- DeepSeek R1 es el modelo de razonamiento open-source más capaz disponible en formato GGUF para LM Studio (mayo 2026). Las versiones destiladas (7B a 70B) permiten ejecutarlo en hardware de consumo.
- La temperatura recomendada por DeepSeek para modelos R1 es 0,6 (rango óptimo 0,5–0,7). Temperaturas más altas degradan la coherencia del razonamiento.
- DeepSeek Coder V2 Lite (16B MoE) requiere solo ~6 GB de VRAM y ofrece rendimiento en código comparable a modelos mucho más grandes.
- Todos los modelos DeepSeek tienen licencia MIT — uso comercial libre sin restricciones adicionales.
- La organización lmstudio-community en Hugging Face publica cuantizaciones GGUF actualizadas de todos los modelos DeepSeek.

Modelos DeepSeek disponibles en LM Studio
DeepSeek mantiene tres líneas de modelos con propósitos distintos. Elegir la línea correcta es tan importante como elegir el tamaño adecuado.
<think>. Ideal para matemáticas, lógica, análisis y problemas
complejos donde el proceso es tan valioso como la respuesta.
DeepSeek R1 en LM Studio: razonamiento visible paso a paso
DeepSeek R1 es el modelo de razonamiento de código abierto más capaz disponible en formato GGUF. Su característica diferencial es el chain-of-thought visible: el modelo expone su proceso de razonamiento antes de llegar a la respuesta final.
DeepSeek R1 fue entrenado con aprendizaje por refuerzo sobre razonamiento, lo que produce
un modelo que verbaliza cada paso de su proceso de pensamiento. En LM Studio, esto se
muestra como bloques <think>...</think> antes de la respuesta final.
Este comportamiento es especialmente útil para verificar si el modelo está razonando
correctamente o tomando atajos, y para depurar prompts en aplicaciones complejas.
El modelo completo DeepSeek R1 tiene 671B parámetros y es inviable en hardware de consumo. Sin embargo, DeepSeek publicó simultáneamente versiones destiladas entrenadas usando las cadenas de razonamiento del modelo completo como datos de entrenamiento, que sí son ejecutables en hardware local.
La última versión disponible en Hugging Face a mayo de 2026 es DeepSeek R1-0528, una actualización del modelo original R1 con mejoras en matemáticas y razonamiento de larga duración. Las versiones destiladas R1-0528 están basadas en Qwen3 8B y ofrecen capacidades de razonamiento superiores a las versiones anteriores en el mismo tamaño.
Versiones destiladas de DeepSeek R1: guía de elección
Las versiones destiladas de R1 transfieren el conocimiento de razonamiento del modelo de 671B a modelos base de Qwen y Llama en tamaños accesibles para hardware de consumo.
| Modelo | Base | VRAM (Q4_K_M) | Velocidad aprox. | Recomendado para |
|---|---|---|---|---|
R1-Distill-Qwen-7B |
Qwen2.5 7B | ~5 GB | 30–50 tok/s | Hardware con 6–8 GB VRAM, respuestas rápidas |
R1-Distill-Llama-8B |
Llama 3.1 8B | ~6 GB | 28–45 tok/s | Alternativa con arquitectura Llama, 8 GB VRAM |
R1-Distill-Qwen-14B |
Qwen2.5 14B | ~10 GB | 18–30 tok/s | RTX 3080/3090 12 GB, razonamiento más sólido |
R1-Distill-Qwen-32B |
Qwen2.5 32B | ~20 GB | 8–15 tok/s | RTX 3090/4090 24 GB, mejor calidad de razonamiento local |
R1-Distill-Llama-70B |
Llama 3.3 70B | ~40 GB | 3–6 tok/s | Apple Silicon M2 Ultra/M3 Max o múltiples GPUs |
R1-0528-Qwen3-8B |
Qwen3 8B | ~6 GB | 28–48 tok/s | Versión más reciente, razonamiento mejorado en 8B |
El punto óptimo para la mayoría de usuarios con una GPU de consumo es R1-Distill-Qwen-7B o R1-0528-Qwen3-8B: ofrecen razonamiento visible de calidad sorprendente para su tamaño y caben en cualquier GPU con 6 GB de VRAM. Si dispones de 24 GB de VRAM, el salto a R1-Distill-Qwen-32B produce mejoras perceptibles en tareas matemáticas y de razonamiento lógico complejo.
