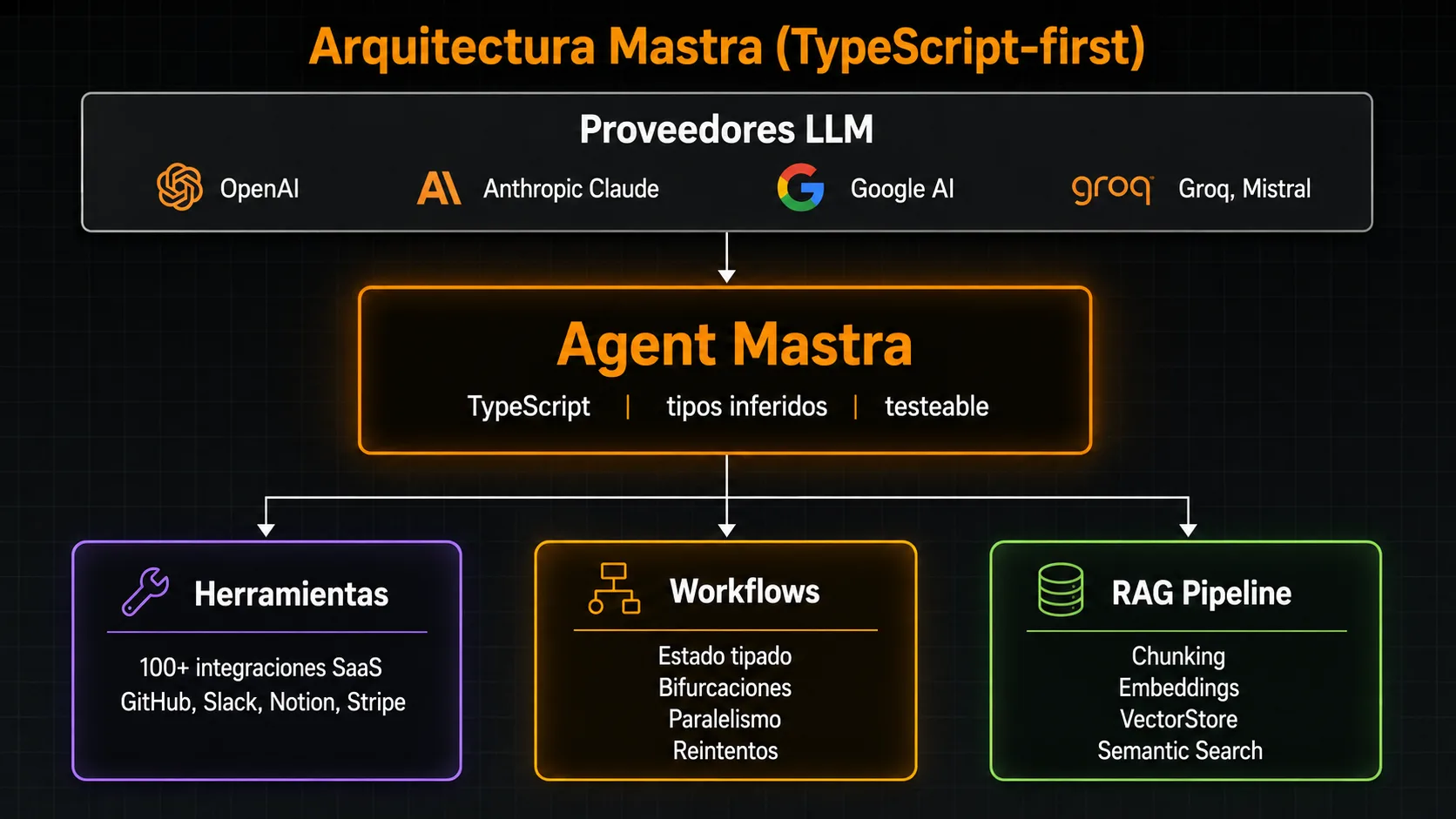
- Mastra es TypeScript-first: tipos nativos en todo el API, lo que elimina los errores de schema en tiempo de ejecución que son habituales con frameworks Python desde JavaScript.
- Incluye un motor de workflows con ejecución paso a paso, bifurcaciones condicionales, paralelismo y manejo de errores — sin dependencias adicionales.
