasos por tarea y un system prompt de 10.000 tokens, el ahorro acumulado en tokens de entrada puede superar el 70% del coste total de entrada.
La estrategia más habitual en producción es combinar tiers: usar Opus para las decisiones criticas del agente (planificación, análisis, resolución de ambigüedades) y delegar los pasos de ejecución rutinaria a Claude Sonnet 4.6. Esto puede reducir el coste global del agente entre un 50% y un 70% sin degradar la calidad del resultado final. Para tareas completamente autónomas de alto impacto donde cada paso importa, Opus justifica su precio premium.
Claude Opus en planes de consumidor — Claude.ai Pro y Team
Claude Opus 4.7 está incluido en el plan Claude.ai Pro (~$20/mes) y en los planes Team y Enterprise de Anthropic. En los planes de consumidor, el acceso a Opus puede estar sujeto a cuotas de uso mensual: cuando se alcanza el limite, Claude.ai conmuta automáticamente a Sonnet para el resto del periodo. Para acceso programatico sin limitaciones de cuota, la API de Anthropic es la via recomendada. Los planes de consumidor no son adecuados para uso en producción con volumen significativo.
Benchmarks de Claude Opus 4.7: SWE-bench, GPQA y MATH
Resultados documentados por Anthropic y evaluaciones independientes a mayo de 2026. Los benchmarks miden capacidades específicas — ninguno captura la calidad total de un modelo en producción real, pero son el mejor indicador disponible de rendimiento comparativo.
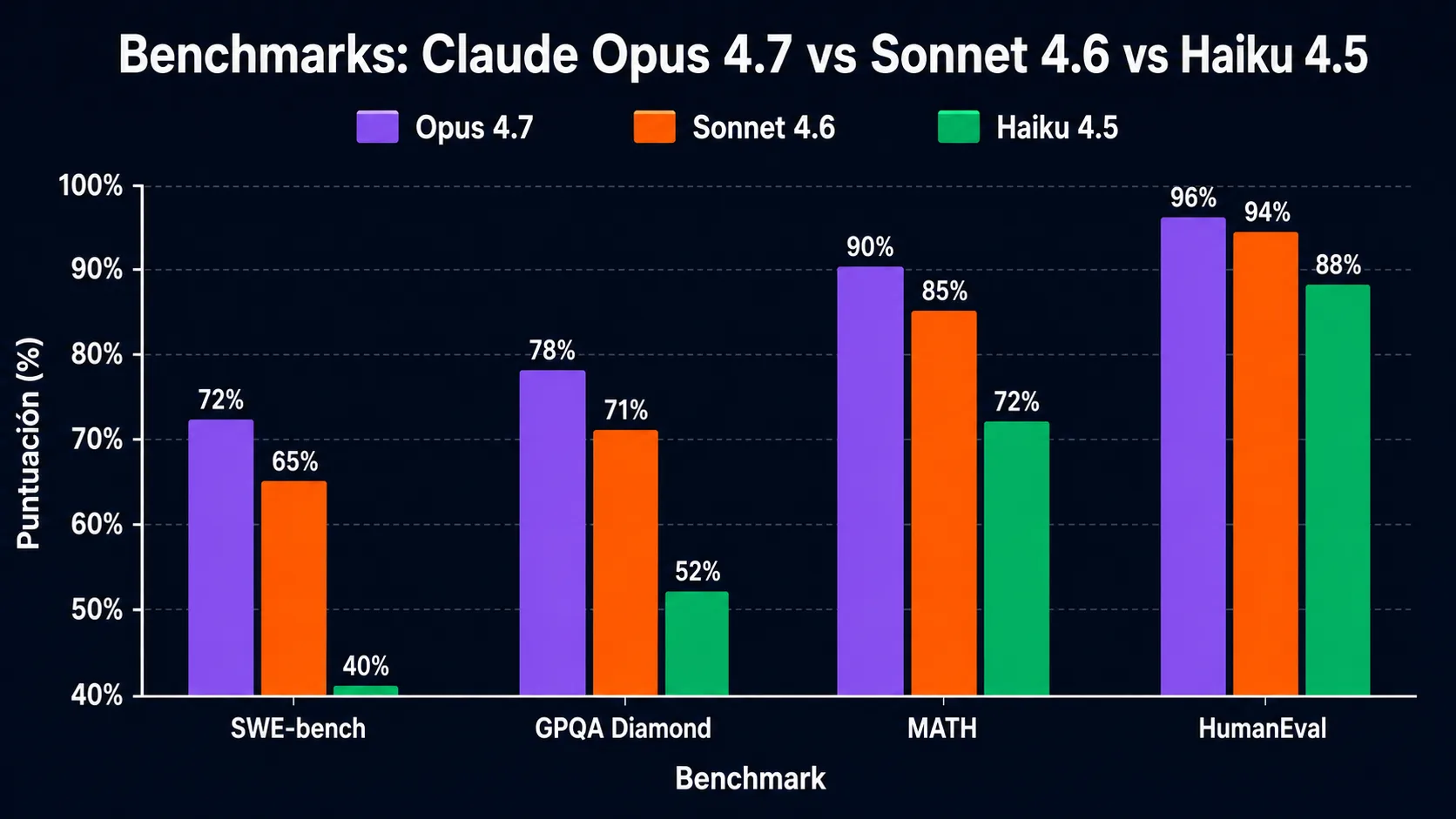
| Benchmark | Que mide | Opus 4.7 | Sonnet 4.6 | Haiku 4.5 |
|---|---|---|---|---|
| SWE-bench Verified | Resolución de issues reales de GitHub con tests | >72% | ~65% | ~40% |
| GPQA Diamond | Preguntas de nivel doctorado (ciencias) | >78% | ~71% | ~52% |
| MATH | Problemas de matemática competitiva | >90% | ~85% | ~72% |
| HumanEval | Generación de código Python con tests unitarios | >96% | ~94% | ~88% |
| MMLU | Conocimiento multidisciplinar (57 categorías) | >90% | ~88% | ~80% |
Por que SWE-bench es el benchmark más relevante para agentes de código
SWE-bench Verified mide algo que los benchmarks de coding tradicionales no capturan: la capacidad de resolver un issue en un proyecto real, con dependencias reales, leyendo el código existente y generando un parche que pase los tests sin romper el resto del proyecto. No es generación de funciones aisladas — es razonamiento sobre un sistema complejo con historia y restricciones propias. Por eso es el benchmark más predictivo del rendimiento real de un modelo en tareas de desarrollo autónomo.
