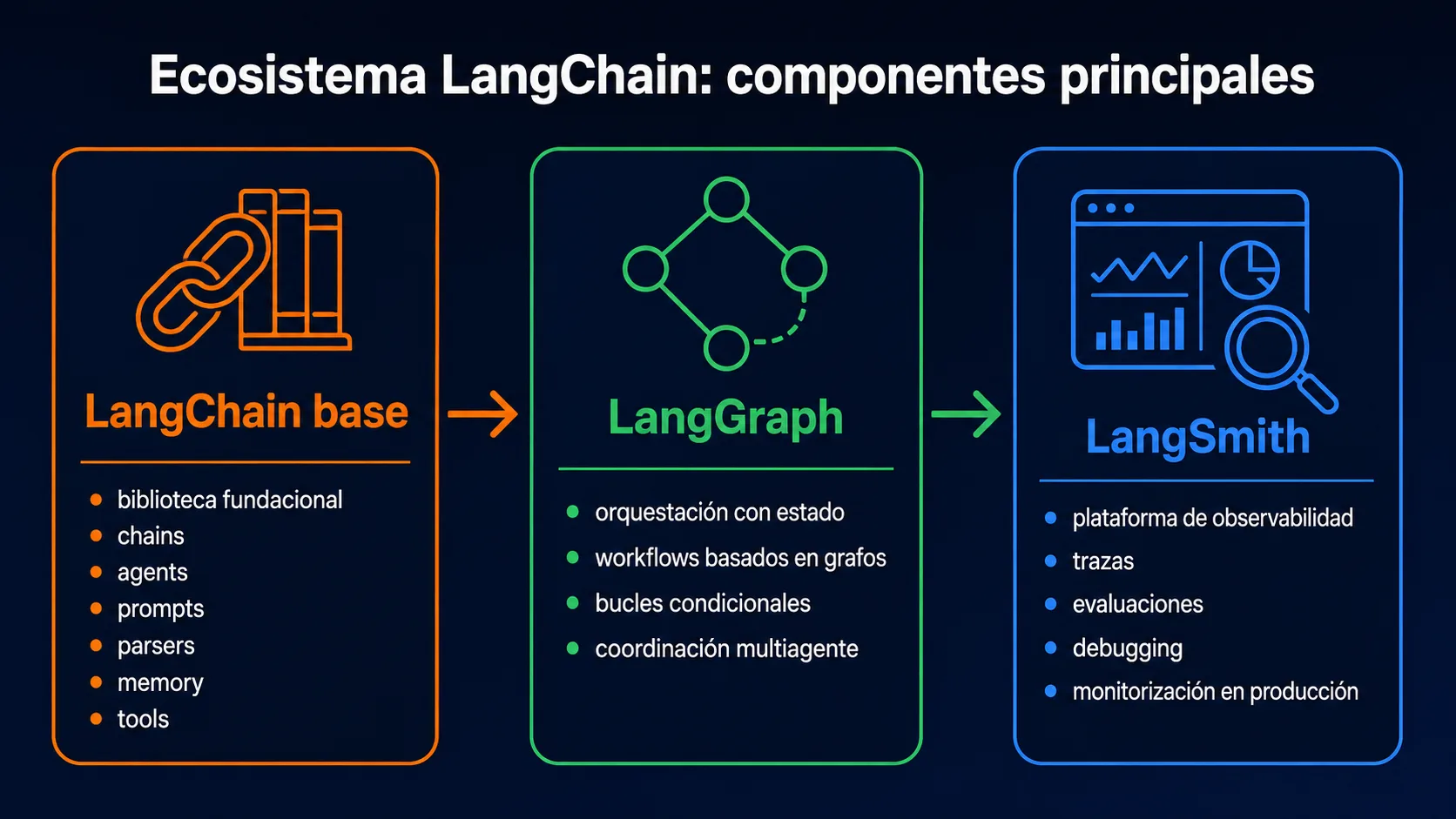
- LangChain es el framework Python de orquestación de agentes con mayor ecosistema: más de 600 integraciones con bases de datos vectoriales, APIs, buscadores y servicios externos.
- LangGraph extiende LangChain para flujos basados en grafos con estado persistente — la opción recomendada para agentes con bifurcaciones y ciclos.
