- Ambas herramientas usan llama.cpp internamente — la diferencia de rendimiento bruto de tokens es mínima. Lo que varía es el overhead del sistema.
- Benchmarks de mayo 2026: Ollama produce 78 tok/s vs 64 tok/s de LM Studio con Llama 3.1 8B Q4_K_M en RTX 4090 — diferencia del ~18% debida al overhead de la GUI.
- LM Studio consume ~500 MB de RAM del sistema; Ollama ~100 MB. En modelos grandes, esta diferencia es insignificante.
- LM Studio da acceso a miles de cuantizaciones GGUF en Hugging Face; Ollama tiene ~200 modelos curados en su registro oficial.
- Ollama funciona en servidores Linux sin escritorio; LM Studio requiere entorno de escritorio (existe CLI experimental).
El motor compartido: llama.cpp
Entender la arquitectura interna de ambas herramientas explica por qué el rendimiento de inferencia es tan similar y dónde aparecen las diferencias reales.
Tanto LM Studio como Ollama delegan el trabajo de inferencia a llama.cpp, la implementación en C++ de Meta que permite ejecutar modelos cuantizados en hardware de consumo con soporte de aceleración CUDA, ROCm y Metal. Esto tiene una implicación fundamental: la velocidad de generación de tokens es arquitectónicamente idéntica en ambas herramientas para el mismo modelo, la misma cuantización y el mismo hardware. Las diferencias de rendimiento que se observan en benchmarks provienen exclusivamente del overhead del sistema — la interfaz gráfica, la gestión de procesos y cómo cada herramienta transfiere datos entre capas.
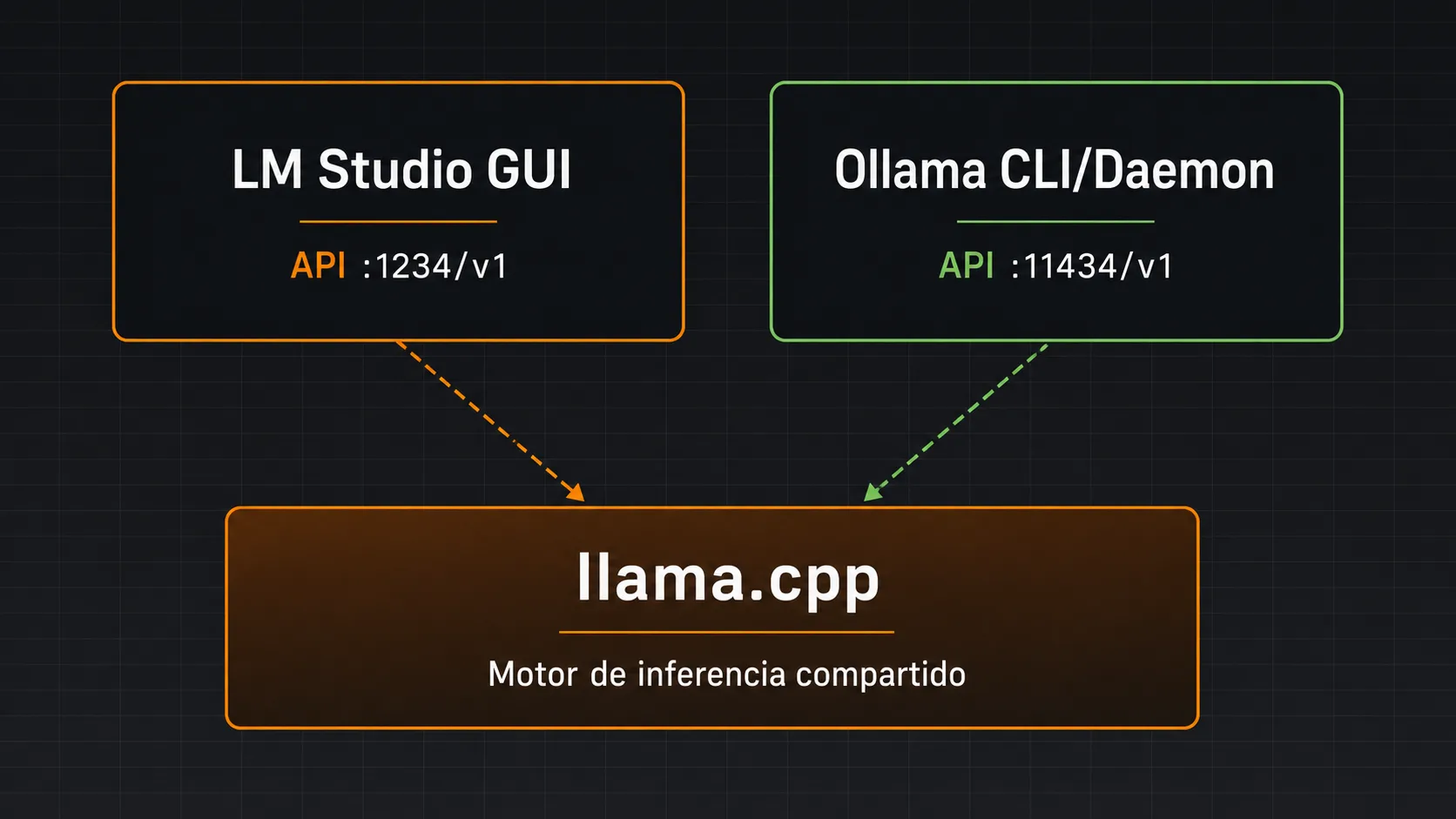
Esta arquitectura compartida tiene consecuencias prácticas importantes: los archivos GGUF son intercambiables entre ambas herramientas, los modelos descargados para LM Studio pueden importarse en Ollama directamente, y las optimizaciones de llama.cpp (CUDA graph, flash attention, KV cache) benefician a ambas por igual cuando se actualizan sus versiones del motor.
GUI frente a CLI: la diferencia más importante
