¿Qué es LM Studio y para quién es?
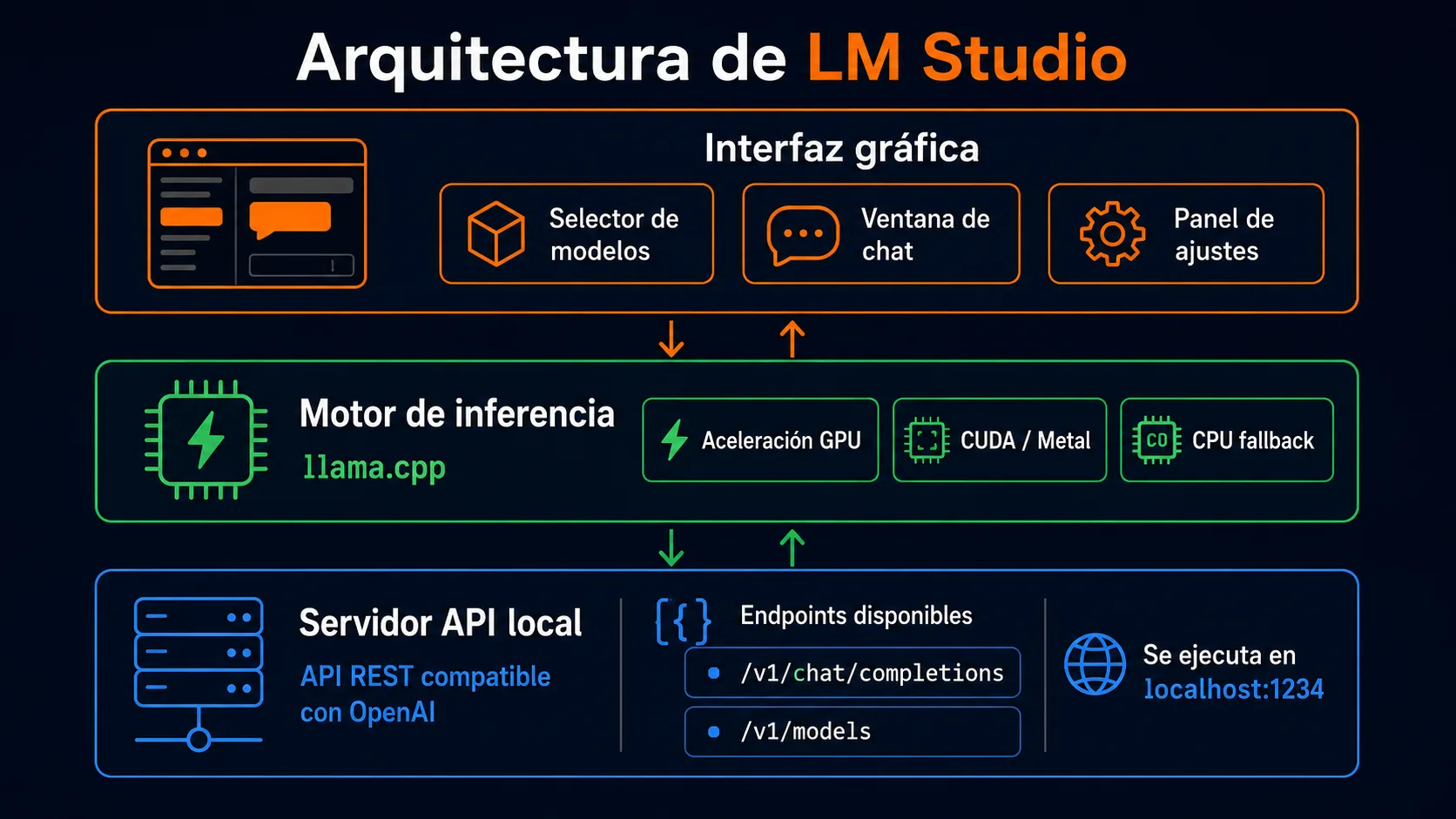
LM Studio es una aplicación de escritorio que actúa como capa visual sobre llama.cpp, el motor de inferencia en C++ que permite ejecutar modelos cuantizados en hardware de consumo. Donde llama.cpp requiere compilación y configuración manual, LM Studio ofrece un instalador de un clic que incluye todo lo necesario: motor de inferencia, buscador de modelos y servidor HTTP.
El público objetivo son desarrolladores y profesionales técnicos que quieren experimentar con modelos de lenguaje en local sin depender de APIs de pago, pero que prefieren una interfaz visual a la gestión por terminal. También es útil como entorno de prototipado rápido antes de integrar el modelo en un sistema de producción con Ollama u otro motor más ligero.
