- 171 000 estrellas y 16 100 forks en GitHub a mayo de 2026: uno de los proyectos de IA local con mayor crecimiento.
- Escrito en Go (66,8%) y C (27%) sobre llama.cpp: arquitectura que permite un binario único y portable con alto rendimiento nativo.
- Más de 214 releases publicados, con cadencia aproximada de una release por semana. Última estable: v0.23.2 (7 mayo 2026).
- El ecosistema de integraciones incluye más de 200 proyectos de la comunidad: interfaces web, extensiones de editor, frameworks de agentes y librerías.
- Open WebUI, la interfaz web más popular para Ollama, cuenta con 137 000 estrellas propias en GitHub.
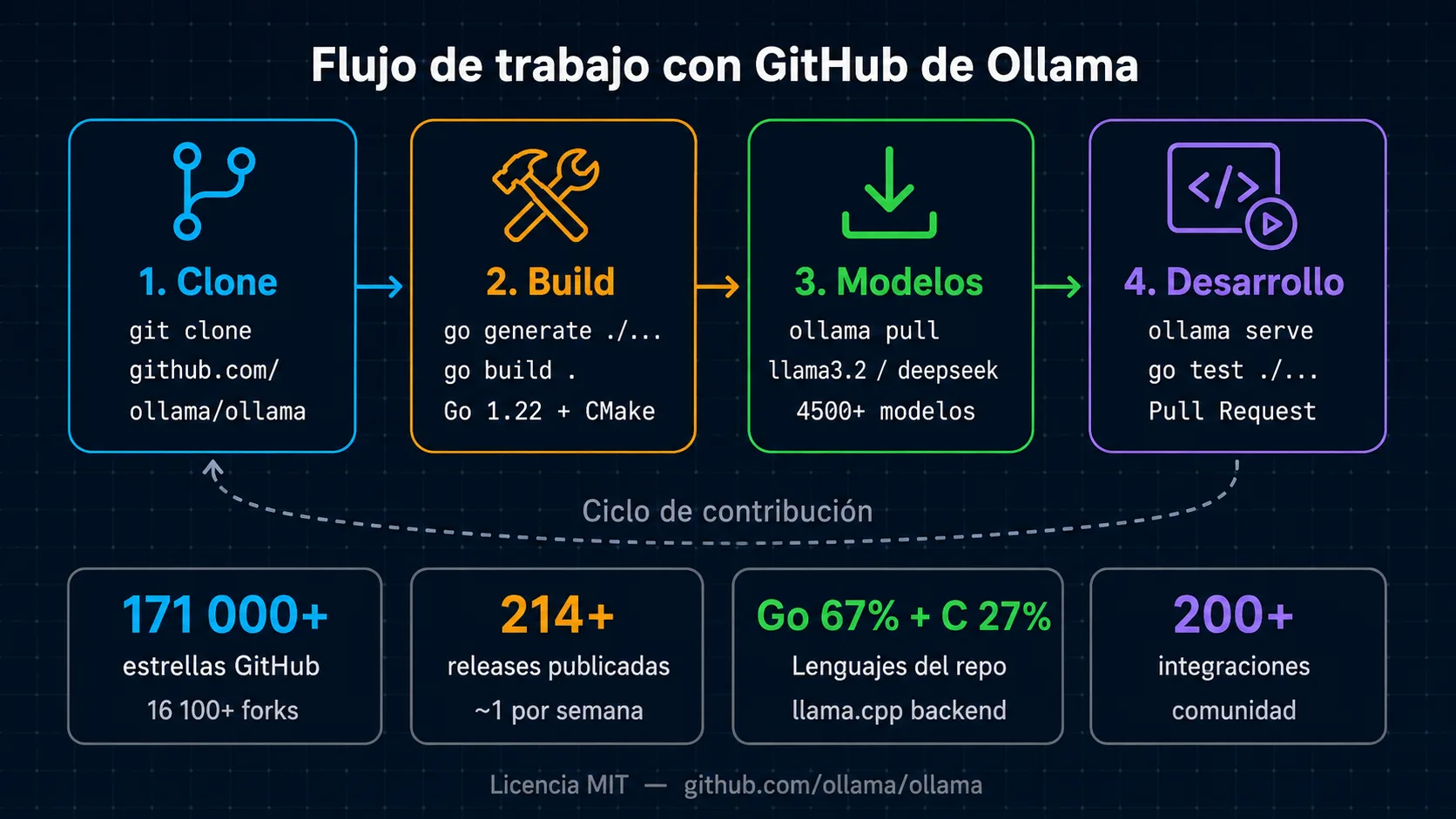
Estadísticas del repositorio GitHub de Ollama
El repositorio github.com/ollama/ollama se ha convertido en uno de los proyectos open-source de infraestructura de IA más importantes del ecosistema.
