- Claude tiene tres modelos con precios diferenciados: Haiku 4.5 ($1/$5), Sonnet 4.6 ($3/$15) y Opus 4.7 ($5/$25) por millón de tokens de entrada/salida.
- El prompt caching reduce el coste de tokens de entrada en cache un 90%, con TTL configurable de 5 minutos o 1 hora — la palanca de ahorro más potente para flujos repetitivos.
- La Batches API ofrece un 50% de descuento sobre los precios base para procesamiento asincrono no urgente, con resultados disponibles en menos de 24 horas.
- En AWS Bedrock y Google Cloud Vertex AI se aplican los mismos precios por token, aunque la facturación se gestiona directamente con el proveedor de nube.
- Claude Code está incluido en los planes Max de Claude.ai ($100/mes o $200/mes) y consume tokens de API en modo de facturación directa por uso.
Introducción al sistema de precios de Claude
Anthropic ofrece acceso a Claude a traves de dos superficies de precios distintas: la API de pago por uso, orientada a desarrolladores y empresas que integran Claude en productos propios, y los planes de consumidor de Claude.ai, orientados a usuarios finales que trabajan directamente con la interfaz web o con Claude Code. La elección entre uno y otro determina tanto el modelo de coste como los limites de uso disponibles.
Para equipos que construyen sobre la API de Claude, el coste depende exclusivamente de los tokens consumidos — la unidad básica de texto que el modelo procesa y genera. Un token equivale aproximadamente a cuatro caracteres o tres cuartos de una palabra en ingles; en español, con palabras más largas, la equivalencia se acerca a 1 token por cada 3-4 caracteres. Los precios se publican en dolares por millón de tokens (MTok) y se aplican por separado a tokens de entrada (lo que se le envía al modelo) y tokens de salida (lo que el modelo genera).