A diferencia de soluciones cloud como ChatGPT o la API de Claude, LM Studio procesa todo localmente: ningún dato sale de tu máquina. Esta característica lo convierte en una opción válida para proyectos con requisitos estrictos de privacidad, pruebas con documentos confidenciales o entornos sin acceso a internet.
Plataformas soportadas
| Sistema operativo | Aceleración GPU | Notas |
|---|---|---|
| macOS (Apple Silicon) | Metal (integrado) | Mejor rendimiento por watt del mercado |
| macOS (Intel) | CPU / Metal parcial | Rendimiento limitado en modelos grandes |
| Windows | NVIDIA CUDA / AMD ROCm | Requiere drivers actualizados |
| Linux | NVIDIA CUDA / AMD ROCm | Disponible como AppImage o paquete |
¿Cómo se instala y se usa por primera vez?
La instalación es sencilla: descarga el instalador desde lmstudio.ai, ejecútalo y sigue el asistente. No requiere registro ni cuenta. El instalador incluye el motor de inferencia, las dependencias de GPU y la interfaz de usuario. El peso total del instalador varía entre 300 MB y 600 MB según la plataforma.
Primer arranque: descargar un modelo
Al abrir LM Studio por primera vez, la pantalla principal muestra un buscador conectado
al repositorio de Hugging Face. Escribe el nombre del modelo que quieres probar (por ejemplo,
mistral 7b o llama 3 8b) y la interfaz muestra las variantes
disponibles en formato GGUF, ordenadas por tamaño de archivo y nivel de cuantización.
Paso 1 — Buscar y descargar
En la pestaña "Discover", busca el modelo. Selecciona la variante de cuantización adecuada a tu VRAM (Q4_K_M es el equilibrio recomendado entre calidad y velocidad). Pulsa "Download" y LM Studio gestiona la descarga en segundo plano.
Paso 2 — Cargar y chatear
Desde la pestaña "Chat", selecciona el modelo descargado en el desplegable superior. LM Studio lo carga en memoria (CPU o GPU según configuración) y abre la interfaz de conversación. Puedes ajustar temperatura, context length y otros parámetros desde el panel lateral derecho.
Paso 3 — Configurar capas de GPU
En el panel de carga del modelo encontrarás el control "GPU Layers". Un valor de 0 usa solo CPU; el valor máximo offloada todas las capas a la GPU. Si tienes 8 GB de VRAM y el modelo requiere más, LM Studio distribuye automáticamente las capas sobrantes a RAM.
Gestión de modelos descargados
LM Studio almacena los modelos en ~/.cache/lm-studio/models (Linux/macOS) o en
%USERPROFILE%\.cache\lm-studio\models (Windows). Los modelos son archivos GGUF
estándar compatibles con cualquier otra herramienta basada en llama.cpp. Puedes copiar, mover
o eliminar estos archivos directamente desde el sistema de archivos; LM Studio los detectará
automáticamente en el siguiente arranque.
¿Cómo funciona el servidor local?
Una de las funciones más útiles de LM Studio para desarrolladores es su servidor HTTP integrado.
Desde la pestaña "Local Server", activa el servidor con un clic: LM Studio levanta un endpoint
REST en http://localhost:1234/v1 que implementa el mismo esquema de la API de OpenAI.
Compatibilidad con la API de OpenAI
La compatibilidad cubre los endpoints más usados: /v1/chat/completions,
/v1/completions y /v1/models. Esto significa que cualquier librería
cliente pensada para OpenAI puede apuntar a LM Studio cambiando únicamente la URL base
y la API key (que puede ser cualquier cadena arbitraria, LM Studio no la valida).
| Lenguaje | Antes (OpenAI) | Después (LM Studio) |
|---|---|---|
| Python | base_url="https://api.openai.com/v1" |
base_url="http://localhost:1234/v1" |
| PHP (curl) | CURLOPT_URL = ".../v1/chat/completions" |
CURLOPT_URL = "http://localhost:1234/v1/chat/completions" |
| Node.js | baseURL: "https://api.openai.com/v1" |
baseURL: "http://localhost:1234/v1" |
Uso en integraciones y agentes
El servidor de LM Studio es útil cuando necesitas probar un agente o una cadena de prompts
sin incurrir en costes de API. Frameworks como LangChain, LlamaIndex o el SDK de OpenAI
para Python aceptan un parámetro base_url que puedes apuntar al servidor local.
Una vez que el prototipo funciona, cambias la URL de vuelta a la API de producción.
