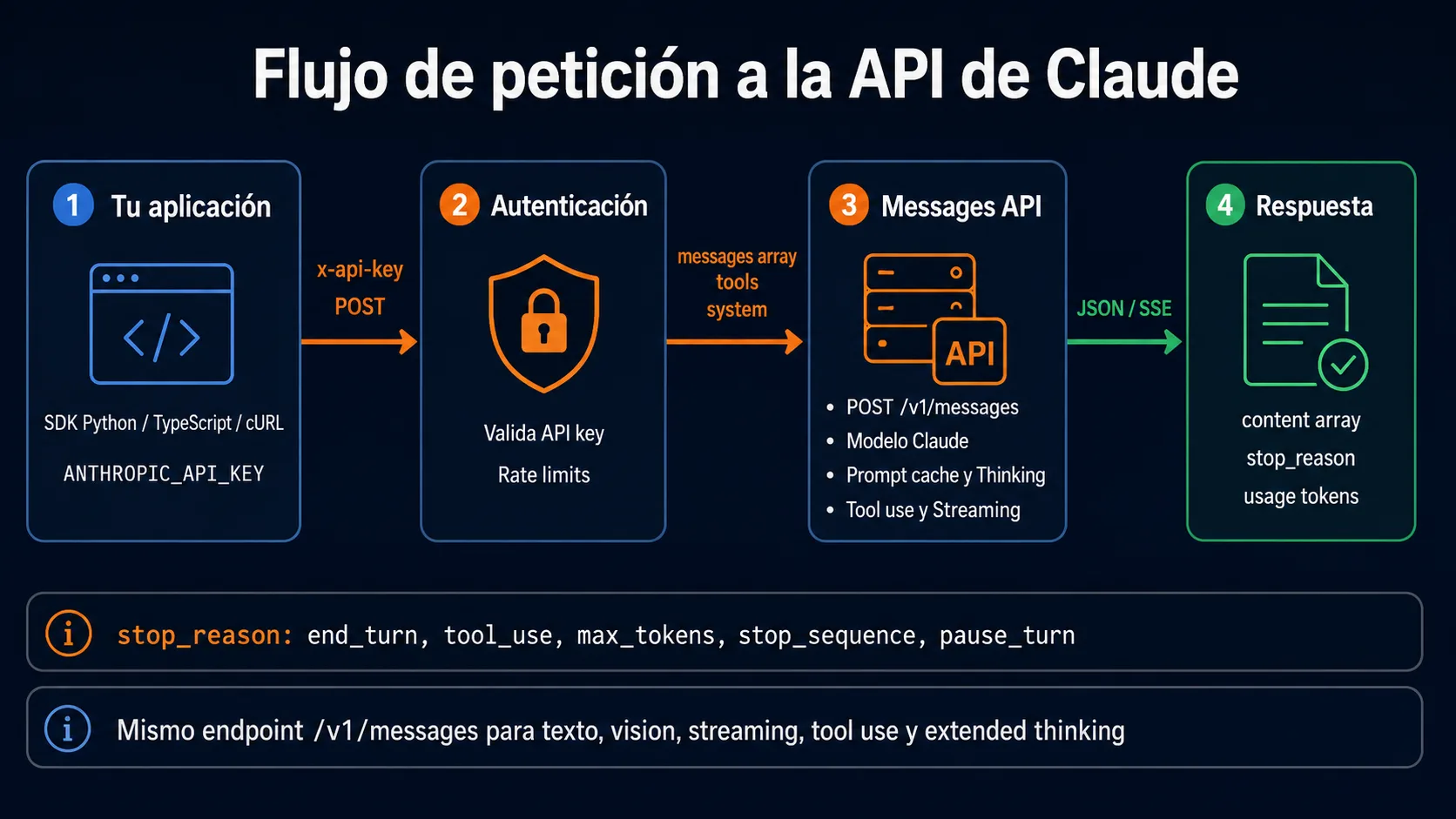
- La Messages API (
POST /v1/messages) es el único endpoint necesario para acceder a todas las capacidades de Claude: texto, visión, streaming, tool use y extended thinking. - Los SDKs oficiales para Python (
pip install anthropic) y TypeScript (npm install @anthropic-ai/sdk) simplifican la autenticación, el manejo de errores y el streaming sin tener que gestionar HTTP manualmente. - El prompt caching reduce el coste de los tokens cacheados aproximadamente un 90%, lo que es crítico para agentes con system prompts largos que se repiten en cada llamada.