| Lenguaje | Porcentaje | Uso principal |
|---|---|---|
| Go | 66,8% | Servidor HTTP, API REST, gestión de modelos, CLI, orquestación |
| C | 27,0% | Inferencia de bajo nivel (llama.cpp), bindings de GPU, cuantización |
| TypeScript | 3,2% | Herramientas de desarrollo, tests de integración de la API |
| C++ | 1,1% | Extensiones de llama.cpp, soporte Metal (Apple Silicon) |
| Shell | 0,5% | Scripts de instalación y CI/CD |
| Objective-C | 0,5% | Integración macOS nativa |
Estructura del proyecto: cómo está organizado el código
Entender la estructura del repositorio facilita tanto la contribución al proyecto como la comprensión de cómo Ollama gestiona los modelos internamente.
El repositorio tiene una organización clara que separa las responsabilidades en capas: la capa de servidor y API en Go, la capa de inferencia en C/C++ (basada en llama.cpp) y los bindings entre ambas. Las carpetas principales son:
api/ — definiciones de la API
Estructuras de datos Go para todas las peticiones y respuestas de la API REST.
Aquí se definen los tipos que corresponden a los endpoints
/api/generate, /api/chat, /api/embed
y el resto de la API publica.
server/ — lógica del servidor
El servidor HTTP en Go que expone la API, gestiona las peticiones concurrentes, coordina la carga y descarga de modelos, y gestiona las sesiones de chat. Es el núcleo de Ollama como servicio.
llm/ — motor de inferencia
Bindings Go para llama.cpp y la lógica de gestión de backends de inferencia. Esta capa abstrae las diferencias entre CPU, CUDA (NVIDIA), ROCm (AMD) y Metal (Apple Silicon), exponiendo una interfaz unificada al servidor.
model/ — gestión de modelos
Lógica para descargar, verificar, almacenar y cargar modelos en formato GGUF. Gestiona el registro local de modelos, el sistema de capas (layers) similar a Docker y la compatibilidad de formatos.
cmd/ — interfaz de línea de comandos
La CLI de Ollama: los comandos run, pull,
push, list, rm y serve.
Implementados sobre la API interna con salida adaptada para terminal.
docs/ — documentación técnica
Referencia de la API, guías de desarrollo, FAQ técnico y notas de compatibilidad. La documentación principal está migrando a docs.ollama.com pero el repositorio mantiene la versión de referencia en Markdown.
Últimas releases: qué hay de nuevo en Ollama
Ollama publica nuevas versiones con alta frecuencia. Las releases recientes muestran el enfoque actual del proyecto: rendimiento, soporte para Apple Silicon y mejoras de integración.
v0.23.3 — 12 mayo 2026 (pre-release)
Mejoras en el backend MLX para Apple Silicon: comportamiento de push de modelos refinado y corrección de fugas del target macOS 26 en archivos metallib. Orientado a mejorar la estabilidad en los Macs con chip Apple.
v0.23.2 — 7 mayo 2026 (estable)
Las respuestas de /api/show ahora se cachean, mejorando la
latencia mediana en un 6,7x para aplicaciones que consultan
información del modelo frecuentemente (como integraciones de Claude Desktop).
Se eliminó el soporte de Claude Desktop del comando ollama launch.
v0.23.1 — 5 mayo 2026
Soporte de decodificación especulativa MTP para Gemma 4 en Mac. El resultado pratico es una mejora de más del 2x en velocidad para el modelo Gemma 4 31B en tareas de código en hardware Apple Silicon.
v0.23.0 — 3 mayo 2026
Integración con Claude Desktop y Claude Code via ollama launch.
Recomendaciones de modelos impulsadas por el servidor que no requieren actualizar
Ollama. Mejoras en la inicialización de Metal en macOS.
v0.22.1 — 28 abril 2026
Renderer actualizado para Gemma 4 con mejoras en thinking y tool-calling. Las recomendaciones de modelos ahora se pueden actualizar independientemente de la versión de Ollama instalada, separando el ciclo de vida de datos y software.