- LangSmith proporciona observabilidad y debugging en producción, con trazas visuales de cada llamada al LLM, tiempo de respuesta y coste estimado.
- Compatible con cualquier LLM: OpenAI, Anthropic Claude, Google Gemini, Mistral, modelos locales vía Ollama y cualquier proveedor con API OpenAI-compatible.
- El patrón ReAct (Reasoning + Acting) es el mecanismo de agencia nativo en LangChain — el modelo razona sobre qué herramienta usar, la ejecuta y observa el resultado en un loop.

¿Qué es LangChain y por qué es el framework más completo para Python?
LangChain nació en 2022 de la mano de Harrison Chase como una biblioteca Python para encadenar llamadas a modelos de lenguaje con acceso a herramientas externas. En dos años pasó de ser un experimento de fin de semana a convertirse en el framework de orquestación de agentes más descargado del ecosistema Python, con cerca de 92.000 estrellas en GitHub y más de 3.000 contribuidores activos a mayo de 2026. La documentación oficial se mantiene en python.langchain.com y el repositorio principal en github.com/langchain-ai/langchain .
La razón de su popularidad no es una sola característica sino la combinación de dos factores: profundidad de abstracciones (desde la llamada cruda al LLM hasta sistemas multi-agente con memoria persistente) y amplitud de integraciones (más de 600 conectores con bases de datos vectoriales, sistemas de búsqueda, APIs REST, bases de datos SQL, herramientas de código, documentos y servicios en la nube). Si algo existe en el ecosistema de datos o IA, hay casi con total seguridad una integración LangChain para ello. Para comprender el espacio de modelos LLM con los que se puede usar LangChain, la guía de modelos da el contexto completo.
LangChain no es un único paquete sino un ecosistema modular. El paquete langchain
proporciona las abstracciones principales. Los paquetes de integración (langchain-openai,
langchain-anthropic, langchain-ollama, etc.) se instalan por separado
según los servicios que necesites. langchain-community agrupa integraciones
mantenidas por la comunidad. Esta modularidad evita que un proyecto sin uso de bases de datos
vectoriales cargue con las dependencias de Pinecone o Chroma — una mejora significativa
respecto a las primeras versiones del framework.
A mayo de 2026, LangChain ha dado cabida a dos proyectos hermanos que forman el ecosistema completo: LangGraph para orquestación basada en grafos con estado tipado, y LangSmith para observabilidad en producción. Juntos forman la tríada sobre la que se construyen la mayoría de agentes de producción en Python. Para los desarrolladores que prefieren un enfoque más ligero y tipado, la guía de CrewAI ofrece una perspectiva complementaria.
Arquitectura: chains, agents, tools, memory y retrievers
LangChain organiza sus abstracciones en cinco capas complementarias. Entender cada una es el primer paso para diseñar un agente bien estructurado.
Chains: la unidad básica de composición
Una chain es una secuencia de pasos encadenados donde la salida de cada
paso es la entrada del siguiente. En LangChain Expression Language (LCEL),
las chains se definen con el operador | (pipe): un prompt,
seguido del modelo, seguido de un parser de salida. Las chains son
serializables, observables y componibles — puedes combinar chains simples
para construir pipelines complejos sin perder la trazabilidad.
Agents: el motor de razonamiento y acción
Un agente en LangChain combina un modelo de lenguaje con un conjunto de herramientas y un bucle de ejecución. El modelo decide en cada iteración qué herramienta llamar y con qué argumentos, ejecuta la herramienta, observa el resultado e incorpora ese resultado al contexto para decidir el siguiente paso. LangChain proporciona los agentes preconstruidos más habituales (ReAct, OpenAI Functions, Structured Chat) y permite definir agentes personalizados a través de LangGraph.
Tools: las capacidades del agente
Las tools son las acciones que el agente puede ejecutar: búsqueda web,
ejecución de código Python, consultas SQL, lectura de archivos, llamadas
a APIs REST, consultas a bases de datos vectoriales o cualquier función
Python personalizada. LangChain incluye docenas de tools preconstruidas
y un decorator @tool para crear herramientas propias en
segundos. Cada tool tiene un nombre, descripción y esquema de entrada
que el modelo usa para decidir cuándo y cómo invocarla.