El servidor admite múltiples llamadas concurrentes dentro del límite de VRAM disponible. A diferencia de Ollama, que puede gestionar modelos múltiples en cola, LM Studio mantiene un único modelo cargado en memoria en cada momento. Si necesitas cambiar de modelo entre peticiones, el tiempo de carga puede ser un cuello de botella.
Configuración de red
Por defecto el servidor escucha en 127.0.0.1:1234, accesible solo desde la propia
máquina. Si necesitas exponerlo en la red local (por ejemplo, para acceder desde un móvil
o desde otra máquina del mismo segmento), puedes cambiar el binding a 0.0.0.0
desde la configuración del servidor. No expongas el servidor a internet sin autenticación.
¿Qué modelos son compatibles?
LM Studio soporta modelos en formato GGUF, el formato de cuantización estandarizado por el proyecto llama.cpp. GGUF reemplaza al anterior formato GGML y permite empaquetar el modelo completo, incluyendo metadatos de arquitectura, en un solo archivo portable y eficiente en memoria.
Niveles de cuantización disponibles
| Nivel | Bits por peso | Calidad relativa | Caso de uso |
|---|---|---|---|
Q2_K |
2-3 bits | Baja | Hardware muy limitado, pruebas rápidas |
Q4_0 |
4 bits | Moderada | Equilibrio entre velocidad y calidad |
Q4_K_M |
4 bits (mixto) | Buena | Recomendado para uso general |
Q5_K_M |
5 bits (mixto) | Muy buena | Calidad próxima a FP16 con menor VRAM |
Q8_0 |
8 bits | Excelente | Máxima calidad en hardware con VRAM amplia |
Modelos populares disponibles en LM Studio
El buscador integrado de LM Studio da acceso a todos los modelos GGUF publicados en Hugging Face. A mayo de 2026, los modelos más descargados y mejor valorados por la comunidad incluyen:
- Meta Llama 3.1 8B / 70B — equilibrio calidad-velocidad para tareas generales. La variante 8B corre bien en hardware de consumo con 8 GB de VRAM.
- Mistral 7B / Mixtral 8x7B — arquitectura eficiente, excelente para instrucción y generación de código. Mixtral usa mezcla de expertos (MoE) para mayor calidad con latencia controlada.
- Qwen2.5 7B / 14B / 32B — modelos de Alibaba con buen soporte multilingüe y capacidades de razonamiento destacadas en su categoría de tamaño.
- Phi-3 / Phi-4 (Microsoft) — modelos pequeños de alta eficiencia. Phi-3 Mini (3.8B) genera respuestas de calidad razonable con solo 4 GB de VRAM.
- DeepSeek R1 / Coder — modelos especializados en razonamiento y código. Consulta la guía de LM Studio con DeepSeek para instrucciones de configuración específicas.
LM Studio no soporta modelos en formato safetensors ni PyTorch nativo. Si quieres usar un modelo que solo está disponible en esos formatos, debes convertirlo a GGUF con las herramientas de llama.cpp antes de cargarlo.
GPU y rendimiento: ¿cuánta VRAM necesitas?
El rendimiento de LM Studio depende directamente de cuántas capas del modelo pueden offloadarse a la GPU. Cuando todas las capas caben en VRAM, la velocidad de generación (tokens por segundo) es máxima. Cuando hay capas que se procesan en CPU por falta de VRAM, la velocidad cae significativamente porque el bus PCIe se convierte en cuello de botella.
Referencia de VRAM por tamaño de modelo
| Tamaño del modelo | VRAM necesaria | GPU de referencia | Velocidad típica |
|---|---|---|---|
| 3-4B parámetros | 3-4 GB | RTX 3060 / M1 8 GB | 40-80 tokens/s |
| 7-8B parámetros | 5-6 GB | RTX 3070 / M2 16 GB | 25-50 tokens/s |
| 13B parámetros | 8-10 GB | RTX 3080 / M2 Pro | 15-30 tokens/s |
| 30-34B parámetros | 18-22 GB | RTX 3090 Ti / M3 Max | 8-15 tokens/s |
| 70B parámetros | 38-45 GB | 2x RTX 3090 / M2 Ultra | 3-8 tokens/s |
Apple Silicon vs NVIDIA
Apple Silicon (M1, M2, M3, M4) tiene una ventaja estructural para LM Studio: la memoria unificada actúa como VRAM sin coste adicional de transferencia. Un MacBook Pro M3 Max con 128 GB de memoria unificada puede correr modelos de 70B completamente en "GPU" (Metal) a velocidades que requerirían múltiples GPUs NVIDIA dedicadas.
Para hardware NVIDIA, las GPUs con más VRAM por precio en 2026 son la RTX 3090 (24 GB), la RTX 4090 (24 GB) y las tarjetas de la serie Ada Lovelace para workstation. AMD soporta ROCm en LM Studio desde la versión 0.2.x, aunque el soporte sigue siendo menos maduro que CUDA.