- La API está disponible directamente en
api.anthropic.com, vía Amazon Bedrock y vía Google Vertex AI, permitiendo integración en infraestructuras cloud existentes sin cambiar el código de aplicación. - Los rate limits escalan desde 40 RPM en el tier gratuito hasta 4000 RPM en tiers de pago; el precio se factura por token consumido sin costes fijos ni suscripciones obligatorias.
¿Qué es la API de Claude?
La API de Claude es la interfaz REST que Anthropic pone a disposición de desarrolladores y empresas para acceder programáticamente a sus modelos de lenguaje. A diferencia de Claude.ai — el interfaz de chat para usuarios finales —, la API está diseñada para integración en código: puedes llamarla desde cualquier aplicación, automatizarla en pipelines y combinarla con herramientas externas para construir agentes autónomos.
El diseño de la API sigue un principio de simplicidad deliberada: existe un único endpoint
principal (POST /v1/messages) desde el que se accede a todas las capacidades
del modelo. No hay endpoints separados para visión, streaming, tool use o extended thinking;
todas estas funcionalidades son parámetros del mismo endpoint. Esto simplifica la integración
y garantiza que cualquier cliente que sepa construir una petición básica puede acceder a las
capacidades avanzadas sin cambiar la arquitectura de su código.
Los modelos disponibles a través de la API son Claude Opus 4.7 (frontier,
$5/$25 por MTok), Claude Sonnet 4.6 (producción, $3/$15 por MTok) y Claude Haiku 4.5
(rápido y económico, $1/$5 por MTok). Los tres comparten la misma interfaz de API, por lo
que cambiar de modelo es tan sencillo como modificar el parámetro model en la
petición. Para una comparativa detallada de modelos y sus casos de uso óptimos, consulta
la guía de Claude AI.
La documentación oficial de Anthropic para la API está disponible en docs.anthropic.com. Esta guía cubre los mismos conceptos con ejemplos de código adicionales, explicaciones de los trade-offs entre opciones y contexto práctico para tomar decisiones de implementación.
Primeros pasos: API key y primera petición
Desde registrarse hasta ejecutar tu primera llamada a la API en menos de cinco minutos.
1. Obtener una API key
Las API keys se generan desde console.anthropic.com. Es necesario crear una cuenta (puede ser cuenta gratuita para empezar), ir a la sección "API Keys" y pulsar "Create Key". La clave se muestra una sola vez en el momento de creación; guarda una copia en un lugar seguro.
Por seguridad, nunca incluyas la API key directamente en el código fuente. Almacénala como variable de entorno:
# Linux / macOS
export ANTHROPIC_API_KEY="sk-ant-..."
# Windows PowerShell
$env:ANTHROPIC_API_KEY = "sk-ant-..."
# .env (con python-dotenv o dotenv en Node.js)
ANTHROPIC_API_KEY=sk-ant-...2. Primera petición con cURL
Puedes verificar que la API key funciona con una petición cURL directa antes de instalar ningún SDK:
curl https://api.anthropic.com/v1/messages \
-H "Content-Type: application/json" \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 1024,
"messages": [
{"role": "user", "content": "Hola Claude. Explica que es una API REST en dos frases."}
]
}'3. Primera petición con Python SDK
pip install anthropicimport anthropic
# Lee ANTHROPIC_API_KEY del entorno automaticamente
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[
{"role": "user", "content": "Hola Claude. Explica que es una API REST en dos frases."}
]
)
# response.content es una lista de bloques de contenido
for block in message.content:
if block.type == "text":
print(block.text)4. Primera petición con TypeScript SDK
npm install @anthropic-ai/sdkimport Anthropic from "@anthropic-ai/sdk";
// Lee ANTHROPIC_API_KEY del entorno automaticamente
const client = new Anthropic();
const message = await client.messages.create({
model: "claude-sonnet-4-6",
max_tokens: 1024,
messages: [
{ role: "user", content: "Hola Claude. Explica que es una API REST en dos frases." }
],
});
// Iterar sobre los bloques de contenido y comprobar el tipo antes de acceder a .text
for (const block of message.content) {
if (block.type === "text") {
console.log(block.text);
}
}Messages API — Formato de petición y respuesta
Todo lo que acepta y devuelve el endpoint POST /v1/messages.