DeepSeek Coder en LM Studio: programación de nivel profesional en local
La línea DeepSeek Coder está diseñada específicamente para tareas de programación. Su variante Lite (16B MoE) ofrece una eficiencia extraordinaria para el hardware requerido.
Nota importante sobre flash attention en DeepSeek Coder
- En LM Studio, desactiva flash attention antes de cargar cualquier variante de DeepSeek Coder. Con flash attention activado, el modelo puede generar salidas incoherentes o fallar al inicio.
- Para desactivarlo: al seleccionar el modelo en la pestaña Chat, abre el panel de configuración avanzada del modelo y desmarca "Use Flash Attention".
- Este problema es específico de las variantes Coder — DeepSeek R1 y V3 funcionan correctamente con flash attention activado.
Cómo buscar y descargar modelos DeepSeek en LM Studio
LM Studio incluye los modelos DeepSeek más populares en su catálogo integrado. El buscador se conecta directamente a Hugging Face, por lo que siempre muestra las versiones más recientes disponibles.
- Abre LM Studio y ve a la pestaña Discover. Pulsa Ctrl+Shift+M (Windows/Linux) o Cmd+Shift+M (macOS) como atajo.
-
Escribe el término de búsqueda según el modelo que quieras:
deepseek-r1para las versiones destiladas de R1deepseek-r1-0528para la versión más recientedeepseek-coder-v2para DeepSeek Coder V2 Litedeepseek-v3para el modelo de propósito general
- Filtra los resultados por el tamaño de modelo adecuado a tu VRAM (ver tabla de versiones destiladas). Selecciona la cuantización Q4_K_M para uso general.
- Haz clic en Download. Los modelos más grandes pueden tardar varios minutos o más. LM Studio muestra el progreso en la barra inferior.
- Una vez descargado, selecciona el modelo en la pestaña Chat. Para DeepSeek Coder, recuerda desactivar flash attention antes de cargarlo.
Descarga manual desde Hugging Face
Si el modelo no aparece en el buscador integrado, puedes descargarlo directamente desde Hugging Face y apuntar LM Studio al archivo:
# Instalar huggingface-cli si no lo tienes
pip install huggingface_hub
# Descargar una cuantización específica de DeepSeek R1 destilado
huggingface-cli download \
lmstudio-community/DeepSeek-R1-Distill-Qwen-7B-GGUF \
DeepSeek-R1-Distill-Qwen-7B-Q4_K_M.gguf \
--local-dir ~/.cache/lm-studio/models/lmstudio-community/DeepSeek-R1-Distill-Qwen-7B-GGUFGuardando el archivo en la ruta de caché de LM Studio, la aplicación lo detecta automáticamente en el siguiente arranque sin necesidad de importación manual.
Parámetros óptimos para cada modelo DeepSeek en LM Studio
Los parámetros por defecto de LM Studio son un buen punto de partida, pero los modelos DeepSeek tienen configuraciones óptimas documentadas que mejoran la calidad de las respuestas de forma significativa.
| Parámetro | DeepSeek R1 (destilado) | DeepSeek V3 | DeepSeek Coder |
|---|---|---|---|
| Temperatura | 0,6 (rango 0,5–0,7) | 0,7–0,8 | 0,1–0,3 |
| Top-P | 0,95 | 0,9–0,95 | 0,95 |
| Max tokens (generación) | 8 192 (mínimo recomendado) | 4 096 | 4 096–8 192 |
| Context length | 16 384–32 768 | 8 192–16 384 | 16 384 |
| Flash attention | Activado (OK) | Activado (OK) | Desactivado (obligatorio) |
| GPU Layers | Máximo (offload completo si cabe) | Máximo posible | Máximo posible |
| Repeat penalty | 1,0 (no cambiar) | 1,05 | 1,0 |
Por qué R1 necesita max tokens alto
DeepSeek R1 genera primero el bloque de razonamiento (<think>) antes de
producir la respuesta final. En problemas complejos, este bloque puede consumir varios miles
de tokens. Si max_tokens es demasiado bajo, el modelo trunca el razonamiento
y la respuesta final es incorrecta o incompleta. El valor mínimo recomendado de
8 192 tokens garantiza que el modelo puede completar su proceso de pensamiento
antes de dar la respuesta.
