- Creado por el equipo de Pydantic: si ya usas Pydantic en tu proyecto, PydanticAI es una extensión natural sin curva de aprendizaje adicional para la validación de salidas.
- Las respuestas del LLM se validan contra modelos Pydantic de forma nativa — si el modelo devuelve datos que no cumplen el schema, la validación falla y el framework puede reintentar automáticamente.
- Agnóstico al modelo: soporta OpenAI, Anthropic Claude, Google Gemini, Ollama, Groq y Mistral con una sola línea de cambio en la configuración.
- Sistema de inyección de dependencias inspirado en FastAPI que permite escribir herramientas testables de forma aislada sin mockear el LLM.
- Incluye TestModel y FunctionModel para tests unitarios rápidos sin llamadas reales a la API, e integración con Logfire para observabilidad en producción.
¿Qué es PydanticAI y por qué lo creó el equipo de Pydantic?
PydanticAI nació de una observación directa del equipo de Pydantic al revisar proyectos de agentes en Python: la lógica del LLM y la validación de sus salidas estaban sistemáticamente separadas. Los desarrolladores llamaban al LLM, recibían texto libre, y luego escribían código de parsing manual o usaban abstracciones propietarias del framework para extraer datos estructurados. El equipo de Pydantic — que lleva años resolviendo exactamente ese problema para APIs REST y configuración de aplicaciones — decidió extender Pydantic al mundo de los agentes IA.
Samuel Colvin, creador de Pydantic y líder del proyecto, publicó PydanticAI a finales de 2024 con una premisa clara: un agente IA debería ser tan predecible y testeable como cualquier otro componente de una aplicación Python. La documentación oficial se mantiene en ai.pydantic.dev y el repositorio del proyecto en github.com/pydantic/pydantic-ai , con aproximadamente 15.000 estrellas a mayo de 2026. La licencia es MIT.
El diferenciador clave de PydanticAI frente a LangChain o CrewAI es que no inventa sus propias abstracciones para la validación de datos: aprovecha el sistema de tipos de Python y los modelos Pydantic v2 que la mayor parte de los proyectos Python ya tienen instalados. Si tu aplicación ya usa Pydantic para validar la entrada de una API REST, usar PydanticAI para garantizar que el LLM devuelve datos coherentes con esa misma estructura requiere prácticamente cero código adicional. Para entender el ecosistema completo de modelos LLM compatibles, la sección de multi-modelo más adelante cubre todas las opciones disponibles actualmente.