- El pipeline RAG integrado cubre chunking, generación de embeddings, almacenamiento vectorial y búsqueda por similitud semántica con una sola API coherente.
- Más de 100 integraciones preconstruidas con herramientas SaaS (GitHub, Slack, Google, Notion, Stripe, etc.) listas para usar como herramientas de agente.
- Soporta OpenAI, Anthropic Claude y Google AI de forma nativa, con una abstracción que permite cambiar de modelo sin modificar la lógica del agente.
¿Qué es Mastra y por qué el enfoque TypeScript-first cambia las reglas?
Mastra es un framework de código abierto para construir agentes IA, workflows y sistemas RAG en TypeScript. Nació de la necesidad real de los equipos de desarrollo full-stack que trabajan con TypeScript o JavaScript: la mayoría de los frameworks de agentes más maduros son Python-first, lo que obliga a mantener dos lenguajes distintos en el mismo proyecto o a conectar el backend de IA con el resto de la aplicación a través de microservicios adicionales. La documentación oficial está en mastra.ai/docs y el repositorio en github.com/mastra-ai/mastra con más de 10.000 estrellas a mayo de 2026.
La propuesta de valor de Mastra no es simplemente "LangChain pero en TypeScript". El framework está diseñado desde cero con TypeScript en mente: los schemas de las herramientas se infieren del tipado, los workflows tienen estado tipado en cada paso, y el compilador detecta en tiempo de desarrollo si una herramienta recibe argumentos del tipo incorrecto o si un paso del workflow intenta acceder a una propiedad que no existe en el estado. Esto reduce drásticamente los errores en tiempo de ejecución que son habituales cuando se construyen agentes con frameworks Python desde una aplicación Node.js.
Mastra se instala como un paquete npm y vive dentro de la aplicación TypeScript existente. No requiere un servicio separado ni un runtime especial: los agentes, workflows y pipelines RAG son funciones TypeScript normales que se pueden llamar desde cualquier parte de la aplicación. Esta integración nativa es especialmente valiosa en proyectos Next.js, Remix o Node.js donde la lógica de IA es parte de la aplicación y no un microservicio externo. Para entender el panorama completo de opciones disponibles, la guía de modelos LLM y la sección de comparativas dan el contexto necesario.
A mayo de 2026, Mastra es comparable en funcionalidad a LangChain para los casos de uso más habituales (agentes con herramientas, RAG, workflows), con la ventaja de una experiencia de desarrollo mucho más integrada para equipos TypeScript. Para desarrolladores Python, LangChain sigue siendo la opción más madura y con más integraciones disponibles. Para quienes necesiten la integración más directa con Claude de Anthropic, el Claude Agent SDK es la referencia.
Conceptos clave: agentes, herramientas, workflows y RAG
Mastra organiza sus primitivas en cuatro capas complementarias. Entender cada una es el punto de partida para diseñar un sistema de agentes bien estructurado.
Agentes: el núcleo de razonamiento
Un agente en Mastra combina un modelo LLM, un system prompt, un conjunto de herramientas disponibles y, opcionalmente, acceso a memoria persistente. El agente ejecuta un loop de razonamiento hasta completar la tarea: llama a las herramientas que necesita, observa los resultados e incorpora esa información al contexto. Los agentes Mastra son objetos TypeScript tipados: el compilador detecta si una herramienta no existe o si el schema de entrada no coincide.
Herramientas: las capacidades del agente
Las herramientas son funciones TypeScript que el agente puede invocar. Cada herramienta tiene un nombre, una descripción en lenguaje natural (que el modelo usa para decidir cuándo invocarla), un schema de entrada definido con Zod y una función de ejecución. Mastra infiere automáticamente el schema JSON que se envía al modelo desde la definición Zod, eliminando la necesidad de mantener dos fuentes de verdad para el mismo schema.
Workflows: orquestación paso a paso
Los workflows de Mastra permiten definir secuencias de pasos con estado persistente, bifurcaciones condicionales y ejecución paralela. Cada paso recibe el estado actual del workflow, procesa su lógica (que puede incluir llamadas a agentes, herramientas o cualquier función TypeScript) y devuelve una actualización del estado. El motor gestiona la ejecución, la recuperación de errores y la transición entre pasos sin código imperativo adicional.