Anthropic publica sus precios de referencia en anthropic.com/pricing. Los mismos precios por token se aplican en AWS Bedrock y Google Cloud Vertex AI, aunque en esas plataformas la facturación se procesa a traves del proveedor de nube. El acceso a traves de estos proveedores puede incluir compromisos de gasto o descuentos por volumen negociados con el proveedor, independientemente de los precios base de Anthropic.
Precios de la API por modelo (mayo 2026)
Precios vigentes a mayo de 2026. Contexto: Haiku 200K tokens, Sonnet y Opus 1M tokens. Los precios se expresan en dolares por millón de tokens (MTok).
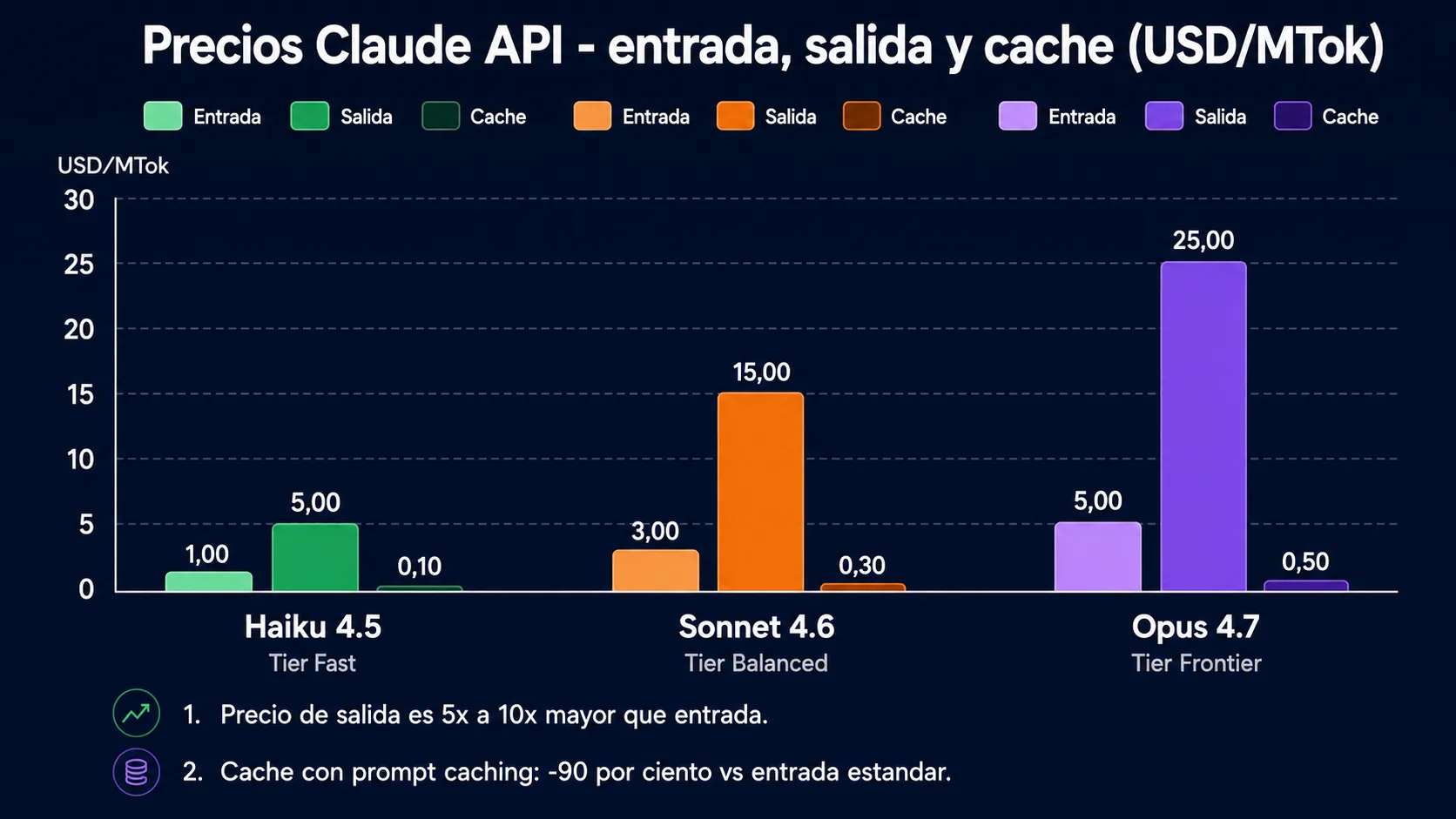
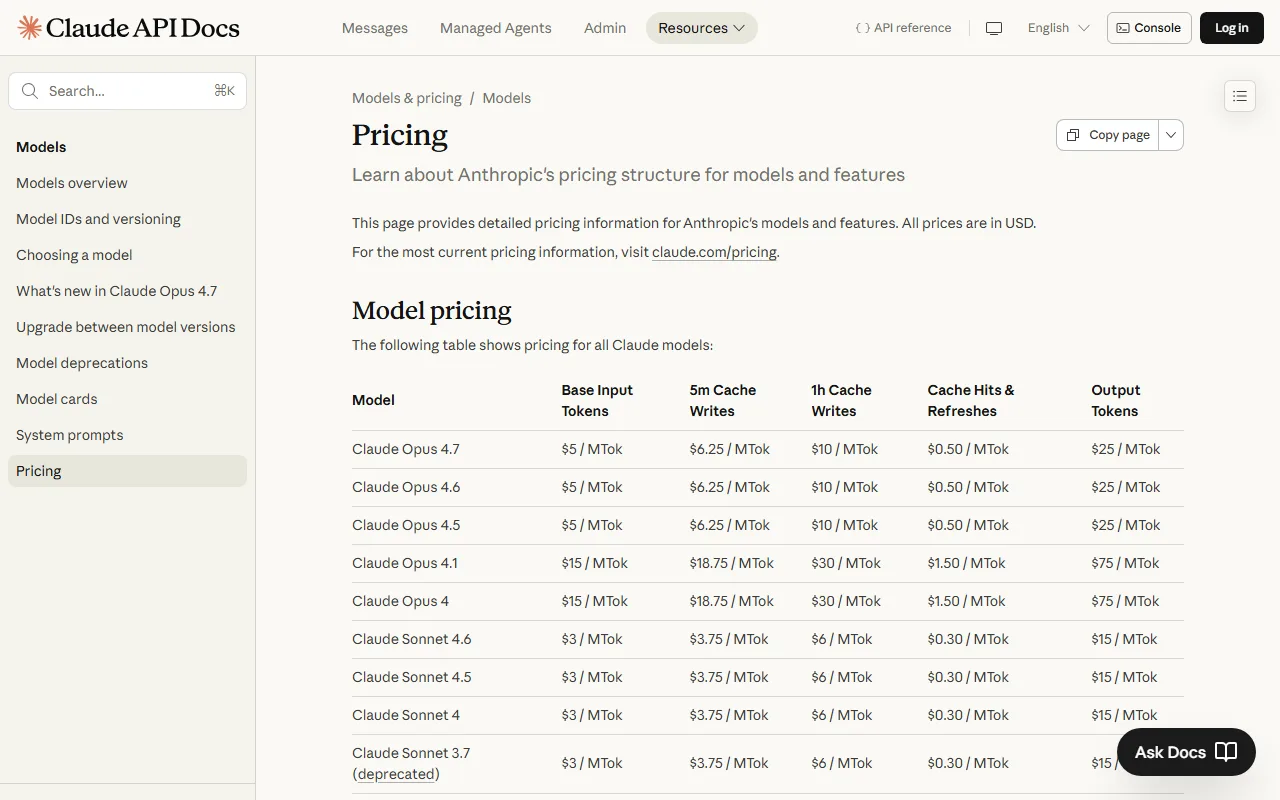
| Modelo | Tier | Entrada (MTok) | Salida (MTok) | Entrada en cache (MTok) | Contexto |
|---|---|---|---|---|---|
|
Claude Opus 4.7
Frontier — máxima capacidad
|
Frontier | $5.00 | $25.00 | $0.50 | 1M |
|
Claude Sonnet 4.6
Balanced — producción y agentes
|
Balanced | $3.00 | $15.00 | $0.30 | 1M |
|
Claude Haiku 4.5
Fast — alto volumen y latencia baja
|
Fast | $1.00 | $5.00 | $0.10 | 200K |
Los precios de entrada en cache se aplican cuando el prompt caching está activo y los tokens proceden de la cache del servidor de Anthropic. La escritura en cache tiene un coste adicional de 1.25x (TTL 5 min) o 2x (TTL 1 hora) sobre el precio de entrada base — un coste puntual que se amortiza desde la segunda petición que reutiliza ese prefijo.
Para el cálculo detallado del coste de un agente IA en producción, considera tanto los tokens de entrada (incluyendo historial de conversación y contexto del sistema) como los tokens de salida (generalmente mucho menores en volumen pero con precio 5x superior en Opus). Para la mayoría de agentes de producción, Sonnet 4.6 ofrece el mejor equilibrio coste-capacidad.