Memory: contexto que persiste entre turnos
La memoria permite al agente recordar información entre turnos de una
misma conversación o incluso entre sesiones distintas. LangChain ofrece
varios tipos: ConversationBufferMemory (histórico completo),
ConversationSummaryMemory (resumen comprimido del histórico),
VectorStoreRetrieverMemory (búsqueda semántica sobre el
histórico) y memoria con backend externo como Redis o bases de datos SQL.
La elección del tipo de memoria tiene un impacto directo en el consumo
de tokens y en la calidad del contexto que el agente tiene disponible.
Retrievers: acceso a información propia
Los retrievers son la pieza clave de los sistemas RAG (Retrieval Augmented Generation). Dado un texto de consulta, el retriever busca los documentos más relevantes en una fuente de datos y los pone a disposición del modelo. LangChain soporta más de 30 bases de datos vectoriales como retrievers (Pinecone, Chroma, Faiss, Weaviate, Qdrant, etc.) y múltiples estrategias de búsqueda: similitud semántica, búsqueda híbrida (semántica + keyword), búsqueda con reranking y búsqueda sobre grafos de conocimiento.
| Componente | Qué hace | Cuándo usarlo | Alternativa |
|---|---|---|---|
| Chain (LCEL) | Encadena prompt + modelo + parser en un pipeline reutilizable | Cualquier pipeline lineal de procesamiento con LLM | Llamada directa al SDK si solo hay un paso |
| Agent | Bucle de razonamiento + uso de herramientas hasta completar la tarea | Tareas que requieren planificación y acceso a información externa | LangGraph para flujos con estado y ciclos |
| Tool | Función invocable por el agente con nombre, descripción y schema | Cualquier capacidad externa que el agente deba tener | Función Python directa si no se usa un agente |
| Memory | Persiste el historial o contexto relevante entre turnos | Chatbots, asistentes con sesiones largas, contexto acumulativo | LangGraph con estado persistente para mayor control |
| Retriever | Recupera documentos relevantes dado un texto de consulta | RAG, respuestas sobre documentos propios, knowledge bases | Búsqueda directa sobre la base de datos vectorial |
| Document Loader | Carga e indexa documentos desde múltiples fuentes | Ingestión de PDFs, webs, bases de datos, APIs para RAG | Lectura directa del archivo si la fuente es simple |
LangGraph: cuando el agente necesita más que una línea recta
LangGraph modela el flujo de ejecución de un agente como un grafo dirigido con nodos de procesamiento, aristas condicionales y estado persistente tipado.
El problema que resuelve LangGraph
Los agentes de producción rara vez siguen un flujo lineal. Un agente de investigación puede necesitar buscar información, evaluar si es suficiente, volver a buscar con una consulta refinada, extraer datos estructurados, verificar su coherencia y solo entonces generar el informe final. Este tipo de flujo con ciclos, bifurcaciones condicionales y retrocesos no se puede representar limpiamente con una chain lineal.
LangGraph, publicado por el equipo de LangChain en 2024 y maduro a mayo de 2026 con más de 12.000 estrellas propias en GitHub, resuelve esto modelando el agente como un grafo dirigido donde:
- Los nodos son funciones Python que procesan el estado actual y devuelven actualizaciones.
- Las aristas definen qué nodo se ejecuta después — de forma determinista o condicional según el contenido del estado.
- El estado es un objeto tipado (con TypedDict o Pydantic) que persiste a lo largo de toda la ejecución del grafo.
- Los checkpoints permiten pausar, reanudar y continuar la ejecución desde cualquier punto — esencial para agentes de larga duración.
La documentación oficial de LangGraph se mantiene en python.langchain.com/docs/langgraph . El repositorio del proyecto está en github.com/langchain-ai/langgraph .
Casos de uso donde LangGraph es superior
Agentes de investigación con verificación iterativa
El grafo puede incluir un nodo de evaluación que, si la información recuperada no es suficiente, devuelve el control al nodo de búsqueda con una consulta refinada. Este ciclo de buscar-evaluar-refinar no es posible en una chain lineal sin recurrir a código imperativo ad-hoc.