La decisión entre LM Studio y Ollama empieza por entender cómo trabaja cada uno y qué tipo de usuario tiene en mente.
ollama pull, ollama run y ollama list.
Perfecto para servidores, Docker, scripts de automatización y cualquier
entorno donde la GUI no es una opción.
LM Studio introdujo en 2025 una interfaz de línea de comandos experimental (lms)
que permite arrancar el servidor sin abrir la aplicación de escritorio. Sin embargo,
sigue requiriendo que LM Studio esté instalado en el sistema. Ollama, en cambio, es
nativamente headless y puede ejecutarse en un servidor Linux mínimo sin escritorio
en cuestión de segundos.
Rendimiento medido: tokens por segundo
Los benchmarks de generación de tokens muestran diferencias reales pero moderadas. La causa no es el motor de inferencia sino el overhead del sistema.
| Hardware | Modelo | LM Studio (tok/s) | Ollama (tok/s) | Diferencia |
|---|---|---|---|---|
| RTX 4090 (24 GB) | Llama 3.1 8B Q4_K_M | 64 | 78 | +22% Ollama |
| RTX 3090 Ti (24 GB) | Llama 3.1 8B Q4_K_M | 48 | 55 | +15% Ollama |
| Apple M3 Max (36 GB) | Llama 3.1 8B Q4_K_M | 52 | 45 | +16% LM Studio (MLX) |
| RTX 4090 (24 GB) | Qwen2.5 7B Q4_K_M | 70 | 82 | +17% Ollama |
| RTX 3070 (8 GB) | Phi-3 Mini 3.8B Q4_K_M | 88 | 95 | +8% Ollama |
El dato notable es el rendimiento de LM Studio en Apple Silicon con modelos en formato MLX: cuando se usan variantes MLX (en lugar de GGUF), LM Studio supera a Ollama en macOS porque aprovecha optimizaciones específicas del compilador de Apple. Ollama usa llama.cpp/Metal para todos los modelos en macOS, mientras que LM Studio puede alternar entre llama.cpp/Metal y el backend MLX nativo.
Para hardware NVIDIA en Windows y Linux, Ollama es consistentemente más rápido entre un 8% y un 22% por el menor overhead del sistema. En la práctica, para la mayoría de aplicaciones esta diferencia no es perceptible — una respuesta que tarda 15 segundos con LM Studio tardaría 12,5 con Ollama.