RAG pipeline: acceso a conocimiento propio
El pipeline RAG de Mastra cubre todo el ciclo: ingesta de documentos desde múltiples fuentes, chunking con estrategias configurables, generación de embeddings vía el proveedor elegido, almacenamiento en una base de datos vectorial y búsqueda por similitud semántica en el momento de inferencia. La misma API coherente funciona con Pinecone, Weaviate, Chroma, pgvector y otras bases de datos vectoriales populares.
Memoria: contexto que persiste entre sesiones
Mastra incluye un sistema de memoria que permite al agente recordar información entre conversaciones distintas. La memoria se almacena en una base de datos configurada por el desarrollador y se recupera mediante búsqueda semántica: el agente recibe automáticamente los recuerdos más relevantes para la consulta actual sin necesidad de enviar el historial completo en cada llamada, lo que reduce el consumo de tokens en sesiones largas.
Observabilidad integrada
Mastra incluye trazado de ejecuciones integrado compatible con OpenTelemetry. Cada llamada al agente, cada paso del workflow y cada búsqueda RAG genera spans observables que se pueden enviar a cualquier backend de observabilidad (Jaeger, Grafana Tempo, Datadog, etc.). Esto permite diagnosticar cuellos de botella y entender el comportamiento del agente en producción sin instrumentación manual adicional.
| Primitiva | Qué hace | Cuándo usarla | Paquete npm |
|---|---|---|---|
| Agent | Loop de razonamiento con LLM + herramientas + memoria | Cualquier tarea que requiera planificación y uso de herramientas | @mastra/core |
| Tool | Función TypeScript invocable por el agente con schema Zod | Cada capacidad externa que el agente necesite (APIs, bases de datos, etc.) | @mastra/core |
| Workflow | Secuencia de pasos con estado tipado, bifurcaciones y paralelismo | Procesos de negocio con lógica condicional o paralela | @mastra/core |
| RAG | Pipeline completo de ingesta, embeddings y búsqueda vectorial | Agentes que necesitan responder sobre documentación o datos propios | @mastra/rag |
| Memory | Persistencia de contexto entre sesiones con recuperación semántica | Asistentes con sesiones largas o historial acumulativo | @mastra/memory |
| Integration | Conector preconstruido con un servicio externo (GitHub, Slack, etc.) | Cuando necesitas herramientas de un servicio SaaS sin escribirlas desde cero | @mastra/<nombre> |
¿Cómo se instala Mastra y cómo es el primer agente?
Mastra se instala como cualquier paquete npm. En menos de 20 líneas de TypeScript tienes un agente funcional con herramientas personalizadas.
Instalación
Mastra requiere Node.js 18 o superior y TypeScript 5.0 o superior. El paquete
principal es @mastra/core. Los paquetes de integración y capacidades
adicionales (RAG, memoria, integraciones específicas) se instalan por separado
según lo que necesite el proyecto:
# Paquete principal (agentes, herramientas y workflows)
npm install @mastra/core
# Pipeline RAG (chunking, embeddings, búsqueda vectorial)
npm install @mastra/rag
# Gestión de memoria persistente
npm install @mastra/memory
# Ejemplo: integración con GitHub
npm install @mastra/githubPrimer agente con herramienta personalizada
El siguiente ejemplo muestra como definir una herramienta con schema Zod, crear un agente que la utiliza y ejecutar una consulta. El compilador TypeScript garantiza que los argumentos de la herramienta son del tipo correcto en tiempo de compilación, antes de que el código se ejecute:
import { Agent, createTool } from '@mastra/core';
import { anthropic } from '@mastra/core/llm/anthropic';
import { z } from 'zod';
// Definicion de una herramienta con schema Zod tipado
const weatherTool = createTool({
id: 'get-weather',
description: 'Obtiene el tiempo actual para una ciudad',
inputSchema: z.object({
city: z.string().describe('Nombre de la ciudad'),
units: z.enum(['celsius', 'fahrenheit']).default('celsius'),
}),
execute: async ({ context }) => {
// El tipo de context.city y context.units se infiere del schema
const response = await fetch(
`https://api.weather.example.com?city=${context.city}&units=${context.units}`
);
return await response.json();
},
});
// Creacion del agente
const weatherAgent = new Agent({
name: 'weather-agent',
instructions: 'Eres un asistente meteorologico. Usa la herramienta get-weather para responder sobre el tiempo actual.',
model: anthropic('claude-sonnet-4-5'),
tools: { weatherTool },
});
// Ejecucion
const result = await weatherAgent.generate(
'Que tiempo hace ahora mismo en Madrid?'