Sistemas multi-agente con control de flujo preciso
LangGraph soporta sub-grafos: un nodo del grafo principal puede ser en sí mismo otro grafo, con su propio estado y lógica interna. Esto permite construir sistemas donde un agente coordinador delega subtareas a agentes especializados sin perder el control sobre el flujo global ni el estado compartido.
Agentes de larga duración con checkpoints
LangGraph permite persistir el estado del grafo en una base de datos entre ejecuciones. Si el proceso es interrumpido (reinicio del servidor, timeout, error recuperable), el agente puede retomar exactamente desde donde lo dejó sin perder el contexto acumulado. Esto es fundamental para tareas que pueden durar minutos u horas.
Flujos con aprobación humana intermedia
LangGraph soporta el patrón "human-in-the-loop" de forma nativa: el grafo puede pausarse en un nodo de decisión, enviar una notificación al operador humano (vía webhook, email o Slack), esperar su respuesta y continuar según la decisión tomada. Útil para agentes que ejecutan acciones irreversibles o de alto impacto que requieren supervisión humana.
| Tipo de flujo | LangChain (chain/agent clásico) | LangGraph |
|---|---|---|
| Pipeline lineal sin bifurcaciones | Suficiente y más simple | Excesivo |
| Agente con herramientas en un solo turno | Agente ReAct estándar | Posible pero innecesario |
| Flujo con ciclos o retrocesos | Difícil sin código ad-hoc | Aristas condicionales nativas |
| Estado persistente entre pasos | Requiere gestión manual | Estado tipado integrado |
| Sistemas multi-agente complejos | Limitado | Sub-grafos y super-paso |
| Human-in-the-loop | Requiere implementación manual | Soporte nativo con interrupt |
| Checkpoints y recuperación de errores | No disponible | CheckpointSaver con SQLite, Redis, etc. |
LangSmith: ¿cómo saber qué hace tu agente en producción?
Sin observabilidad, un agente en producción es una caja negra. LangSmith es la plataforma que convierte cada llamada al LLM en información accionable.
LangSmith es una plataforma de observabilidad, evaluación y debugging para aplicaciones construidas con LangChain. Se activa con tres líneas de configuración y, a partir de ese momento, cada chain, agente o llamada al LLM queda registrada con el prompt exacto enviado, la respuesta completa, el tiempo de latencia, los tokens consumidos y el coste estimado. La interfaz web permite navegar por la traza completa de una ejecución, identificar exactamente en qué paso el agente tomó una decisión errónea y reproducir cualquier llamada individualmente para depurar.
Más allá del debugging, LangSmith incluye capacidades de evaluación sistemática. Puedes definir datasets de prueba con entradas y salidas esperadas, ejecutar el agente contra ese dataset y obtener métricas de precisión, recall o calidad subjetiva (con un LLM como juez). Esto permite detectar regresiones cuando modificas el prompt del sistema o cambias el modelo subyacente — un flujo de trabajo equivalente a los tests de regresión en software tradicional, adaptado al comportamiento probabilístico de los LLMs.
Trazado completo de ejecuciones
Cada run queda registrado como un árbol de spans jerárquicos: la llamada al agente contiene las llamadas al LLM, que contienen las llamadas a las tools, que contienen sus resultados. Puedes ver el prompt exacto enviado a cada modelo, incluyendo el system message y el historial de mensajes, y la respuesta literal que devolvió.
Métricas de latencia y coste en tiempo real
El dashboard de LangSmith muestra latencia percentil (p50, p90, p99), tokens por run, coste estimado en dólares por proveedor y tendencias temporales. Estos datos son esenciales para entender si un cambio en el prompt o el modelo mejora la calidad sin disparar el coste operativo.
Evaluación con datasets y LLM-as-judge
Define un conjunto de casos de prueba, ejecuta el agente sobre ellos y evalúa cada respuesta con criterios personalizados — calidad, fidelidad al contexto, coherencia, ausencia de alucinaciones — usando otro LLM como evaluador automático. Los resultados se agregan en un scorecard que permite comparar versiones del agente de forma objetiva.