GPQA Diamond mide algo diferente pero igual de relevante para Opus: la capacidad de razonar en dominios de alta especialidad donde el conocimiento superficial no es suficiente. Las preguntas de GPQA Diamond están diseñadas para ser incorrectas incluso para expertos con acceso a internet — requieren razonamiento original a partir de principios, no recuperación de hechos memorizados. La puntuación de Opus en GPQA es la más alta documentada entre modelos de proposito general a mayo de 2026.
Los datos exactos de benchmarks pueden variar con las actualizaciones del modelo. Consulta la página oficial de Claude Opus en Anthropic para los números actualizados.
¿Cuándo usar Claude Opus? Casos de uso donde marca la diferencia
Opus no es el modelo para todo. Estos son los contextos donde su capacidad frontier justifica el coste adicional frente a Sonnet.

Opus vs Sonnet vs Haiku: cual elegir?
Comparativa técnica y económica de los tres modelos de la familia Claude. Los tres comparten las capacidades de visión y tool use. Haiku tiene 200K tokens de contexto; Sonnet y Opus tienen 1M. Las diferencias son de profundidad de razonamiento y coste.
| Dimensión | Claude Opus 4.7 | Claude Sonnet 4.6 | Claude Haiku 4.5 |
|---|---|---|---|
| Tier | Frontier | Balanced | Fast |
| Precio input | $5,00 / MTok | $3,00 / MTok | $1,00 / MTok |
| Precio output | $25,00 / MTok | $15,00 / MTok | $5,00 / MTok |
| Precio caching input | $0,50 / MTok | $0,30 / MTok | $0,10 / MTok |
| Ventana de contexto | 1M tokens | 1M tokens | 200K tokens |
| SWE-bench Verified | >72% | ~65% | ~40% |
| Extended thinking | Nativo, profundo | Disponible | Limitado |
| Visión | Alta precisión | Buena precisión | Precisión básica |
| Tool use paralelo | Si | Si | Si |
| Velocidad de respuesta | Moderada | Rápida | Muy rápida |
| Mejor para | Razonamiento crítico, investigación, coding frontier | Agentes de producción, coding rutinario, escritura técnica | Clasificación, routing, alto volumen, latencia mínima |
| Disponible en | API, Claude.ai Pro/Team/Enterprise, Bedrock, Vertex AI | API, Claude.ai Free/Pro/Team, Bedrock, Vertex AI | API, Claude.ai Pro/Team, Bedrock, Vertex AI |
- Usa Haiku para pasos del agente que clasifican, filtran o extraen datos simples. Son el 60-70% de las llamadas en un agente típico y Haiku los resuelve perfectamente.