);
console.log(result.text);
La clave está en la función createTool: el schema Zod no solo
valida los argumentos en tiempo de ejecución, sino que Mastra lo usa para
generar automáticamente el schema JSON que se envía al modelo LLM en el
function calling. Una sola fuente de verdad para el tipo TypeScript, la
validación en runtime y el schema que entiende el modelo.
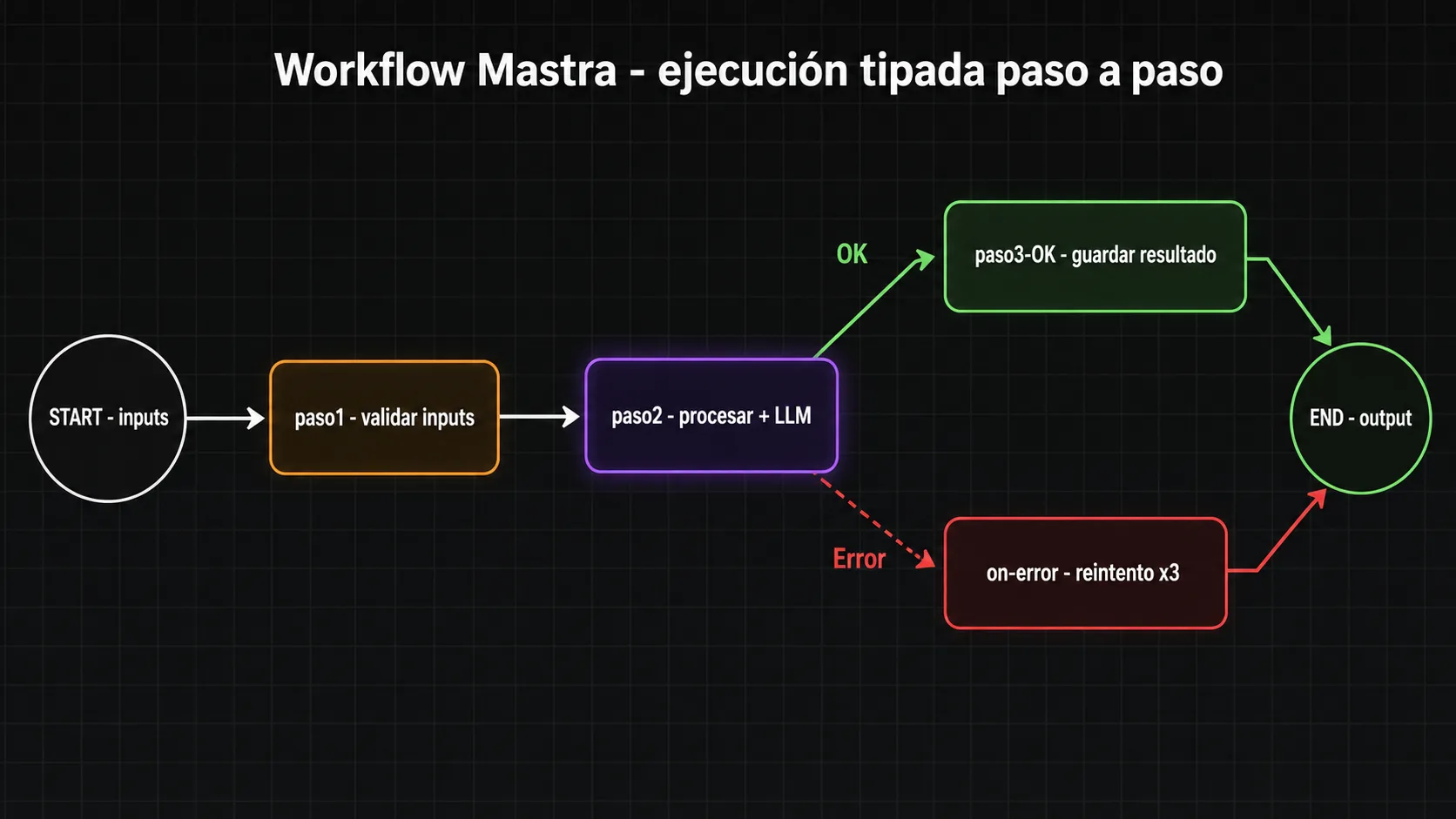
Motor de workflows: ¿cómo funcionan los pasos, las bifurcaciones y el paralelismo?