El framework es asíncrono de forma nativa — el objeto Agent expone tanto métodos
síncronos (agent.run_sync()) como asíncronos (await agent.run())
— y soporta streaming de texto y de objetos estructurados parciales. El modelo de
programación es lo suficientemente ligero como para usarlo en scripts de automatización
puntual y lo suficientemente robusto como para sustentar servicios API de producción.
¿Cuáles son los conceptos core de PydanticAI?
PydanticAI organiza su API alrededor de cuatro conceptos principales. Entenderlos es suficiente para construir agentes de producción.
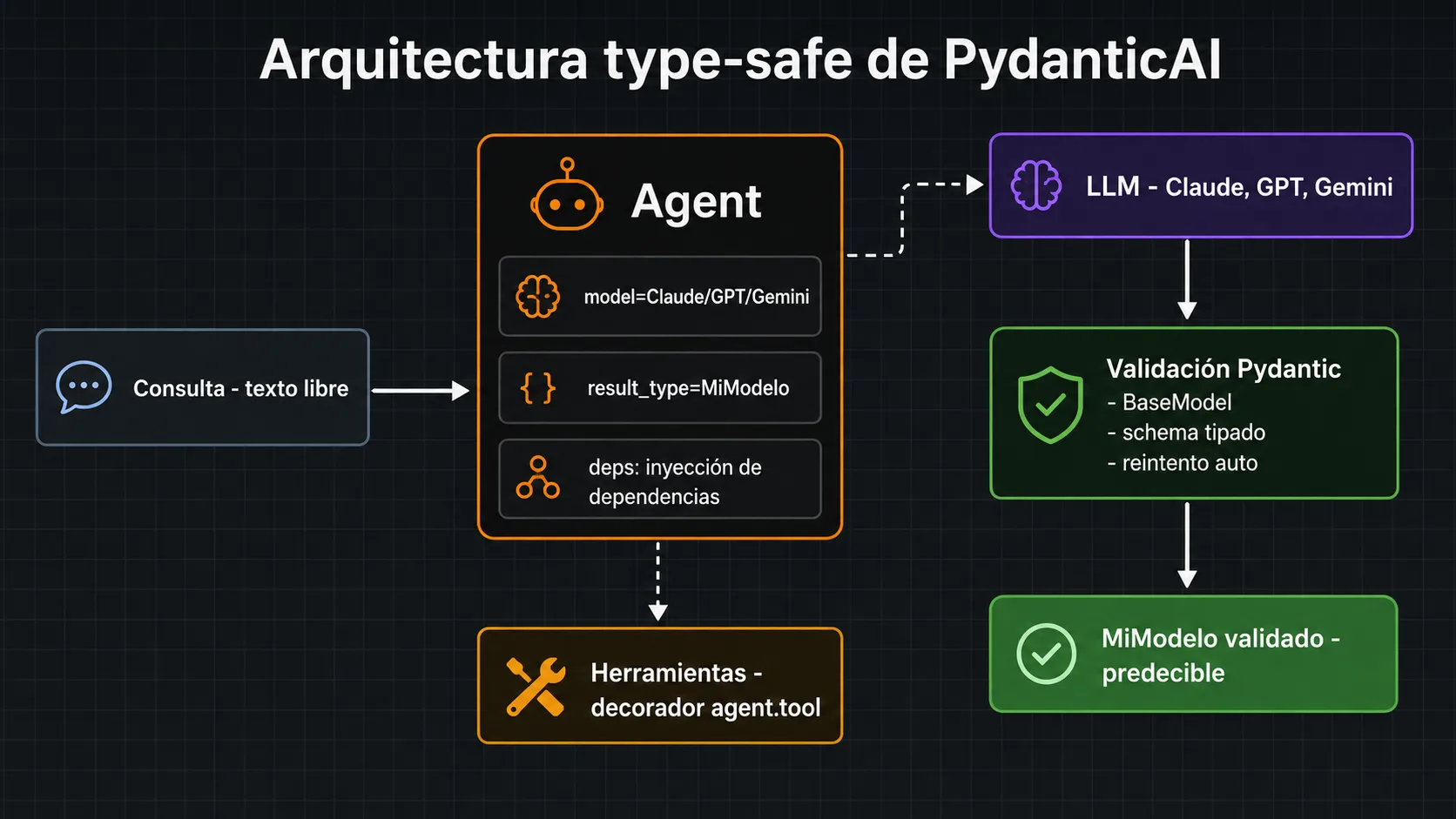
Agent: el objeto central
El objeto Agent encapsula el modelo LLM, el system prompt,
las herramientas disponibles y el tipo de resultado esperado. Se instancia
una vez y se reutiliza para múltiples llamadas. El parámetro
result_type es donde se declara el modelo Pydantic que
el LLM debe rellenar — PydanticAI convierte automáticamente ese modelo
en un schema JSON que el LLM recibe como restricción de salida y valida
la respuesta antes de devolverla al código llamante.
Tools con inyección de dependencias
Las herramientas del agente se definen como funciones Python decoradas
con @agent.tool. Lo que distingue a PydanticAI es que las
herramientas pueden declarar dependencias — conexiones a bases de datos,
clientes HTTP, instancias de servicio, contexto de usuario — como
parámetros tipados. El framework las inyecta automáticamente en tiempo
de ejecución mediante el objeto RunContext, siguiendo el
mismo patrón de inyección de dependencias que popularizó FastAPI.
En los tests, esas dependencias se sustituyen por stubs sin modificar
el código de la herramienta.
Structured output: validación automática de respuestas
Cuando el agente tiene un result_type definido, PydanticAI
garantiza que la respuesta del LLM siempre es una instancia válida de
ese modelo. Si el LLM devuelve datos que no cumplen el schema o que
fallan las validaciones personalizadas del modelo Pydantic, el framework
puede reintentar automáticamente la llamada con el mensaje de error de
validación incluido en el contexto — un mecanismo de autocorrección que
reduce drásticamente los errores en producción sin código adicional.