Headers requeridos
Toda petición a la API de Claude necesita estos tres headers:
| Header | Valor | Descripción |
|---|---|---|
Content-Type |
application/json |
Siempre requerido |
x-api-key |
Tu API key | Autenticación; nunca en código fuente |
anthropic-version |
2023-06-01 |
Fija la versión de la API para compatibilidad |
Parámetros del cuerpo de la petición
| Parámetro | Tipo | Requerido | Descripción |
|---|---|---|---|
| model | string | Sí | ID del modelo: claude-opus-4-7, claude-sonnet-4-6, claude-haiku-4-5 |
| messages | array | Sí | Array de mensajes con role (user/assistant) y content |
| max_tokens | integer | Sí | Límite máximo de tokens de salida; Claude puede devolver menos |
| system | string | No | Prompt de sistema que define el comportamiento y contexto del modelo |
| tools | array | No | Definiciones de herramientas (tool use / function calling) |
| stream | boolean | No | Si true, la respuesta llega como Server-Sent Events |
| thinking | object | No | Activa extended thinking; en modelos 4.6+: {"type": "adaptive"} |
| output_config | object | No | Configuración de salida: effort (low/medium/high/max) y formato estructurado |
| cache_control | object | No | Activa prompt caching en el último bloque cacheable de la petición |
Estructura de la respuesta
La API devuelve un objeto JSON con los siguientes campos principales:
{
"id": "msg_01XFDUDYJgAACzvnptvVoYEL",
"type": "message",
"role": "assistant",
"content": [
{
"type": "text",
"text": "Una API REST es una interfaz que permite..."
}
],
"model": "claude-sonnet-4-6-20250929",
"stop_reason": "end_turn",
"stop_sequence": null,
"usage": {
"input_tokens": 42,
"output_tokens": 87,
"cache_creation_input_tokens": 0,
"cache_read_input_tokens": 0
}
}Valores de stop_reason
El campo stop_reason indica por qué el modelo dejó de generar:
- end_turn — el modelo completó su respuesta de forma natural.
- max_tokens — se alcanzó el límite de
max_tokens; la respuesta puede estar truncada. - tool_use — el modelo quiere usar una herramienta; debes procesarla y continuar la conversación.
- stop_sequence — la respuesta alcanzó una secuencia de parada personalizada.
- pause_turn — el modelo pausó en herramientas del lado del servidor; reenviar el contexto para continuar.
Funcionalidades avanzadas de la API de Claude
Tool use, visión, streaming, extended thinking y prompt caching: el conjunto completo de
capacidades disponibles en el mismo endpoint /v1/messages.
Tool use (function calling)
La API de Claude permite definir herramientas con nombre, descripción y esquema JSON de
entradas. El modelo decide cuándo llamar a cada herramienta, devuelve una respuesta con
stop_reason: "tool_use" e incluye un bloque tool_use en el
contenido con los argumentos. El desarrollador ejecuta la herramienta en su propio código
y devuelve el resultado en un nuevo mensaje con rol user de tipo
tool_result. Claude puede llamar a múltiples herramientas en paralelo dentro
de un mismo turno.
import anthropic
import json
client = anthropic.Anthropic()
tools = [
{
"name": "obtener_clima",
"description": "Devuelve el clima actual de una ciudad.",
"input_schema": {
"type": "object",
"properties": {
"ciudad": {
"type": "string",
"description": "Nombre de la ciudad, por ejemplo Madrid"
}
},
"required": ["ciudad"]
}
}
]
messages = [{"role": "user", "content": "Como esta el clima en Barcelona hoy?"}]
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
tools=tools,
messages=messages
)
# Si Claude quiere usar la herramienta:
if response.stop_reason == "tool_use":
tool_block = next(b for b in response.content if b.type == "tool_use")
# Ejecutar la herramienta con los argumentos que propone Claude
resultado = f"En {tool_block.input['ciudad']}: 22 C, parcialmente nublado."