Planes Free, Pro, Max, Team y Enterprise
Para usuarios de Claude.ai y equipos que trabajan con la interfaz web o Claude Code sin facturación directa por token.
| Plan | Precio | Modelos incluidos | Limites de uso | Características destacadas |
|---|---|---|---|---|
|
Free
Sin tarjeta de credito
|
$0 | Sonnet, Haiku | Limitado diariamente | Acceso web básico, proyectos, artefactos |
|
Pro
Individual
|
$20 / mes | Sonnet ilimitado, Opus (limite) | 5x más que Free | Claude Code, acceso prioritario, proyectos avanzados |
|
Max ($100)
Individual — uso alto
|
$100 / mes | Sonnet ilimitado, Opus amplio | 5x más que Pro | Extended thinking, Claude Code incluido, acceso prioritario |
|
Max ($200)
Individual — uso máximo
|
$200 / mes | Sonnet ilimitado, Opus muy amplio | 20x más que Pro | Máximos limites de Opus, extended thinking, Claude Code |
|
Team
Para equipos
|
$30 / usuario / mes | Sonnet y Opus (limites compartidos) | Limites por equipo | Espacios de trabajo compartidos, permisos por rol, facturación centralizada |
|
Enterprise
Para organizaciones
|
Precio personalizado | Todos los modelos | Limites negociados | SSO, SAML, políticas de datos, SLA, soporte dedicado, acceso API incluido |
Los planes de consumidor no se facturan por token — el uso está incluido dentro de los limites del plan. Para equipos de desarrollo que construyen productos con Claude, la facturación directa por API es habitualmente más económica que comprar múltiples planes individuales, excepto para usuarios de Claude Code que consumen muchos tokens de manera sostenida y prefieren un coste mensual predecible.