Puedes ver el historial completo de releases en github.com/ollama/ollama/releases . Para recibir notificaciones de nuevas versiones, usa el boton "Watch" del repositorio y selecciona "Releases only" en la configuración de notificaciones de GitHub.
Cómo contribuir al repositorio de Ollama
Ollama acepta contribuciones de la comunidad según el proceso estándar de GitHub. Aquí tienes los pasos concretos y los tipos de contribución más bienvenidos.
Proceso de contribución paso a paso
1. Fork y clone
Haz fork del repositorio en tu cuenta de GitHub y clona tu fork en local. Agrega el repositorio original como remote upstream para mantener tu fork actualizado.
2. Rama de trabajo
Crea una rama con un nombre descriptivo del cambio que vas a hacer.
Convenciones habituales: fix/nombre-del-bug,
feat/nombre-de-la-feature, docs/seccion.
3. Desarrollar y testar
Implementa el cambio y ejecuta los tests del proyecto con go test ./....
Para cambios en la interfaz de usuario de la CLI, verifica el comportamiento
manual con go run . serve en modo desarrollo.
4. Pull Request
Abre un Pull Request contra la rama main del repositorio
original. El PR debe incluir: descripción clara del cambio, razón del cambio,
cómo testarlo y referencias a Issues relacionados si los hay.
Comandos de desarrollo
# Clonar el repositorio (usa tu fork)
git clone https://github.com/TU_USUARIO/ollama.git
cd ollama
# Agregar upstream para sincronizar con el original
git remote add upstream https://github.com/ollama/ollama.git
# Actualizar tu fork con los cambios del original
git fetch upstream
git merge upstream/main
# Crear una rama de trabajo
git checkout -b fix/nombre-del-bug
# Compilar para verificar que el codigo compila
go build .
# Ejecutar tests
go test ./...
# Iniciar el servidor en modo desarrollo
go run . serve
# En otra terminal: probar con la CLI local
go run . run llama3.2:3bTipos de contribución bienvenidos
docs/, ejemplos de uso
y guías de integración. La documentación en español no existe en el
repositorio oficial: una oportunidad de contribución única.
Compilar Ollama desde el código fuente
Compilar Ollama desde el código fuente es necesario cuando quieres aplicar parches propios, usar una versión de desarrollo o contribuir al proyecto. El proceso requiere Go, CMake y un compilador C.
Requisitos previos
go version.
Compilación en Linux y macOS
# 1. Clonar el repositorio
git clone https://github.com/ollama/ollama.git
cd ollama
# 2. Compilar las dependencias nativas (llama.cpp y backends GPU)
# Este paso descarga y compila las dependencias de C/C++)
go generate ./...
# 3. Compilar el binario de Ollama
go build .
# 4. Verificar que el binario funciona
./ollama --version
# 5. Iniciar el servidor con el binario compilado
./ollama serveCompilación con soporte CUDA (NVIDIA)
# Instalar CUDA Toolkit 11.8+ antes de compilar
# https://developer.nvidia.com/cuda-downloads
# Verificar que nvcc esta disponible
nvcc --version
# Compilar con soporte CUDA activado automaticamente
# go generate detecta CUDA y activa el backend correspondiente
go generate ./...
go build .
# Verificar que el backend CUDA esta disponible
./ollama infoCompilación en Windows
# Requisitos adicionales en Windows:
# - Visual Studio Build Tools 2022 con "Desktop development with C++"
# - O MinGW-w64 (gcc para Windows)
# En PowerShell con el entorno de VS activado:
git clone https://github.com/ollama/ollama.git
cd ollama
# Compilar dependencias (puede tardar varios minutos)
go generate ./...
# Compilar el ejecutable
go build -o ollama.exe .
# Verificar
.\ollama.exe --version
El paso go generate ./... es el que más tiempo consume: descarga
y compila llama.cpp junto con los backends de GPU. En una maquina moderna
puede tardar entre 5 y 20 minutos dependiendo del hardware. Los pasos
posteriores son rápidos (menos de 1 minuto para el binario Go).
Integraciones de la comunidad: el ecosistema alrededor de Ollama
El repositorio oficial de Ollama lista más de 200 integraciones de la comunidad. Aquí presentamos las más utilizadas y con mayor impacto en el ecosistema.