Planes y precios de LangSmith
LangSmith tiene una capa gratuita que incluye hasta 5.000 trazas al mes con retención de 14 días — suficiente para desarrollo y testing. El plan Developer (39 USD/mes) amplía a 100.000 trazas y retención de 90 días. Los planes Team y Enterprise ofrecen SSO, control de acceso por roles y volumen ilimitado. La configuración se hace en smith.langchain.com .
Agentes en LangChain: ReAct, tool calling y salida estructurada
LangChain soporta varios mecanismos de agencia según el modelo y el tipo de tarea. Entender las diferencias ayuda a elegir el patrón correcto.
El patrón ReAct: razonar antes de actuar
ReAct (Reasoning + Acting) es el patrón de agencia más usado en LangChain. El modelo recibe el objetivo, los nombres y descripciones de las herramientas disponibles, y ejecuta un loop: razona en voz alta sobre qué herramienta usar (Thought), emite la llamada a la herramienta (Action), recibe el resultado (Observation) y vuelve a razonar hasta que considera que tiene suficiente información para responder. Este patrón funciona bien con modelos capaces como Claude Sonnet y Opus, GPT-4 y Gemini Pro, pero puede producir bucles infinitos con modelos menos capaces — un punto de fragilidad que LangGraph resuelve con límites de iteración y condiciones de salida explícitas.
Tool calling: el estándar actual para modelos de API
La mayoría de los modelos de API modernos (OpenAI, Anthropic, Google) exponen
un mecanismo nativo de tool calling: el desarrollador pasa la lista de herramientas
disponibles con su schema JSON en el request, y el modelo devuelve una llamada
estructurada a la herramienta en lugar de texto libre. LangChain abstrae este
mecanismo con la clase ChatModel.bind_tools(), lo que permite usar
el mismo código de agente independientemente de si el modelo subyacente es Claude,
GPT o Gemini. El uso de tool calling nativo es más fiable que el patrón ReAct
basado en parseo de texto — el modelo no puede "inventarse" el nombre de una
herramienta que no existe en el schema.
Salida estructurada: cuando el agente necesita devolver datos
LangChain facilita la extracción de datos estructurados mediante with_structured_output(),
que combina tool calling con un modelo Pydantic para garantizar que la salida del
modelo siempre tiene el formato esperado. Esto es especialmente útil en pipelines
donde la salida del LLM es consumida por otro sistema: formularios, APIs, bases
de datos o herramientas downstream. Si necesitas
crear un agente en Python que extraiga información estructurada de texto no
estructurado, este patrón es el punto de partida recomendado.
| Patrón | Cómo funciona | Mejor para | Requisito |
|---|---|---|---|
| ReAct | El modelo razona en texto libre y llama herramientas con formato Thought/Action/Observation | Prototipos rápidos, modelos sin tool calling nativo | Modelo con capacidad de razonamiento |
| Tool Calling | El modelo devuelve llamadas estructuradas via schema JSON | Agentes de producción con modelos modernos | Modelo con soporte de function/tool calling |
| Structured Output | El modelo devuelve un objeto Pydantic validado | Extracción de datos, integración con sistemas downstream | Schema Pydantic definido |
| LangGraph Agent | Grafo dirigido con estado persistente y aristas condicionales | Flujos complejos con ciclos, bifurcaciones y estado acumulativo | LangGraph instalado |
| Multi-agent (LangGraph) | Un agente coordinador delega a sub-agentes especializados vía sub-grafos | Tareas complejas que requieren especialización paralela | LangGraph + diseño explícito del grafo de agentes |
LangChain vs alternativas: ¿cuándo elegir cada uno?
LangChain es el framework más completo, pero no siempre es el más adecuado. Esta comparativa ayuda a elegir según el contexto real del proyecto.