Prompt caching — como funciona y cuanto ahorra
El prompt caching es la palanca de ahorro más importante disponible en la API de Claude. Permite que Anthropic almacene un prefijo de prompt — típicamente el prompt de sistema, el historial de conversación o documentos de referencia — en la cache del servidor durante un periodo de tiempo determinado. Las peticiones posteriores que reutilizan ese mismo prefijo pagan un 90% menos por los tokens de entrada en cache en lugar del precio completo.
Como activar el prompt caching
Para activar el caching, se aniade la propiedad cache_control al bloque
de contenido que marca el limite del prefijo que se quiere almacenar. Anthropic cachea
todo el contenido que precede a ese marcador. El TTL (tiempo de vida en cache) es de
5 minutos por defecto o 1 hora con ttl: "1h". El número máximo de
puntos de marcado por petición es cuatro.
Cálculo de ahorro con prompt caching
Para ilustrar el ahorro, considera un agente basado en Sonnet 4.6 que procesa 1.000 consultas diarias con un prompt de sistema de 10.000 tokens (comun en asistentes con muchas instrucciones o documentos de referencia) y genera una respuesta media de 500 tokens por consulta:
| Concepto | Sin caching | Con caching (TTL 5 min) |
|---|---|---|
| Tokens de entrada (sistema, 1.000 peticiones) | 10.000.000 tokens a $3.00/MTok = $30.00 | 10.000 tokens nuevos + 9.990.000 en cache a $0.30/MTok = $3.00 |
| Tokens de salida (500 tokens x 1.000) | 500.000 tokens a $15.00/MTok = $7.50 | 500.000 tokens a $15.00/MTok = $7.50 |
| Coste diario total | $37.50 | $10.50 |
| Ahorro | — | 72% de ahorro — $27 menos al día |
El ahorro es proporcional al tamaño del prefijo fijo respecto al total de tokens de entrada. Cuanto más grande sea el prompt de sistema o el contexto compartido, mayor será el porcentaje de ahorro. En agentes con RAG (recuperación de documentos) donde el contexto incluye varios documentos de referencia de decenas de miles de tokens, el ahorro puede superar el 80% del coste total de entrada.
La documentación técnica completa sobre como implementar prompt caching está disponible en docs.anthropic.com.
Batches API — 50% de descuento para procesamiento masivo
La Batches API (API de lotes) permite enviar hasta 100.000 peticiones en un solo lote para procesamiento asincrono. A cambio de aceptar que los resultados no sean inmediatos (se entregan en menos de 24 horas, habitualmente en menos de 1 hora), Anthropic aplica un descuento del 50% sobre los precios base tanto en tokens de entrada como de salida.
- Hasta 100.000 peticiones por lote
- Hasta 256 MB por lote
- Resultados disponibles hasta 29 días
- Compatible con todas las funciones de la API de mensajes
- 50% de descuento sobre precios base
- Clasificación masiva de datos
- Generación de contenido en bulk
- Extracción de información de documentos
- Evaluaciones y testing de modelos
- Embeddings y procesamiento offline
- Opus 4.7: $2.50 entrada / $12.50 salida
- Sonnet 4.6: $1.50 entrada / $7.50 salida
- Haiku 4.5: $0.50 entrada / $2.50 salida
- Por millón de tokens con descuento del 50%
La Batches API y el prompt caching son compatibles y acumulables: puedes enviar un lote con peticiones que reutilizan un prefijo cacheado, aplicando simultaneamente el 50% de descuento del lote y el 90% de descuento sobre los tokens de cache. En flujos de trabajo de procesamiento masivo con contexto compartido — como analizar cientos de documentos con el mismo prompt de extracción — la combinación de ambas palancas puede reducir el coste efectivo por token de entrada por encima del 95% respecto al precio base sin optimización.