System prompt para R1 destilado
Las versiones destiladas de R1 responden mejor con un system prompt que les indique explícitamente que muestren su razonamiento. El siguiente system prompt produce respuestas de mayor calidad en tareas analíticas:
Eres un asistente de razonamiento. Para cada problema:
1. Analiza el problema en detalle dentro de las etiquetas <think>.
2. Considera múltiples enfoques y verifica tu razonamiento.
3. Proporciona la respuesta final clara y concisa después del bloque de razonamiento.
Responde siempre en español.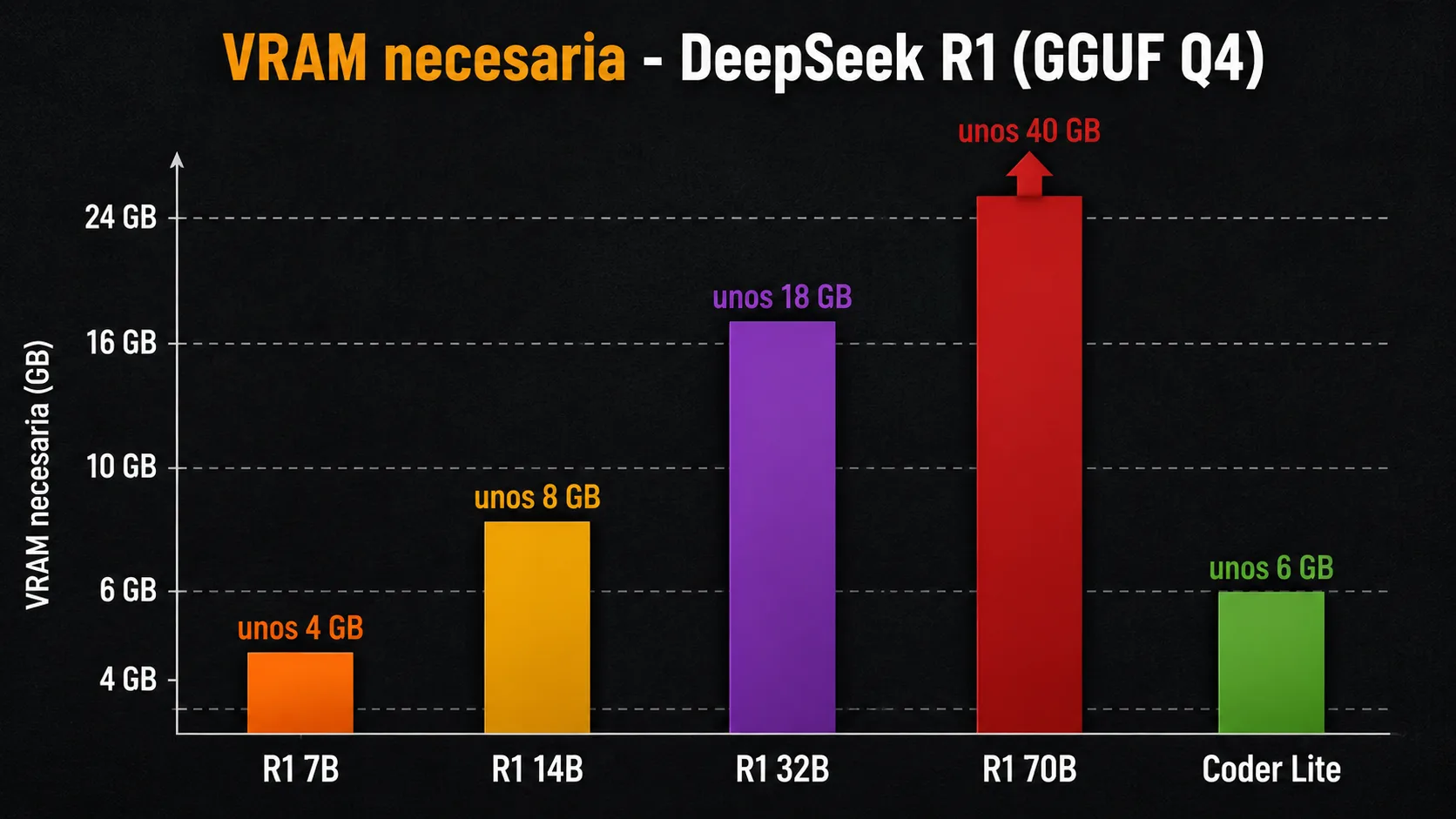
Requisitos de hardware: qué modelo corre en tu máquina
Guía de referencia rápida para saber qué variante de DeepSeek puedes ejecutar según la VRAM disponible en tu sistema.