Result validators: lógica de negocio sobre la salida
Más allá de la validación de tipos, PydanticAI permite registrar result validators: funciones que reciben la respuesta validada del LLM y comprueban invariantes de negocio. Si un validator lanza una excepción, el framework reintenta la llamada con ese error como contexto adicional. Esto permite expresar restricciones complejas — "el precio no puede ser negativo", "la fecha de fin debe ser posterior a la de inicio", "la suma de porcentajes debe ser 100" — de forma declarativa sin repetir esas comprobaciones en el código de presentación.
¿Cómo se instala PydanticAI y cómo es el primer agente?
La instalación es un solo comando. El agente mínimo funcional son menos de diez líneas de Python.
Instalación
PydanticAI se instala desde PyPI con pip. Para trabajar con todos los proveedores de modelos, se pueden instalar los extras correspondientes en la misma instrucción:
# Instalación básica
pip install pydantic-ai
# Con soporte para Anthropic Claude y Google Gemini además de OpenAI
pip install "pydantic-ai[anthropic,google-generativeai]"
# Con soporte para Logfire (observabilidad)
pip install "pydantic-ai[logfire]"Primer agente: respuesta en texto libre
El agente más sencillo posible requiere solo el modelo y una llamada
a run_sync(). PydanticAI infiere el proveedor del modelo
a partir del nombre del string — los modelos openai:gpt-*,
anthropic:claude-* y google-gla:gemini-* se
resuelven automáticamente con la clave de API correspondiente en el
entorno:
from pydantic_ai import Agent
agente = Agent(
model="anthropic:claude-3-5-sonnet-latest",
system_prompt="Eres un asistente que responde en espanol de forma concisa.",
)
resultado = agente.run_sync("Cual es la capital de Francia?")
print(resultado.data)
# ParisAgente con herramienta y system prompt dinámico
Las herramientas se registran con el decorador @agent.tool_plain
(sin acceso al contexto de ejecución) o @agent.tool (con acceso
al RunContext para leer dependencias). El system prompt puede
ser una cadena estática o una función decorada con @agent.system_prompt
que se evalúa en cada ejecución con acceso a las dependencias de la llamada:
from pydantic_ai import Agent, RunContext
from datetime import date
agente = Agent(
model="openai:gpt-4o",
system_prompt="Eres un asistente de calendario. Hoy es {date}.",
)
@agente.system_prompt
def system_prompt_dinamico() -> str:
return f"Eres un asistente de calendario. Hoy es {date.today().isoformat()}."
@agente.tool_plain
def obtener_dia_semana(fecha: str) -> str:
"""Devuelve el dia de la semana para una fecha en formato YYYY-MM-DD."""
d = date.fromisoformat(fecha)
dias = ["lunes", "martes", "miercoles", "jueves", "viernes", "sabado", "domingo"]
return dias[d.weekday()]
resultado = agente.run_sync("En que dia de la semana cae el 15 de agosto de 2025?")
print(resultado.data)
# 15 de agosto de 2025 cae en viernes.¿Cómo garantiza PydanticAI que la respuesta del LLM es válida?
El result_type convierte cualquier modelo Pydantic en un schema
que el LLM debe respetar. Si la validación falla, el framework reintenta
automáticamente con el error como contexto.
Structured output con modelos Pydantic
Para obtener datos estructurados en lugar de texto libre basta con pasar
un modelo Pydantic como result_type al instanciar el agente.
PydanticAI genera internamente el schema JSON del modelo, lo incluye en
la llamada al LLM como restricción de formato de salida, y valida la
respuesta con Pydantic v2 antes de devolverla — incluyendo todas las
validaciones personalizadas definidas con @field_validator
o @model_validator:
from pydantic import BaseModel, field_validator
from pydantic_ai import Agent
class ExtraccionContacto(BaseModel):
nombre: str
email: str
empresa: str | None = None
telefono: str | None = None
@field_validator("email")
@classmethod
def validar_email(cls, v: str) -> str:
if "@" not in v:
raise ValueError(f"Email invalido: {v}")
return v.lower()
agente = Agent(
model="anthropic:claude-3-5-sonnet-latest",
result_type=ExtraccionContacto,
system_prompt="Extrae los datos de contacto del texto proporcionado.",
)
texto = """
Hola, me llamo Maria Garcia. Mi email es maria@ejemplo.com
y trabajo en Tecnologias SA. Puedes llamarme al +34 612 345 678.