El motor de workflows de Mastra permite definir procesos de múltiples pasos con estado tipado, lógica condicional y ejecución paralela sin código imperativo adicional.
Modelo de ejecución de workflows
Un workflow en Mastra es una secuencia de pasos donde cada paso es una función TypeScript que recibe el estado actual del workflow y devuelve una actualización parcial o total de ese estado. El motor gestiona la transición entre pasos, el manejo de errores y la ejecución condicional o paralela. El estado del workflow es un objeto TypeScript tipado con Zod, lo que garantiza que cada paso solo puede acceder a las propiedades que existen en el esquema definido.
import { Workflow, Step } from '@mastra/core';
import { z } from 'zod';
// Schema del estado del workflow
const researchState = z.object({
query: z.string(),
sources: z.array(z.string()).default([]),
summary: z.string().optional(),
qualityScore: z.number().optional(),
});
const researchWorkflow = new Workflow({
name: 'research-workflow',
schema: researchState,
});
// Paso 1: buscar fuentes (se ejecuta siempre)
researchWorkflow.step(new Step({
id: 'search-sources',
execute: async ({ context }) => {
const sources = await searchWeb(context.query);
return { sources };
},
}));
// Paso 2: resumir (bifurcacion: solo si hay fuentes suficientes)
researchWorkflow.step(new Step({
id: 'summarize',
when: async ({ context }) => context.sources.length >= 3,
execute: async ({ context }) => {
const summary = await agent.generate(
`Resume estas fuentes sobre: ${context.query}\n\n${context.sources.join('\n')}`
);
return { summary: summary.text };
},
}));
// Paso 3: evaluar calidad
researchWorkflow.step(new Step({
id: 'evaluate',
execute: async ({ context }) => {
const score = await evaluateQuality(context.summary ?? '');
return { qualityScore: score };
},
}));
// Ejecutar el workflow
const result = await researchWorkflow.execute({
triggerData: { query: 'frameworks TypeScript para agentes IA 2026' },
});Ejecución paralela de pasos
Mastra soporta ejecución paralela de pasos que no dependen entre sí. En lugar de esperar a que cada paso termine antes de empezar el siguiente, el motor puede lanzar varios pasos al mismo tiempo y continuar cuando todos hayan completado. Esto reduce el tiempo total de ejecución en workflows donde hay tareas independientes que pueden procesarse de forma concurrente:
// Pasos paralelos: se ejecutan al mismo tiempo
researchWorkflow.parallel([
new Step({
id: 'search-academic',
execute: async ({ context }) => ({
academicSources: await searchAcademic(context.query),
}),
}),
new Step({
id: 'search-news',
execute: async ({ context }) => ({
newsSources: await searchNews(context.query),
}),
}),
new Step({
id: 'search-github',
execute: async ({ context }) => ({
githubRepos: await searchGitHub(context.query),
}),
}),
]);
// El siguiente paso recibe los resultados de los tres pasos anteriores
researchWorkflow.step(new Step({
id: 'merge-sources',
execute: async ({ context }) => ({
sources: [
...context.academicSources,
...context.newsSources,
...context.githubRepos,
],
}),
}));Manejo de errores y reintentos
Cada paso puede configurar una política de reintentos: número máximo de intentos, backoff exponencial y condiciones de reintento. Si un paso falla después de agotar los reintentos, el workflow puede continuar por una rama alternativa (fallback step) o detenerse y propagar el error al llamador. Esto evita que un fallo transitorio en una API externa detenga todo el proceso.
Workflows de larga duración con suspensión
Mastra soporta el patrón de suspensión de workflows: un paso puede emitir un evento y suspender la ejecución hasta recibir una respuesta externa (aprobación humana, webhook de un servicio, finalización de un proceso asíncrono). El estado del workflow se persiste durante la suspensión y se recupera cuando llega la respuesta, sin perder el contexto acumulado.