Estrategias de optimización de costes
Las palancas de reducción de coste más efectivas para equipos que trabajan con la API de Claude en producción.
cache_control al último bloque
del prefijo fijo. El ahorro es automático desde la segunda petición en la misma ventana
de 5 minutos.
max_tokens ajustado al tamaño de
respuesta esperado evita salidas innecesariamente largas. Para tareas de extracción
estructurada (JSON, clasificación, extracción de datos), 500-2.000 tokens son suficientes
en la gran mayoría de casos.
messages/count_tokens, que permite
contar los tokens de una petición antes de ejecutarla sin coste de inferencia. Usarlo
durante el desarrollo para entender el consumo real de tokens de los prompts de producción
evita sorpresas en la factura y permite dimensionar correctamente el presupuesto antes
de desplegar.
Comparativa de precios: Claude vs ChatGPT vs Gemini
Precios de API por millón de tokens a mayo de 2026. Comparativa referencial — consulta las páginas oficiales de cada proveedor para precios actualizados.
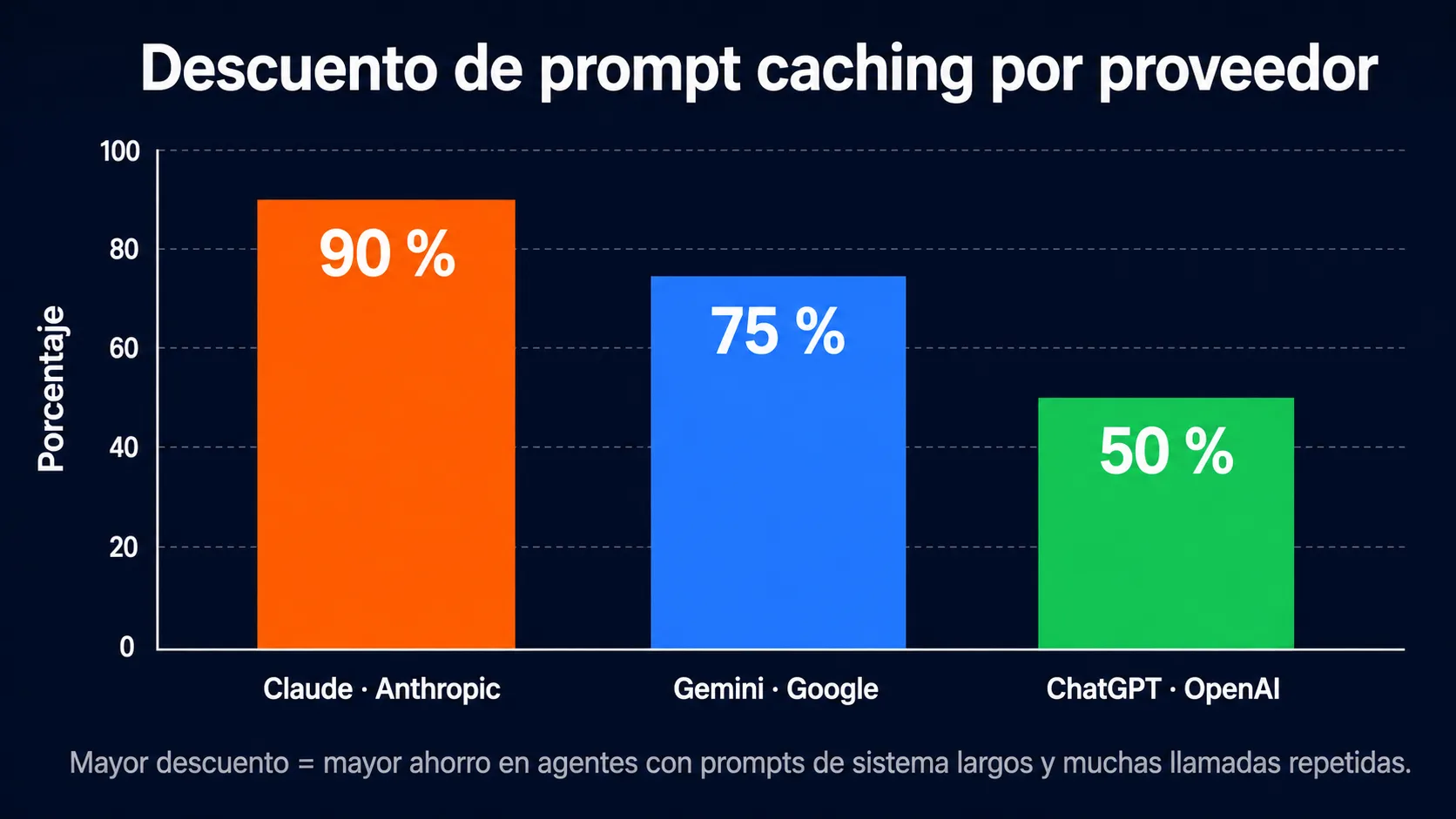
| Proveedor y modelo | Tier | Entrada (MTok) | Salida (MTok) | Contexto | Descuento caching |
|---|---|---|---|---|---|
| Claude Opus 4.7 (Anthropic) | Frontier | $5.00 | $25.00 | 1M | Si — 90% |
| Claude Sonnet 4.6 (Anthropic) | Balanced | $3.00 | $15.00 | 1M | Si — 90% |
| Claude Haiku 4.5 (Anthropic) | Fast | $1.00 | $5.00 | 200K | Si — 90% |
| GPT-4.5 (OpenAI) | Frontier | $5.00 | $15.00 | 128K | Si — 50% |
| GPT-5 (OpenAI) | Balanced | $2.50 | $10.00 | 128K | Si — 50% |
| GPT-4.1 nano (OpenAI) | Fast | $0.15 | $0.60 | 128K | Si — 50% |
| Gemini 3.1 Pro (Google) | Frontier | $2.00 | $12.00 | 2M | Si — 75% |
| Gemini 3.5 Flash (Google) | Fast | $1.50 | $9.00 | 1M | Si — 75% |