Puedes seguir profundizando en la configuración de GPU para LM Studio en la guía de LM Studio con modelos de Google, donde se explica también el proceso de cuantización avanzado.
Ejecución sin GPU
LM Studio puede ejecutar modelos usando solo CPU a través de la implementación AVX2/AVX-512 de llama.cpp. La velocidad es mucho menor (2-10 tokens/s en modelos de 7B) pero es suficiente para tareas de desarrollo donde la latencia no es crítica. En este modo, la RAM disponible sustituye a la VRAM como límite de tamaño de modelo.

LM Studio vs Ollama: ¿cuál elegir?
Ambas herramientas ejecutan modelos en local con API compatible con OpenAI, pero tienen filosofías de diseño muy distintas.
| Criterio | LM Studio | Ollama |
|---|---|---|
| Interfaz | Aplicación de escritorio con GUI | CLI y API REST (sin GUI nativa) |
| Instalación | Instalador gráfico | Un comando en terminal |
| Gestión de modelos | Buscador visual + descarga directa | ollama pull nombre |
| Servidor API | Activar desde la UI, puerto 1234 | Activo por defecto, puerto 11434 |
| Modelos simultáneos | Uno a la vez (cambio manual) | Varios en cola con gestión automática |
| Integración en scripts | Requiere iniciar la app manualmente | Servicio en segundo plano, ideal para CI/CD |
| Curva de aprendizaje | Baja (ideal para no-terminal) | Baja-media (requiere comodidad con terminal) |
| GitHub Stars | ~48k (mayo 2026) | ~250k (mayo 2026) |
| Licencia | Gratis personal, licencia empresa | MIT (completamente libre) |
Elige LM Studio si quieres explorar modelos rápidamente sin tocar la terminal, si trabajas en macOS y quieres aprovechar al máximo Apple Silicon, o si necesitas ajustar parámetros de inferencia de forma interactiva.
Elige Ollama si vas a integrar el modelo en scripts, pipelines de CI o servicios en segundo plano, si necesitas gestionar varios modelos de forma concurrente, o si priorizas un footprint mínimo en el sistema. Consulta la guía completa de Ollama para ver la instalación detallada.
Para un análisis exhaustivo con benchmarks de velocidad y comparativa de ecosistema, visita la página de comparativas y la comparativa específica LM Studio vs Ollama.
Preguntas frecuentes sobre LM Studio
¿Es LM Studio gratuito?
LM Studio es gratuito para uso personal. Existe una licencia de empresa para equipos y uso comercial intensivo. La descarga e instalación son libres sin registro previo. Los modelos que descargas a través de LM Studio tienen sus propias licencias (MIT, Apache 2.0, Llama Community License, etc.) que debes revisar antes de usarlos en producción comercial.
¿Qué diferencia hay entre LM Studio y Ollama?
LM Studio ofrece una interfaz gráfica completa con buscador de modelos integrado, mientras que Ollama opera principalmente desde la terminal con comandos CLI. Ambos exponen una API local compatible con OpenAI. LM Studio es más accesible para usuarios sin experiencia en terminal; Ollama es más ligero y se integra mejor en flujos de automatización y scripts desatendidos.
¿Qué GPU necesito para usar LM Studio?
LM Studio puede funcionar sin GPU usando solo CPU, aunque a menor velocidad. Para modelos de 7B parámetros se recomiendan al menos 8 GB de VRAM. Para modelos de 13B, entre 12 y 16 GB. Apple Silicon (M1 a M4) soporta aceleración vía Metal con excelente rendimiento incluso en chips de gama baja gracias a la memoria unificada: un M2 con 16 GB gestiona bien modelos de 7B a velocidades de 30-50 tokens por segundo.
¿Puedo usar LM Studio como servidor para mis aplicaciones?
Sí. LM Studio incluye un servidor local que expone una API REST compatible con OpenAI,
por defecto en http://localhost:1234/v1. Cualquier aplicación que use el SDK
de OpenAI puede apuntar a este servidor cambiando únicamente la URL base, sin modificar
código de negocio. Es la forma más rápida de probar integraciones de LLM en local
antes de pasarlas a producción con una API externa.
¿Qué formato de modelos soporta LM Studio?
LM Studio soporta principalmente modelos en formato GGUF, el estándar de cuantización de llama.cpp. El buscador integrado muestra directamente los modelos GGUF disponibles en Hugging Face. No soporta modelos en formato safetensors ni PyTorch nativo sin conversión previa con las herramientas de llama.cpp.