"""
resultado = agente.run_sync(texto)
contacto = resultado.data
print(contacto.nombre) # Maria Garcia
print(contacto.email) # maria@ejemplo.com
print(contacto.empresa) # Tecnologias SAReintento automático ante fallos de validación
Cuando el LLM devuelve una respuesta que no supera la validación Pydantic,
PydanticAI reintenta la llamada incluyendo el error de validación en el
contexto del siguiente intento. El número máximo de reintentos se configura
con el parámetro retries en el agente. Este mecanismo es
especialmente valioso con modelos más pequeños o cuando los schemas
son complejos — en lugar de propagar una excepción al código llamante,
el agente da al modelo la oportunidad de corregir su salida con información
concreta sobre qué falló:
from pydantic import BaseModel, model_validator
from pydantic_ai import Agent
class Distribucion(BaseModel):
categoria_a: float
categoria_b: float
categoria_c: float
@model_validator(mode="after")
def suma_debe_ser_cien(self) -> "Distribucion":
total = self.categoria_a + self.categoria_b + self.categoria_c
if abs(total - 100.0) > 0.01:
raise ValueError(
f"Los porcentajes deben sumar 100. Suma actual: {total}"
)
return self
agente = Agent(
model="openai:gpt-4o-mini",
result_type=Distribucion,
retries=3, # hasta 3 reintentos si la validacion falla
system_prompt=(
"Analiza el texto y estima la distribucion porcentual del presupuesto "
"entre tres categorias: marketing, desarrollo y operaciones. "
"Los porcentajes deben sumar exactamente 100."
),
)
resultado = agente.run_sync(
"Una startup de 10 empleados con foco en producto y poco marketing."
)
print(resultado.data)
# Distribucion(categoria_a=20.0, categoria_b=60.0, categoria_c=20.0)¿Cómo se configura PydanticAI con diferentes proveedores LLM?
Cambiar de proveedor o de modelo es una sola línea. La lógica del agente, las herramientas y los schemas de salida no cambian.
PydanticAI abstrae las diferencias entre proveedores a través de su sistema
de modelos. El string del modelo sigue el formato proveedor:nombre-modelo.
Las claves de API se leen de las variables de entorno estándar de cada
proveedor (OPENAI_API_KEY, ANTHROPIC_API_KEY,
GEMINI_API_KEY) sin configuración adicional. Para modelos
locales con Ollama no se necesita ninguna clave de API — solo que el
servidor Ollama esté en ejecución:
from pydantic_ai import Agent
# OpenAI (requiere OPENAI_API_KEY)
agente_openai = Agent(model="openai:gpt-4o")
# Anthropic Claude (requiere ANTHROPIC_API_KEY)
agente_claude = Agent(model="anthropic:claude-3-5-sonnet-latest")
# Google Gemini (requiere GEMINI_API_KEY)
agente_gemini = Agent(model="google-gla:gemini-1.5-pro")
# Groq — inferencia rapida de modelos open source (requiere GROQ_API_KEY)
agente_groq = Agent(model="groq:llama-3.1-70b-versatile")
# Mistral (requiere MISTRAL_API_KEY)
agente_mistral = Agent(model="mistral:mistral-large-latest")
# Ollama — modelo local, sin clave de API
agente_local = Agent(model="ollama:llama3.2")Configuración avanzada: parámetros del modelo
Para ajustar parámetros del modelo — temperatura, número máximo de tokens de salida, top_p — se instancia directamente la clase del modelo en lugar de usar el string abreviado. Esto da acceso completo a la configuración específica de cada proveedor sin perder la compatibilidad con el resto del framework:
from pydantic_ai import Agent
from pydantic_ai.models.anthropic import AnthropicModel
modelo = AnthropicModel(
model_name="claude-3-5-sonnet-20241022",
# temperature y otros parametros se pasan en cada llamada via model_settings
)
agente = Agent(
model=modelo,
model_settings={"temperature": 0.2, "max_tokens": 1024},
system_prompt="Eres un extractor de datos preciso. Sin inventar informacion.",
)| Proveedor | Prefijo del modelo | Variable de entorno | Notas |
|---|---|---|---|
| OpenAI | openai: |
OPENAI_API_KEY |
GPT-5, GPT-4, GPT-3.5 y variantes |
| Anthropic Claude | anthropic: |
ANTHROPIC_API_KEY |
Claude Sonnet 4.6, Claude Opus 4.7, Haiku |
| Google Gemini | google-gla: |
GEMINI_API_KEY |
Gemini 3.1 Pro, Flash y variantes |
| Groq | groq: |
GROQ_API_KEY |
Llama 3, Mixtral — inferencia muy rápida |
| Mistral | mistral: |
MISTRAL_API_KEY |
Mistral Large, Small y Nemo |
| Ollama | ollama: |
Sin clave de API | Modelos locales: Llama, Mistral, Phi, Qwen |
¿Cómo se testea y depura un agente PydanticAI?