| Criterio | LangChain | CrewAI | PydanticAI | LlamaIndex |
|---|---|---|---|---|
| Paradigma principal | Chains y agents con LCEL | Roles declarativos (Agent/Task/Crew) | Agentes tipados con Pydantic v2 | RAG y acceso a datos estructurados |
| Curva de aprendizaje | Media-alta (muchas abstracciones) | Baja — API intuitiva | Media — requiere conocer Pydantic | Media — foco en indexación |
| Integraciones | +600 — ecosistema más amplio | ~100 herramientas integradas | Principalmente via tools propias | +30 bases de datos vectoriales |
| Sistemas multi-agente | LangGraph con sub-grafos | Nativo y declarativo | Limitado | A traves de LlamaAgents |
| RAG avanzado | Bueno con muchos retrievers | Básico | Básico | Especializado — la fortaleza clave |
| Validación de tipos | A traves de Pydantic manual | Moderada | Nativa — integración Pydantic v2 | Moderada |
| Observabilidad | LangSmith — plataforma dedicada | CrewAI+ con observabilidad integrada | Via OpenTelemetry | Via callbacks y OpenTelemetry |
| Orquestación de flujo | LangGraph — grafos con estado | Sequential / Hierarchical | Lineal con herramientas | Flujos básicos |
| Estrellas GitHub (mayo 2026) | ~92k | ~50k | ~17k | ~49k |
| Mejor para | Proyectos con muchas integraciones y flujos complejos | Equipos multi-agente con roles claros | Fiabilidad y validación estricta en producción | RAG sobre documentos propios |
Regla de decisión rápida
Elige LangChain cuando necesites muchas integraciones con sistemas externos, cuando el flujo del agente requiera estado persistente y bifurcaciones (LangGraph), o cuando quieras observabilidad de producción de primera clase (LangSmith). Elige CrewAI cuando el caso de uso sea un equipo de agentes con roles bien definidos y quieras una API más sencilla. Elige PydanticAI cuando la validación estricta de tipos en las entradas y salidas de las herramientas sea la prioridad. Elige LlamaIndex cuando el caso de uso sea principalmente RAG sobre grandes volúmenes de documentación propia. Para construir tu primer agente en Python paso a paso, la guía de como crear un agente en Python empieza desde cero con ejemplos funcionales.
Preguntas frecuentes sobre LangChain
LangChain es un framework de código abierto en Python (y JavaScript) que facilita la construcción de aplicaciones y agentes basados en modelos de lenguaje de gran escala (LLM). Proporciona abstracciones para chains (cadenas de pasos), agents (agentes con herramientas), memory (memoria conversacional), retrievers (recuperadores de información) y más de 600 integraciones con servicios externos. Es el framework más usado en proyectos de producción a nivel global a mayo de 2026.
LangChain es el framework base que proporciona los componentes reutilizables (chains, agents, tools, memory). LangGraph es una extensión construida sobre LangChain que modela el flujo de ejecución de un agente como un grafo dirigido con estados tipados. LangGraph se usa cuando el flujo del agente requiere ciclos, bifurcaciones condicionales o persistencia de estado entre pasos. Para agentes lineales simples, LangChain es suficiente; para flujos de control complejos, LangGraph es la opción recomendada.
LangSmith es la plataforma de observabilidad y debugging para aplicaciones LangChain. Permite trazar cada llamada al LLM, ver el prompt exacto enviado, el tiempo de respuesta, los tokens usados y el coste estimado. Tiene una capa gratuita con hasta 5.000 trazas al mes. Los planes de pago empiezan desde los 39 USD al mes para desarrolladores individuales. Es especialmente útil en producción para detectar regresiones en el comportamiento del agente cuando se cambia el modelo o el prompt del sistema.
Sí. LangChain tiene integración nativa con Ollama a través del paquete
langchain-ollama. Cualquier modelo disponible en Ollama (Llama 3,
Mistral, Qwen, Phi, etc.) se puede usar exactamente igual que un modelo de
OpenAI o Anthropic, cambiando solo la clase del modelo en la configuración.
Esto permite desarrollar en local con modelos open source y desplegar en
producción con modelos propietarios sin cambiar la lógica del agente.
LangChain es la mejor elección cuando necesitas muchas integraciones con servicios externos, cuando quieres construir pipelines RAG de producción, o cuando tu equipo ya tiene experiencia con el ecosistema LangChain. CrewAI es mejor para sistemas multi-agente con roles declarativos. PydanticAI es mejor cuando la validación estricta de tipos en las entradas y salidas de las herramientas es la prioridad. Para agentes complejos con flujo de control no lineal, LangGraph (parte del ecosistema LangChain) es la opción más madura disponible.