# Devolver el resultado al modelo para que genere la respuesta final
messages.append({"role": "assistant", "content": response.content})
messages.append({
"role": "user",
"content": [{
"type": "tool_result",
"tool_use_id": tool_block.id,
"content": resultado
}]
})
respuesta_final = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
tools=tools,
messages=messages
)
print(respuesta_final.content[0].text)Visión — entrada de imágenes
Todos los modelos Claude actuales aceptan imágenes en el array content de
los mensajes. Las imágenes pueden enviarse como URL pública o codificadas en base64 con
el tipo MIME correspondiente. Claude analiza diagramas, capturas de pantalla, documentos
escaneados, gráficos y cualquier contenido visual junto con el texto de la petición.
Claude Opus 4.7 soporta resolución hasta 2576 px en el lado largo, lo que mejora la
precisión en computer use y análisis de documentos.
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "url",
"url": "https://ejemplo.com/diagrama.png"
}
},
{
"type": "text",
"text": "Describe este diagrama y explica el flujo de datos."
}
]
}]
)Streaming — respuesta progresiva
Con streaming activado (stream: true o método .stream() del
SDK), los tokens llegan al cliente a medida que el modelo los genera en lugar de esperar
a que la respuesta completa esté lista. Esto mejora la experiencia de usuario percibida
en aplicaciones de chat, reduce el riesgo de timeouts en respuestas largas y es
obligatorio para valores de max_tokens superiores a aproximadamente 16.000
en llamadas no streaming. Los eventos SSE del streaming siguen el formato
content_block_delta.
# El SDK expone .stream() como context manager
with client.messages.stream(
model="claude-sonnet-4-6",
max_tokens=4096,
messages=[{"role": "user", "content": "Escribe una guia sobre APIs REST."}]
) as stream:
# Iteracion sobre tokens de texto en tiempo real
for texto in stream.text_stream:
print(texto, end="", flush=True)
# Mensaje final con uso de tokens disponible tras cerrar el stream
mensaje_final = stream.get_final_message()
print(f"\nTokens de salida: {mensaje_final.usage.output_tokens}")Extended thinking — razonamiento paso a paso
El extended thinking permite que Claude dedique tiempo de computación adicional a
razonar antes de generar la respuesta final. En los modelos Claude 4.6 y 4.7 se activa
con thinking: {"type": "adaptive"}, que deja al modelo decidir cuándo y
cuánto razonar de forma autónoma. El parámetro output_config.effort
(low / medium / high / max) controla la profundidad del razonamiento y el gasto en
tokens. Los bloques de pensamiento aparecen en el campo content de la
respuesta con type: "thinking" antes del bloque de texto final.
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=16000,
thinking={"type": "adaptive"},
output_config={"effort": "high"},
messages=[{
"role": "user",
"content": "Analiza los pros y contras de arquitecturas de microservicios vs monolito para una startup."
}]
)
for block in response.content:
if block.type == "thinking":
print(f"[Razonamiento interno]\n{block.thinking}\n")
elif block.type == "text":
print(f"[Respuesta]\n{block.text}")Prompt caching — reducción de costes hasta el 90%
El prompt caching permite reutilizar partes del contexto entre llamadas consecutivas.
Cuando una parte del prompt (system prompt, instrucciones del agente, documentos de
referencia) no cambia entre peticiones, el modelo puede servir esos tokens desde caché
al coste de aproximadamente el 10% del precio normal. Para activarlo, se añade
cache_control: {"type": "ephemeral"} en los bloques de contenido que
permanecen constantes. El TTL por defecto es 5 minutos; existe opción de 1 hora.
El campo usage.cache_read_input_tokens en la respuesta confirma cuántos
tokens se sirvieron desde caché en cada llamada.
system_prompt_largo = """
Eres un asistente especializado en analisis financiero.
[... miles de tokens de instrucciones y contexto ...]