TestModel y FunctionModel permiten tests unitarios sin llamadas a la API. Logfire captura trazas completas de cada ejecución en producción.
TestModel: tests sin coste ni latencia de API
TestModel simula el comportamiento del LLM de forma
determinista sin hacer ninguna llamada de red. Cuando el agente tiene
un result_type definido, TestModel genera
automáticamente una instancia válida del modelo Pydantic con valores
de prueba. Las herramientas se invocan en el orden en que el agente
las habría llamado. Esto permite ejecutar tests unitarios completos
del flujo del agente — incluyendo el sistema de inyección de
dependencias — en milisegundos y sin necesidad de una clave de API.
FunctionModel: simulación de escenarios específicos
FunctionModel permite definir una función Python que
actúa como el modelo LLM. La función recibe los mensajes del historial
de la conversación y devuelve la respuesta que el test necesita —
incluyendo llamadas específicas a herramientas, mensajes de error o
respuestas parciales. Es el mecanismo adecuado para probar el
comportamiento del agente ante respuestas concretas del LLM, como
secuencias específicas de tool calls o respuestas que deben fallar
la validación para comprobar el mecanismo de reintento.
Logfire: observabilidad integrada para producción
PydanticAI tiene integración nativa con Logfire, la plataforma de
observabilidad del equipo de Pydantic. Con una sola llamada a
logfire.configure(), cada ejecución del agente genera
trazas OpenTelemetry que capturan el system prompt, los mensajes
intercambiados, las herramientas invocadas con sus entradas y salidas,