La comparativa de precios brutos sin contexto puede ser enganosa. Los factores que más influyen en el coste real en producción son: la eficiencia en tokens del modelo (cuantos tokens necesita para completar una tarea), la disponibilidad y porcentaje de descuento del caching (Claude ofrece el mayor descuento del sector con 90%), y la necesidad real de ventana de contexto grande (Claude Sonnet y Opus tienen 1M tokens, al nivel de Gemini, suficiente para la gran mayoría de casos de uso prácticos).
Para tareas de clasificación de alto volumen con modelos rápidos, GPT-4.1 nano y Gemini Flash-Lite ofrecen precios muy competitivos frente a Claude Haiku. Para agentes de producción con contextos largos y muchas peticiones repetidas, el 90% de descuento en caching de Claude suele resultar en el coste efectivo más bajo del mercado. La herramienta de calculadora de coste de agente IA permite comparar el coste real de cada proveedor ajustado a tu caso de uso específico.
Preguntas frecuentes sobre precios de Claude
¿Cuánto cuesta usar Claude Sonnet 4.6 por API?
A mayo de 2026, Claude Sonnet 4.6 cuesta $3 por millón de tokens de entrada y $15 por millón de tokens de salida. Con prompt caching activo, los tokens de entrada servidos desde cache cuestan $0.30 por millón (90% de descuento). La Batches API reduce ambos precios a la mitad para procesamiento diferido: $1.50 entrada y $7.50 salida.
Para estimar el coste de una petición concreta: un prompt de sistema de 5.000 tokens más una consulta de 200 tokens y una respuesta de 800 tokens cuesta aproximadamente (5.200 x $0.000003) + (800 x $0.000015) = $0.0156 + $0.012 = $0.0276 por petición. Con caching del prompt de sistema, el coste baja a aproximadamente $0.004 + $0.012 = $0.016 por petición.
¿Qué diferencia hay entre los planes Pro y Max de Claude?