Gestión de modelos: catálogo abierto vs registro curado
La forma en que cada herramienta gestiona modelos refleja su filosofía de diseño: LM Studio ofrece acceso amplio, Ollama ofrece acceso simplificado.
| Aspecto | LM Studio | Ollama |
|---|---|---|
| Fuente de modelos | Todos los GGUF de Hugging Face (miles de variantes) | Registro oficial de Ollama (~200 modelos curados) |
| Descarga | Buscador visual integrado en la app | ollama pull nombre:tag |
| Variantes de cuantización | Todas las disponibles en HuggingFace (Q2 a Q8, IQ, mixtas) | Las del registro oficial (normalmente Q4_0 o Q4_K_M por defecto) |
| Modelos personalizados | Carga directa de archivos GGUF locales | Requiere Modelfile para importar GGUF externos |
| Formatos soportados | GGUF + MLX (en macOS) | GGUF (safetensors con conversión) |
| Almacenamiento | ~/.cache/lm-studio/models/ |
~/.ollama/models/ |
| Intercambiabilidad | Los archivos GGUF son compatibles entre ambas herramientas | |
La ventaja de LM Studio en gestión de modelos es significativa para usuarios que necesitan acceder a cuantizaciones específicas (por ejemplo, IQ4_XS para máxima calidad en un presupuesto de VRAM ajustado) o modelos experimentales publicados recientemente en Hugging Face sin pasar por el proceso de curación del registro de Ollama. La desventaja es que la selección puede ser abrumadora para usuarios nuevos.
API compatible con OpenAI: diferencias técnicas
Ambas herramientas exponen una API compatible con OpenAI, pero con diferencias en los endpoints disponibles, el puerto por defecto y el soporte de características avanzadas.
| Endpoint | LM Studio (:1234) | Ollama (:11434) |
|---|---|---|
/v1/chat/completions |
Soportado | Soportado |
/v1/completions |
Soportado | Soportado |
/v1/embeddings |
Soportado | Soportado |
/v1/models |
Soportado | Soportado |
| Streaming SSE | Soportado | Soportado |
| Tool calling (función) | Soportado (según modelo) | Soportado (según modelo) |
| Modelos simultáneos | Uno a la vez (cambio manual) | Varios con gestión automática de cola |
| API nativa extendida | No | Endpoints propios (/api/generate, /api/ps) |
| Puerto por defecto | 1234 | 11434 |
Código de integración: cambiar entre LM Studio y Ollama
Dado que ambas APIs son compatibles con OpenAI, el cambio es de una sola línea en Python:
from openai import OpenAI
# LM Studio (puerto 1234)
cliente_lm = OpenAI(
base_url="http://localhost:1234/v1",
api_key="no-importa", # LM Studio no valida la API key
)
# Ollama (puerto 11434)
cliente_ollama = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama", # Ollama acepta cualquier cadena
)
# El código de la llamada es idéntico para ambos
respuesta = cliente_lm.chat.completions.create(
model="llama-3.1-8b-instruct", # nombre del modelo cargado
messages=[
{"role": "user", "content": "Explica el teorema de Bayes en dos frases."}
],
temperature=0.7,
max_tokens=256,
)
print(respuesta.choices[0].message.content)La diferencia principal en la integración es que LM Studio requiere cargar el modelo manualmente antes de recibir peticiones, mientras que Ollama carga el modelo automáticamente al recibir la primera petición si está disponible localmente. Esto hace a Ollama más adecuado para flujos donde el modelo puede cambiar entre peticiones.
Consumo de recursos: RAM, CPU en idle y VRAM
| Recurso | LM Studio (app abierta) | Ollama (servicio en fondo) |
|---|---|---|
| RAM del sistema | ~450–550 MB | ~80–120 MB |
| CPU en idle | 2–5% (rendering de UI) | < 0,5% |
| VRAM en idle | ~150 MB (contexto GPU del renderizador) | ~0 MB |
| VRAM con modelo cargado | Idéntica (depende del modelo y cuantización, no de la herramienta) | |
La diferencia de ~400 MB de RAM entre ambas herramientas en idle es relevante solo en máquinas con poca memoria total. En un sistema con 16 GB o más de RAM, esta diferencia es inapreciable. La VRAM consumida por el modelo en ejecución es idéntica porque ambas herramientas delegan la carga del modelo a llama.cpp con los mismos parámetros de cuantización.