los tokens consumidos y la latencia de cada llamada al LLM. Logfire
exporta trazas en formato OTLP compatible con Jaeger, Grafana y
cualquier backend de observabilidad. La documentación de la integración
está en
ai.pydantic.dev/logfire .
Inspección del historial de mensajes
El objeto RunResult devuelto por agent.run()
expone el historial completo de mensajes del agente a través de
resultado.all_messages(). Cada mensaje incluye el rol
(system, user, assistant, tool-return), el contenido exacto y los
metadatos de la herramienta si aplica. Este historial es suficiente
para depurar cualquier comportamiento inesperado sin necesidad de
instrumentación adicional.
Ejemplo de test con TestModel y pytest
import pytest
from pydantic import BaseModel
from pydantic_ai import Agent
from pydantic_ai.models.test import TestModel
class ResumenDocumento(BaseModel):
titulo: str
puntos_clave: list[str]
longitud_palabras: int
agente = Agent(
model="anthropic:claude-3-5-sonnet-latest",
result_type=ResumenDocumento,
system_prompt="Resume el documento proporcionado de forma estructurada.",
)
def test_agente_genera_resumen_valido():
with agente.override(model=TestModel()):
resultado = agente.run_sync("Texto del documento de prueba")
resumen = resultado.data
assert isinstance(resumen, ResumenDocumento)
assert resumen.titulo != ""
assert len(resumen.puntos_clave) > 0
assert resumen.longitud_palabras >= 0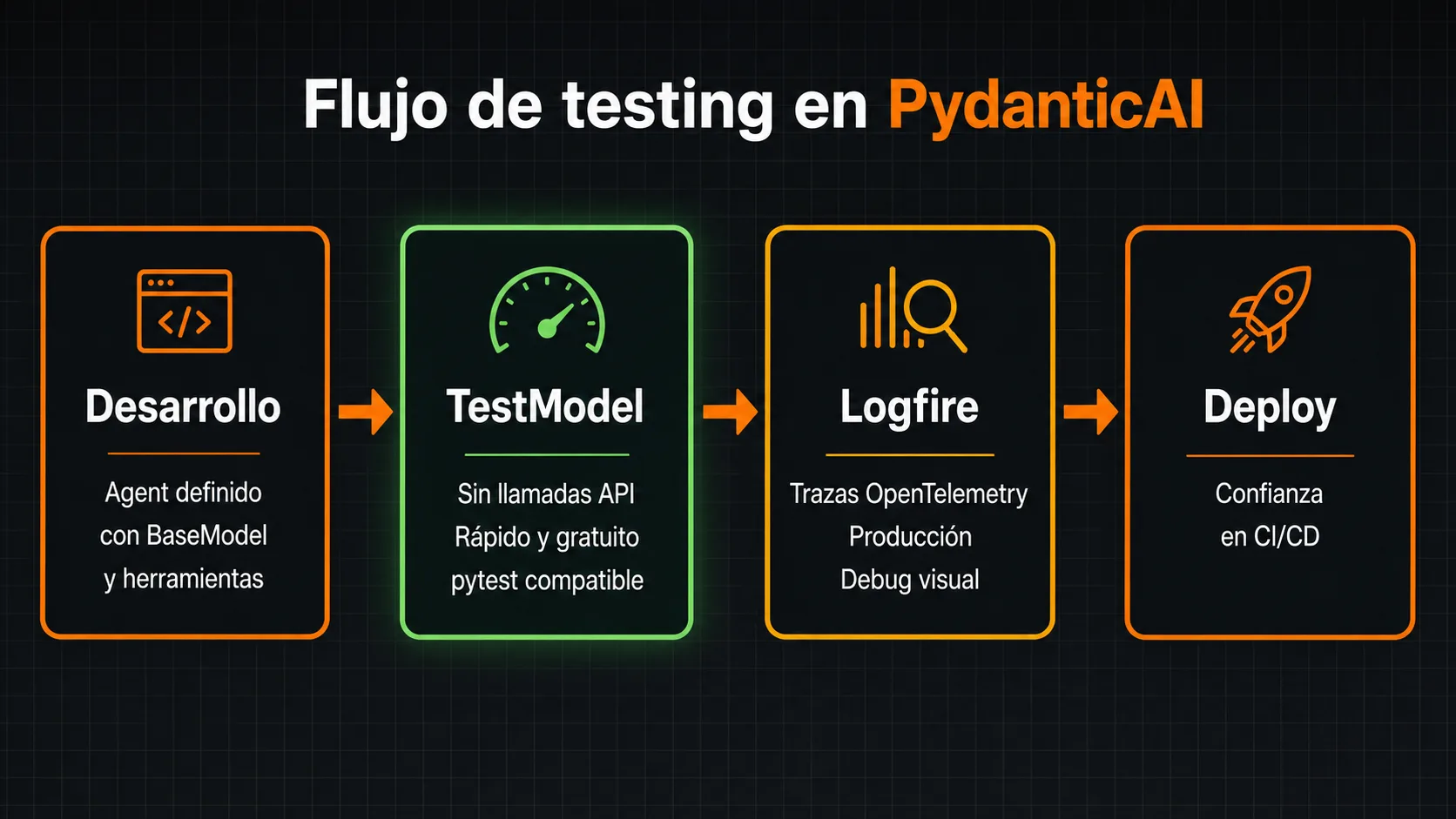
PydanticAI vs LangChain vs CrewAI vs Claude Agent SDK: ¿cuál elegir?
Cada framework tiene un punto fuerte diferente. Esta tabla ayuda a identificar cuál se ajusta mejor según el contexto del proyecto.