- Usa Sonnet para la ejecución: generar código, redactar documentos, llamar a herramientas en cadena. El 25-35% de las llamadas donde Sonnet ofrece la relación calidad-precio optima.
- Usa Opus para las decisiones criticas: el 5-10% de los pasos donde un error tiene consecuencias directas, donde el razonamiento multi-paso debe sostenerse o donde el dominio requiere máxima precisión.
- Esta estrategia de tiers puede reducir el coste total de un agente entre un 50% y un 70% sin degradar la calidad del resultado percibida por el usuario final.
Para comparar Claude Opus con los modelos frontier de otros proveedores, consulta las páginas de Claude Sonnet, Claude Haiku y el catalogo completo en Claude AI de Anthropic. Para comparativas entre proveedores — Claude vs ChatGPT, Claude vs Gemini — consulta la sección de comparativas de modelos LLM.
Preguntas frecuentes sobre Claude Opus
Claude Opus 4.7 es el modelo frontier de Anthropic: el de mayor capacidad de razonamiento dentro de la familia Claude. Se diferencia de Sonnet en profundidad, no en función: ambos pueden generar código, redactar y razonar, pero Opus produce resultados con mayor precisión en tareas que requieren cadenas de inferencia largas, dominio especializado o razonamiento sobre información incompleta o contradictoria. El precio es mayor: $5/MTok de entrada frente a $3/MTok de Sonnet. La decisión de usar Opus depende de si la precisión marginal justifica el coste adicional en el caso de uso concreto.
Claude Opus 4.7 cuesta $5 por millón de tokens de entrada y $25 por millón de tokens de salida. Con prompt caching activado, los tokens cacheados en la entrada cuestan $0,50/MTok — un 90% menos. La ventana de contexto es de 1M tokens. En producción con system prompts extensos, el caching puede reducir el coste efectivo de entrada en más de un 70%. Consulta anthropic.com/pricing para confirmar precios actualizados.
Extended thinking es un modo de razonamiento en el que Claude Opus genera un
proceso de pensamiento interno antes de producir la respuesta final. Se activa
incluyendo el parámetro thinking en la llamada a la API de Anthropic
con el tipo enabled y un budget_tokens que define el
máximo de tokens que el modelo puede usar para razonar. El razonamiento interno
puede incluirse en la respuesta (el campo thinking en el output)
o mantenerse oculto. Cada token de thinking se factura como token de salida.
La documentación técnica completa está en
docs.anthropic.com.
Claude Opus 4.7 supera el 72% de tasa de resolución en SWE-bench Verified a mayo de 2026, el mejor resultado documentado entre modelos de proposito general disponibles via API. SWE-bench Verified mide la capacidad de resolver issues reales de GitHub en proyectos Python con tests automatizados — el benchmark más representativo para coding autónomo en condiciones de producción. Los números exactos se actualizan con cada iteración del modelo; consulta la model card oficial de Anthropic para los datos más recientes.
Claude Opus 4.7 está disponible a traves de cuatro vias principales:
la API de Anthropic (acceso directo con SDK Python o TypeScript),
Claude.ai (interfaz web con planes Pro, Team y Enterprise),
Amazon Bedrock (para infraestructura AWS) y
Google Cloud Vertex AI (para infraestructura GCP). El identificador
de modelo en la API es claude-opus-4-7-20260512 o el alias
claude-opus-4-7-latest. En Claude.ai, Opus está disponible en
planes Pro y superiores, con posible limitación de uso mensual.
Depende del caso de uso. La respuesta practica: usa Sonnet por defecto y reserva Opus para los pasos donde el error tiene consecuencias directas. Si trabajas en análisis de documentos críticos (legales, financieros, medicos), arquitectura de sistemas con restricciones complejas, investigación que requiere síntesis de fuentes contradictorias, o auditoría de código de seguridad — Opus justifica su precio. Si la tarea es coding rutinario, redacción de contenido estándar o ejecución de flujos de agente bien definidos, Sonnet ofrece calidad equivalente a un tercio del coste. La estrategia de tiers — Haiku para clasificar, Sonnet para ejecutar, Opus para decidir — es la más eficiente en producción.