El plan Pro ($20/mes) incluye uso ilimitado de Claude Sonnet con acceso a Opus dentro de limites moderados, además de Claude Code y acceso prioritario al servicio. Es suficiente para la mayoría de usuarios individuales con uso diario normal.
El plan Max ($100/mes) ofrece 5x más uso que Pro, con limites de Opus significativamente más altos y extended thinking sin restricciones. El plan Max ($200/mes) multiplica por 20 el uso base de Pro y es el plan recomendado para desarrolladores que usan Claude Code de forma intensiva como herramienta principal de trabajo. Ambas variantes Max incluyen Claude Code sin coste adicional por token.
¿Cómo funciona el prompt caching de Claude y cuánto ahorra?
El prompt caching almacena el prefijo de un prompt en los servidores de Anthropic durante 5 minutos (o 1 hora con TTL extendido). Las peticiones posteriores que comienzan con el mismo prefijo no procesan esos tokens de nuevo — los sirven desde cache al 10% del precio normal.
El ahorro es mayor cuanto más grande sea el prefijo fijo (prompt de sistema, documentos RAG, historial de conversación) respecto al total de tokens. Para un agente con 10.000 tokens de sistema y 1.000 consultas diarias en Sonnet 4.6, el ahorro típico es del 72-80% del coste total de tokens de entrada — de $30/dia a menos de $10/dia en ese escenario.
Es Claude más barato que ChatGPT de OpenAI?
Depende del caso de uso específico. En precio bruto por token, GPT-4.1 nano y Gemini Flash-Lite son más baratos para clasificación de alto volumen. Claude Sonnet 4.6 ($3/$15) es comparable a GPT-5.4 ($1.25/$10, más barato) y a Gemini 3.1 Pro ($2/$12). Claude Opus 4.7 ($5/$25) es similar en coste a Gemini 3.1 Pro aunque con diferente estructura de precios de salida.
Donde Claude tiene una ventaja estructural es en el descuento de caching del 90% frente al 50% de OpenAI y el 75% de Google. En aplicaciones con prompts de sistema largos y muchas peticiones por sesión, Claude puede resultar el más económico del mercado para el mismo nivel de capacidad, una vez aplicado el caching. La comparativa es siempre dependiente del perfil de uso específico — la calculadora de coste de agente IA permite hacer el cálculo ajustado a tu caso.
Puedo usar Claude gratis sin tarjeta de credito?
Si. Claude.ai ofrece un plan gratuito que no requiere tarjeta de credito e incluye acceso limitado a Claude Sonnet y Haiku a traves de la interfaz web. Los limites diarios del plan gratuito se reinician cada día y son suficientes para exploración y uso ocasional.
Para acceso a la API, Anthropic suele incluir creditos iniciales en cuentas nuevas que permiten experimentar con la API antes de introducir información de facturación. Para uso de producción sostenido es necesario configurar un método de pago en la consola de Anthropic. La documentación de inicio de la API está en docs.anthropic.com.
¿Cómo se factura Claude Code?
Claude Code puede operar bajo dos modalidades de facturación:
- Con plan Max de Claude.ai: el uso de Claude Code está incluido dentro de los limites del plan ($100/mes o $200/mes) sin coste adicional por token. Es la opción más predecible en coste para desarrolladores individuales con uso intensivo.
- Con API de Anthropic directa: Claude Code consume tokens de la cuenta de API configurada, facturandose a los mismos precios que cualquier otra llamada. Anthropic recomienda Sonnet 4.6 como modelo base para Claude Code por su equilibrio entre capacidad y coste, aunque puede configurarse para usar Opus en tareas que lo requieran.
Para equipos de desarrollo con varios ingenieros usando Claude Code activamente, la facturación directa por API con Sonnet 4.6 y prompt caching suele ser más económica que múltiples planes Max individuales una vez superado el uso promedio diario de unos 2-3 millones de tokens por desarrollador.
Calcula el coste real de tu agente con Claude
Los precios por token son el punto de partida. La calculadora de coste de agente IA tiene en cuenta el prompt de sistema, el número de herramientas, el historial de conversación, el prompt caching y el volumen de peticiones para darte una estimación mensual ajustada a tu caso de uso específico.
Abrir calculadora de costes