"""
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[{
"type": "text",
"text": system_prompt_largo,
"cache_control": {"type": "ephemeral"} # TTL 5 min por defecto
}],
messages=[{"role": "user", "content": "Cual es el EBITDA de la empresa del informe?"}]
)
# Verificar tokens servidos desde cache
print(f"Tokens de entrada normales: {response.usage.input_tokens}")
print(f"Tokens de cache creados: {response.usage.cache_creation_input_tokens}")
print(f"Tokens leidos de cache: {response.usage.cache_read_input_tokens}")Batches API — procesamiento asíncrono a mitad de precio
La Batches API (POST /v1/messages/batches) permite enviar hasta 100.000
peticiones en un solo lote para procesamiento asíncrono a un 50% del precio normal de
la API. Es ideal para tareas que no requieren respuesta en tiempo real: clasificación
de grandes volúmenes de texto, generación de contenido masiva, análisis de datasets o
extracción de información de miles de documentos. Los resultados están disponibles
durante 29 días y se pueden recuperar en cualquier momento tras la finalización del
lote, que suele completarse en menos de una hora.
Tabla de precios de la API de Claude — mayo 2026
Precios en dólares por millón de tokens (MTok). Confirma en anthropic.com/pricing antes de calcular costes de producción.
| Modelo | Tier | Input ($/MTok) | Cache write ($/MTok) | Cache read ($/MTok) | Output ($/MTok) | Contexto |
|---|---|---|---|---|---|---|
| Claude Haiku 4.5 | Fast | $1,00 | $1,25 | $0,10 | $5,00 | 200K |
| Claude Sonnet 4.6 | Balanced | $3,00 | $3,75 | $0,30 | $15,00 | 1M |
| Claude Opus 4.7 | Frontier | $5,00 | $6,25 | $0,50 | $25,00 | 1M |
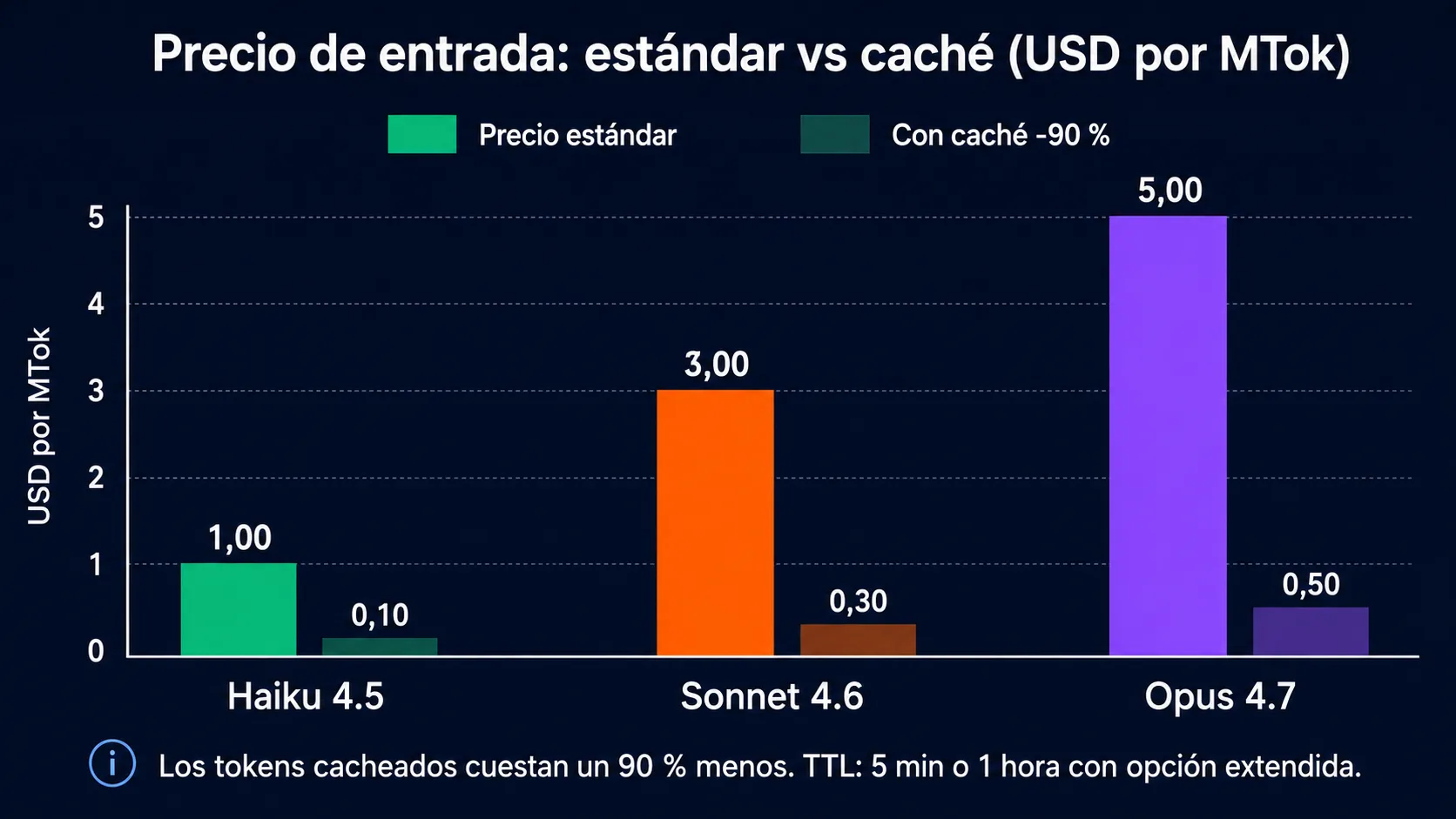
Cálculo de coste real con prompt caching
El coste real por llamada en un agente en producción es significativamente menor que el precio nominal de entrada cuando se usa prompt caching. Ejemplo con Claude Sonnet 4.6:
- System prompt de 10.000 tokens que no cambia entre llamadas
- Sin caching: 10.000 tokens x $3/MTok = $0,03 por llamada solo de system prompt
- Con caching (lectura): 10.000 tokens x $0,30/MTok = $0,003 por llamada