| Criterio | PydanticAI | LangChain | CrewAI | Claude Agent SDK |
|---|---|---|---|---|
| Filosofía central | Tipos Python nativos y validación Pydantic | Chains y agents con muchas integraciones | Roles declarativos para multi-agente | Agentes con herramientas gestionados por Anthropic |
| Curva de aprendizaje | Baja si ya conoces Pydantic | Media-alta — muchas abstracciones | Baja — API intuitiva | Baja para Claude, requiere cuenta Anthropic |
| Validación de tipos | Nativa — el punto fuerte | Manual con Pydantic externo | Moderada | A traves de herramientas del SDK |
| Soporte multi-modelo | OpenAI, Claude, Gemini, Ollama, Groq, Mistral | Más de 50 proveedores | OpenAI, Claude, Gemini y otros | Solo Anthropic Claude |
| Testing integrado | TestModel y FunctionModel incluidos | Requiere mocks externos | Limitado | A traves del SDK de Anthropic |
| Sistemas multi-agente | Limitado — no es el objetivo principal | LangGraph con sub-grafos | Nativo — su fortaleza | Sessions y environments gestionados |
| Observabilidad | Logfire + OpenTelemetry | LangSmith — plataforma dedicada | CrewAI+ con observabilidad integrada | Dashboard Anthropic + OpenTelemetry |
| Integraciones externas | Tools propias y MCP | +600 — ecosistema más amplio | ~100 herramientas | MCP y tools propias |
| Reintento ante fallos de validación | Automático con error como contexto | Manual | Manual | Configurable en el SDK |
| Mejor para | Extracción de datos, APIs con output predecible, proyectos con Pydantic existente | Pipelines RAG, muchas integraciones, flujos complejos con LangGraph | Equipos de agentes con roles claros y flujo declarativo | Agentes con herramientas cloud gestionadas por Anthropic |
Regla de decisión rápida
Elige PydanticAI cuando la fiabilidad del output sea la prioridad, cuando tu proyecto ya usa Pydantic para validar otros datos, o cuando necesites tests unitarios rápidos para el comportamiento del agente. Elige LangChain cuando necesites muchas integraciones con sistemas externos o flujos de control complejos con LangGraph. Elige CrewAI cuando el caso de uso sea un equipo de agentes con roles bien definidos. Elige Claude Agent SDK cuando quieras que Anthropic gestione el bucle del agente y el sandbox de ejecución de herramientas con Claude como modelo exclusivo.
Preguntas frecuentes sobre PydanticAI
PydanticAI es un framework Python de código abierto para construir agentes IA con validación de tipos nativa. Fue creado por Samuel Colvin y el equipo de Pydantic — los mismos autores de la biblioteca de validación de datos más popular del ecosistema Python — y lanzado a finales de 2024. Su filosofía central es extender el sistema de tipos de Python al desarrollo de agentes, de modo que las respuestas del LLM sean tan predecibles y validadas como cualquier otro dato en la aplicación.
La diferencia principal es el enfoque en el sistema de tipos de Python. LangChain y CrewAI usan sus propias abstracciones para definir herramientas, agentes y salidas. PydanticAI usa directamente los modelos Pydantic que muchos desarrolladores ya tienen en su código de validación de datos: si ya usas Pydantic para validar entradas de API, usar PydanticAI para estructurar las respuestas del LLM requiere prácticamente cero código adicional. Además, PydanticAI es más ligero en dependencias y tiene utilidades de testing integradas que facilitan la escritura de tests unitarios para comportamientos de agente sin llamadas reales a la API.
PydanticAI es agnóstico al modelo. A mayo de 2026 soporta de forma nativa OpenAI (GPT-5, GPT-4, etc.), Anthropic Claude (Claude Sonnet 4.6, Claude 3 Opus, etc.), Google Gemini (Gemini 3.1 Pro, Flash, etc.), modelos locales vía Ollama, Groq y Mistral. Cambiar de proveedor es una sola línea de configuración sin modificar la lógica del agente ni las definiciones de herramientas.
PydanticAI implementa un sistema de inyección de dependencias inspirado en
FastAPI. Las herramientas del agente pueden declarar dependencias — conexiones
a bases de datos, clientes HTTP, configuración, contexto de usuario — en su
firma y PydanticAI las resuelve automáticamente en tiempo de ejecución mediante
el objeto RunContext. Esto permite escribir herramientas testables
de forma aislada: en los tests se pasan dependencias simuladas sin necesidad de
mockear el LLM ni levantar servicios externos.
PydanticAI incluye dos utilidades de testing: TestModel y
FunctionModel. TestModel simula el comportamiento
del LLM de forma determinista sin hacer llamadas reales a la API, lo que
permite ejecutar tests unitarios en milisegundos sin coste. FunctionModel
permite definir una función Python que actúa como el modelo, simulando respuestas
específicas o secuencias de tool calls para probar escenarios concretos. Ambas
son compatibles con pytest y se integran directamente con el sistema de inyección
de dependencias para sustituir dependencias reales por stubs en los tests.
PydanticAI incluye integración nativa con Logfire, la plataforma de
observabilidad del equipo de Pydantic. Logfire captura cada llamada al LLM,
las herramientas invocadas, sus entradas y salidas, la latencia y los tokens
consumidos. Para proyectos que prefieren OpenTelemetry estándar, Logfire
exporta trazas en formato OTLP compatible con Jaeger, Grafana o cualquier
backend de observabilidad. La integración con Logfire se activa con una
sola llamada a logfire.configure() sin modificar el código
del agente.