Interfaces web y de escritorio
- Lobe Chat — interfaz moderna con plugins
- Msty — aplicación de escritorio nativa para macOS y Windows
- Enchanted — cliente nativo para iOS y macOS
- Chatbox — aplicación de escritorio multiplataforma
- AnythingLLM — enfocado en RAG y documentos
Extensiones para editores de código
- CodeGPT — extensión VS Code con soporte Ollama
- Ollama para Neovim — plugin para usuarios de Neovim
- tgpt — cliente de terminal para Ollama
- Aider — asistente de código en terminal con soporte Ollama
- Cursor — acepta Ollama como backend OpenAI-compatible
Frameworks de agentes y librerías
langchain-ollama.
Permite usar cualquier modelo de Ollama como LLM base para cadenas,
agentes, RAG y pipelines complejos en Python o JavaScript.
| Integración | Categoría | Estrellas GitHub | Descripción |
|---|---|---|---|
| Open WebUI | Interfaz web | ~137 000 | Chat completo con RAG, gestión de modelos y multiusuario |
| Continue | Extensión editor | ~33 000 | Asistente de código para VS Code y JetBrains |
| LangChain (Python) | Framework agentes | ~100 000 | Integración oficial via langchain-ollama |
| LlamaIndex | Framework RAG | ~40 000 | LLM y embeddings locales para pipelines RAG |
| AnythingLLM | Interfaz RAG | ~40 000 | Chat con documentos propios usando Ollama en local |
| Msty | App escritorio | — | Cliente nativo para macOS y Windows con gestión de modelos |
| Crawl4AI | Web crawling | ~30 000 | Extracción de datos web con LLMs locales via Ollama |
Issues, discusiones y recursos de la comunidad
Además del repositorio GitHub, Ollama tiene una comunidad activa en varios canales donde puedes encontrar ayuda, compartir proyectos y seguir las novedades del proyecto.
good first issue que
identifican bugs apropiados para nuevos contribuidores.
Preguntas frecuentes sobre el repositorio GitHub de Ollama
El repositorio de Ollama en GitHub supera las 171.000 estrellas a mayo de 2026, con más de 16.100 forks. Es uno de los repositorios de herramientas de IA en local con mayor crecimiento en los últimos dos años, y figura entre los proyectos más destacados de la categoría de infraestructura de IA open-source.
Ollama está escrito principalmente en Go (66,8% del código), que gestiona la lógica del servidor, la API REST y la orquestación de modelos. El 27% está en C, correspondiente a las capas de inferencia de bajo nivel basadas en llama.cpp. Esta combinación permite un binario único y portable con alto rendimiento en inferencia nativa sin dependencias externas en tiempo de ejecución.
Para contribuir a Ollama hay que hacer fork del repositorio en github.com/ollama/ollama, crear una rama con el cambio, asegurarse de que los tests pasan con go test ./..., y abrir un Pull Request describiendo el cambio. Para cambios grandes es recomendable abrir primero un Issue discutiendo el enfoque con los mantenedores. Los tipos de contribución más bienvenidos son correcciones de bugs, mejoras de documentación, soporte para nuevos modelos y mejoras de rendimiento.
La última versión estable a mayo de 2026 es v0.23.2, publicada el 7 de mayo. Esta versión incluye caché de respuestas /api/show que mejora la latencia mediana en 6,7x para integraciones que consultan información del modelo frecuentemente. El repositorio publica releases con frecuencia aproximada de una por semana, con un total de más de 214 releases desde el inicio del proyecto.
El ecosistema de integraciones de Ollama es muy amplio. Las más destacadas son: Open WebUI (137K estrellas, interfaz web tipo ChatGPT), Continue (33K estrellas, extensión para VS Code y JetBrains), integración oficial en LangChain, soporte en LlamaIndex, Dify, Flowise y otros frameworks de agentes. El repositorio oficial mantiene una lista curada de más de 200 integraciones en su README.
Sí. Para compilar Ollama desde el código fuente necesitas Go 1.22+, CMake 3.24+ y un compilador C/C++ (GCC en Linux, Xcode Command Line Tools en macOS, MSVC o MinGW en Windows). El proceso es: clonar el repositorio, ejecutar go generate ./... para compilar las dependencias nativas de llama.cpp (este paso puede tardar 5-20 minutos), y luego go build . para obtener el binario. La documentación detallada está en el archivo DEVELOPMENT.md del repositorio.