Ecosistema: integraciones, comunidad y extensibilidad
/api/generate,
/api/ps, /api/show) permite automatización avanzada
imposible con la API de OpenAI.
Cuándo elegir LM Studio y cuándo elegir Ollama
La pregunta no es cuál es mejor en términos absolutos sino cuál resuelve mejor tu caso de uso específico.
- Quieres explorar y comparar modelos de forma visual sin usar el terminal.
- Necesitas ajustar parámetros de inferencia en tiempo real durante una conversación.
- Trabajas en macOS Apple Silicon y quieres aprovechar el backend MLX para mayor rendimiento.
- Necesitas acceso a cuantizaciones específicas o modelos experimentales recién publicados en Hugging Face.
- Tu equipo incluye personas sin experiencia en línea de comandos.
- Integras el modelo en scripts, pipelines de CI/CD o servicios en segundo plano.
- Despliegas en un servidor Linux sin entorno gráfico.
- Necesitas gestionar múltiples modelos con cambio automático entre peticiones.
- Quieres el menor overhead posible del sistema (Ollama usa ~5x menos RAM en idle).
- Usas Docker y necesitas una imagen oficial mantenida.
El patrón más habitual entre desarrolladores experimentados es usar ambas herramientas de forma complementaria: LM Studio para explorar y elegir el modelo adecuado para una tarea, ajustar parámetros y verificar que el rendimiento es el esperado; y Ollama como servidor permanente en segundo plano para las integraciones de código, donde la fiabilidad y el bajo consumo son más importantes que la interfaz visual.
Preguntas frecuentes sobre LM Studio vs Ollama
No de forma consistente en hardware NVIDIA. Ambas herramientas usan llama.cpp como motor, por lo que el rendimiento bruto es idéntico. La diferencia observada en benchmarks (Ollama 78 tok/s vs LM Studio 64 tok/s en RTX 4090 con Llama 3.1 8B Q4_K_M) se debe al overhead de la interfaz gráfica de LM Studio. En macOS con modelos MLX, LM Studio puede superar a Ollama porque aprovecha optimizaciones nativas de Apple.
Sí. Ambas herramientas utilizan el formato GGUF internamente. Los archivos descargados
para LM Studio en ~/.cache/lm-studio/models/ son archivos GGUF estándar
compatibles con Ollama. Puedes importar un modelo en Ollama creando un Modelfile
que apunte al archivo GGUF y ejecutando ollama create nombre -f Modelfile.
Ollama consume menos recursos del sistema (~100 MB de overhead) frente a LM Studio (~500 MB con la interfaz gráfica abierta). La diferencia en VRAM para inferencia es mínima ya que ambos usan el mismo backend llama.cpp. En sistemas con poca RAM, Ollama es preferible para dejar más memoria disponible al modelo.
Sí. Ollama está diseñado para modo headless: se instala con un comando en Linux,
arranca como servicio del sistema y expone la API REST sin necesidad de pantalla
ni escritorio. LM Studio requiere un entorno de escritorio para funcionar, aunque
existe una herramienta CLI experimental (lms) que permite arrancar
el servidor sin la GUI pero sigue necesitando que LM Studio esté instalado.
LM Studio da acceso a todos los modelos GGUF de Hugging Face (miles de variantes y cuantizaciones) directamente desde su buscador integrado. Ollama mantiene su propio registro con alrededor de 200 modelos curados y optimizados, más fácil de explorar pero con menos variedad en cuantizaciones específicas. Para acceder a cuantizaciones avanzadas (IQ4_XS, Q5_K_S, etc.) LM Studio es la opción más conveniente.
Sí, en puertos distintos: LM Studio usa el puerto 1234 y Ollama el 11434 por defecto. Pueden coexistir en la misma máquina sin conflicto. El caso de uso habitual es tener Ollama como servicio permanente en segundo plano para scripts e integraciones y usar LM Studio ocasionalmente para explorar nuevos modelos con la interfaz visual. Sin embargo, si ambos intentan cargar el mismo modelo grande en GPU al mismo tiempo, competirán por VRAM.