- Ahorro del 90% en cada llamada tras la escritura inicial en caché
Para ver una guía detallada de precios de Claude con calculadoras de coste y estrategias de optimización, consulta la sección dedicada.
Rate limits de la API de Claude por tier
Los límites de uso se aplican por modelo y por cuenta. Aumentan automáticamente con el gasto acumulado o mediante solicitud a Anthropic para casos de uso específicos.
| Tier | Requisito | RPM | ITPM | OTPM |
|---|---|---|---|---|
| Free | Sólo registro | 40 | 40.000 | 8.000 |
| Tier 1 | $5 gastados | 60 | 80.000 | 16.000 |
| Tier 2 | $500 gastados | 2.000 | 2.000.000 | 400.000 |
| Tier 3 | $5.000 gastados | 4.000 | 4.000.000 | 800.000 |
| Enterprise | Contrato directo | Personalizado | Personalizado | Personalizado |
Cuando una petición supera el rate limit, la API devuelve un error HTTP 429 con un
header retry-after indicando cuántos segundos esperar. Los SDKs oficiales
de Anthropic incluyen reintentos automáticos con backoff exponencial configurables
mediante el parámetro max_retries del cliente.
SDKs e integraciones disponibles
Formas de acceder a la API de Claude desde distintos lenguajes y plataformas cloud.
Paquete oficial anthropic instalable vía pip. Soporta cliente síncrono
y asíncrono (AsyncAnthropic), streaming, tool runner beta con decorador
@beta_tool, helpers de structured outputs con Pydantic y
client.messages.parse(). Compatible con Python 3.8+.
pip install anthropicPaquete oficial @anthropic-ai/sdk para Node.js y entornos de borde
(Edge Runtime). Soporta cliente asincrono, streaming con .stream() y
finalMessage(), tool runner beta con Zod y betaZodTool,
helpers de structured outputs y tipado completo de todos los objetos de API.
npm install @anthropic-ai/sdkClaude disponible como modelo gestionado dentro de AWS Bedrock. Autenticación
mediante credenciales IAM de AWS; facturación consolidada con la cuenta de AWS.
Mismos modelos y capacidades que la API directa de Anthropic, con las ventajas
de la infraestructura y compliance de AWS. Los IDs de modelo tienen prefijo
anthropic. en Bedrock.