| VRAM disponible | GPU de referencia | Modelo DeepSeek recomendado | Velocidad estimada |
|---|---|---|---|
| 4–6 GB | RTX 3060 6 GB, GTX 1080 | R1-Distill-Qwen-7B Q4_K_M Coder V2 Lite Q4_K_M |
25–40 tok/s |
| 8 GB | RTX 3070, RTX 4060 | R1-Distill-Llama-8B Q4_K_M R1-0528-Qwen3-8B Q4_K_M |
30–50 tok/s |
| 10–12 GB | RTX 3080 10/12 GB, RTX 4070 | R1-Distill-Qwen-14B Q4_K_M | 18–30 tok/s |
| 24 GB | RTX 3090, RTX 3090 Ti, RTX 4090 | R1-Distill-Qwen-32B Q4_K_M Coder 33B Q4_K_M |
8–15 tok/s |
| 32–128 GB (unificada) | Apple M2 Pro, M3 Max, M4 Max | R1-Distill-Qwen-32B Q8_0 R1-Distill-Llama-70B Q4_K_M |
6–20 tok/s |
| Solo CPU (sin GPU) | Cualquier PC con 16 GB RAM | R1-Distill-Qwen-7B Q4_K_M (lento) | 2–6 tok/s |
Si tu sistema tiene entre 4 y 8 GB de VRAM, el modelo R1-Distill-Qwen-7B en cuantización Q4_K_M es la mejor opción: ofrece razonamiento visible de calidad real con requisitos de hardware muy accesibles. Aunque la calidad es inferior al modelo completo de 671B, sigue siendo sorprendentemente bueno para matemáticas, lógica y análisis en comparación con otros modelos de 7B sin destilado de razonamiento.
Preguntas frecuentes sobre DeepSeek en LM Studio
Con 8 GB de VRAM puedes ejecutar las versiones destiladas de DeepSeek R1: R1-Distill-Qwen-7B o R1-Distill-Llama-8B en cuantización Q4_K_M. Ambas requieren entre 5 y 6 GB de VRAM y ofrecen capacidades de razonamiento superiores a modelos de la misma escala gracias al destilado de conocimiento del modelo completo de 671B. La versión R1-0528-Qwen3-8B es la más reciente y ofrece mejoras en razonamiento con el mismo presupuesto de VRAM.
DeepSeek R1 es un modelo de razonamiento que muestra su proceso de pensamiento paso a paso (chain-of-thought visible) antes de dar la respuesta final. DeepSeek V3 es un modelo de propósito general más rápido, sin razonamiento explícito, mejor para tareas de escritura, resumen y conversación fluida. DeepSeek Coder está especializado en programación. Para matemáticas y lógica compleja, usa R1. Para generación de texto y conversación, V3. Para código, Coder.
DeepSeek recomienda una temperatura de 0,6 para los modelos R1 (rango óptimo 0,5–0,7). Temperaturas más altas generan variación en el razonamiento pero pueden producir cadenas de pensamiento menos coherentes y respuestas incorrectas en tareas matemáticas. Para tareas de código con DeepSeek Coder, usa temperatura 0,1–0,3 para mayor determinismo en la generación de código.
Solo para los modelos DeepSeek Coder. En LM Studio, desactiva flash attention antes de cargar cualquier variante de DeepSeek Coder — con flash attention activado, el modelo puede generar salidas incoherentes o fallar al inicio. Los modelos R1 y V3 funcionan correctamente con flash attention activado en versiones recientes de LM Studio.
El modelo DeepSeek R1 completo tiene 671B parámetros y requiere hardware a nivel de centro de datos (varios nodos con GPUs H100 o A100). Para uso en local, las versiones destiladas son la opción práctica: R1-Distill-Qwen-7B (~5 GB VRAM), R1-Distill-Qwen-14B (~10 GB), R1-Distill-Qwen-32B (~20 GB) y R1-Distill-Llama-70B (necesita múltiples GPUs de 24 GB o Apple M2 Ultra con 192 GB de memoria unificada).
En la pestaña Discover de LM Studio, escribe deepseek-r1,
deepseek-v3 o deepseek-coder para ver las variantes
disponibles. La organización lmstudio-community en Hugging Face publica
cuantizaciones GGUF actualizadas. También puedes pegar directamente la URL del
repositorio de Hugging Face (por ejemplo,
lmstudio-community/DeepSeek-R1-Distill-Qwen-7B-GGUF) en el campo
de búsqueda de LM Studio para acceder a variantes específicas.