Claude disponible en Google Cloud Vertex AI Model Garden. Autenticación con credenciales de Google Cloud; facturación vía Google Cloud. Permite combinar Claude con otros servicios de GCP como BigQuery, Cloud Storage o Cloud Run sin enviar datos fuera del entorno de GCP. Disponible en varias regiones geográficas de Google Cloud.
Otros lenguajes: HTTP directo
La API de Claude es una API REST estándar accesible desde cualquier lenguaje o herramienta que pueda hacer peticiones HTTP con headers personalizados. Si no existe un SDK oficial para tu lenguaje (Go, Ruby, Java, PHP, C#), puedes usar la API directamente con tu librería HTTP de preferencia siguiendo el formato de petición documentado en docs.anthropic.com/es/api/messages. La comunidad mantiene SDKs no oficiales para varios lenguajes adicionales.
Preguntas frecuentes sobre la API de Claude
¿Cómo se autentica la API de Claude?
La API de Claude usa autenticación por API key enviada en el header HTTP
x-api-key de cada petición. Las claves se generan desde
console.anthropic.com
y tienen permisos a nivel de organización o de proyecto (workspace). Se recomienda
usar variables de entorno (ANTHROPIC_API_KEY) para almacenar la clave
y nunca incluirla directamente en el código fuente o en repositorios de control
de versiones.
¿Qué diferencia hay entre la API directa de Anthropic y Claude en Bedrock o Vertex?
La API directa de Anthropic (api.anthropic.com) ofrece acceso
inmediato a las últimas funcionalidades con autenticación por API key propia
de Anthropic y facturación directa. Amazon Bedrock y Google Vertex AI ofrecen
los mismos modelos Claude pero con autenticación e infraestructura de AWS o GCP
respectivamente, lo que facilita la integración en arquitecturas existentes y
puede simplificar el cumplimiento normativo al mantener los datos dentro del
entorno cloud del cliente. Nota: Managed Agents y algunas funcionalidades beta
avanzadas sólo están disponibles en la API directa de Anthropic.
¿Puedo probar la API sin coste?
Sí. Al registrarse en Anthropic, la cuenta obtiene acceso al tier gratuito con límites de 40 RPM y cuota de tokens reducida. Este tier es suficiente para desarrollo y pruebas de concepto. Para uso en producción con mayor volumen, es necesario añadir un método de pago en console.anthropic.com para pasar al Tier 1 (se desbloquea tras $5 de gasto) y tiers superiores.
¿Qué es la Anthropic Console y para qué sirve?
La Anthropic Console (console.anthropic.com) es el panel de administración de la API. Desde ahí puedes: generar y revocar API keys, ver el uso y gasto de tokens en tiempo real, configurar límites de gasto, acceder al Workbench para probar prompts de forma interactiva, gestionar workspaces de equipo y consultar los rate limits actuales de tu cuenta.
¿Cómo se usa la API para construir agentes con herramientas?
El ciclo básico de tool use con la API de Claude es: (1) definir las herramientas
con nombre, descripción y esquema JSON en el parámetro tools de la
petición; (2) Claude decide si usar alguna herramienta y devuelve una respuesta
con stop_reason: "tool_use" e instrucciones sobre qué argumentos
usar; (3) el desarrollador ejecuta la herramienta en su propio código; (4) el
resultado se devuelve al modelo como un mensaje tool_result para que
Claude pueda incorporarlo en su respuesta final. Los SDKs de Python y TypeScript
incluyen un tool runner beta que automatiza este ciclo.
¿Cuánto cuesta en la práctica usar Claude para un agente en producción?
El coste real depende mucho de cómo esté diseñado el agente. Un agente típico con Claude Sonnet 4.6 que tiene un system prompt de 5.000 tokens y realiza 20 pasos por tarea con ~500 tokens de contexto acumulado cada paso: sin caching el coste de entrada sería de aproximadamente $0,30 por tarea completa; con prompt caching en el system prompt, el coste de entrada se reduce a menos de $0,08. Para una estimación precisa de tu caso de uso específico, consulta la guía de precios de Claude con calculadora incluida.
Calcula el coste de la API de Claude para tu proyecto
Consulta la guía detallada de precios de Claude con ejemplos de coste por caso de uso, comparativa entre modelos y estrategias para reducir el gasto con prompt caching y Batches API.
Ver precios de Claude