Trazado de workflows
Cada ejecución del workflow genera un registro completo con el estado en cada paso, el tiempo de ejecución de cada uno, los errores que se produjeron y cómo se resolvieron. Este registro es compatible con OpenTelemetry y se puede enviar a cualquier backend de observabilidad para diagnosticar comportamientos inesperados en producción.
Pipeline RAG: ¿cómo funciona el chunking, los embeddings y la búsqueda vectorial en Mastra?
Mastra incluye un pipeline RAG completo desde la ingesta de documentos hasta la recuperación semántica, con una API coherente que funciona con las principales bases de datos vectoriales.
Las cuatro fases del pipeline RAG de Mastra
RAG (Retrieval Augmented Generation) es el patrón que permite a un agente responder preguntas sobre documentación propia, bases de conocimiento internas o cualquier corpus de texto que no forme parte del entrenamiento del modelo. El pipeline de Mastra cubre las cuatro fases del ciclo completo:
Fase 1: ingesta de documentos
Mastra puede ingestar documentos desde múltiples fuentes: archivos locales (PDF, Markdown, texto plano, HTML), URLs, bases de datos SQL, APIs REST y cualquier fuente personalizada vía un loader propio. El documento se normaliza a texto plano preservando la estructura semántica (títulos, listas, tablas) para que el chunking posterior sea más preciso.
Fase 2: chunking con estrategia configurable
El texto se divide en fragmentos (chunks) de tamaño manejable para el modelo de embeddings. Mastra soporta varias estrategias de chunking: por tamaño fijo (número de tokens), por separadores semánticos (párrafos, secciones), chunking recursivo que respeta la estructura jerárquica del documento y chunking por oraciones para corpus de texto denso. El tamaño del chunk y el solapamiento entre chunks adyacentes se configuran por ingesta.
Fase 3: generación de embeddings
Cada chunk se convierte en un vector de embeddings usando el proveedor
configurado: OpenAI text-embedding-3-large,
text-embedding-3-small, Cohere Embed, Google Vertex AI o cualquier
modelo de embeddings compatible con la API de OpenAI. Los vectores se almacenan
junto con los metadatos del chunk (fuente original, posición en el documento,
fecha de ingesta) en la base de datos vectorial elegida.
Fase 4: búsqueda y recuperación semántica
En el momento de inferencia, la consulta del usuario se convierte en un vector de embeddings con el mismo modelo usado en la ingesta, y se buscan los N chunks más similares por similitud coseno. Mastra soporta búsqueda híbrida (semántica + keyword con BM25) para mejorar la precisión en corpus con terminología técnica específica. Los chunks recuperados se inyectan en el contexto del agente antes de generar la respuesta.
Bases de datos vectoriales compatibles
Mastra soporta las principales bases de datos vectoriales con una API coherente: Pinecone, Weaviate, Chroma, Qdrant, pgvector (PostgreSQL), Supabase Vector y Turso. Cambiar de una base de datos vectorial a otra es un cambio de configuración que no afecta al código del pipeline. Para entornos de desarrollo, Mastra incluye un backend en memoria que permite iterar sin levantar un servicio de base de datos.
El pipeline RAG completo se activa como una herramienta del agente, lo que permite combinar RAG con otras herramientas de forma transparente: el agente puede buscar en la base de conocimiento y, si no encuentra la respuesta, usar una herramienta de búsqueda web o llamar a una API externa, todo en el mismo loop de razonamiento.
Integraciones: ¿cómo se usan los 100 conectores preconstruidos?
Mastra incluye integraciones con los servicios SaaS más habituales. Cada integración expone las operaciones del servicio como herramientas listas para usar en un agente.
Una de las características más prácticas de Mastra es su sistema de integraciones. En lugar de escribir la lógica de autenticación, manejo de errores y serialización de cada API desde cero, Mastra proporciona paquetes de integración que exponen las operaciones más habituales de cada servicio como herramientas ya listas para usar en un agente. Las integraciones disponibles a mayo de 2026 cubren las categorías principales de herramientas SaaS:
Integration que permite envolver cualquier API REST como una
integración nativa. La autenticación (OAuth, API key, JWT) se gestiona una
vez y todas las herramientas de la integración la reutilizan automáticamente.
La lista completa de integraciones disponibles y sus herramientas expuestas está documentada en
mastra.ai/docs/integrations .
Cada integración tiene su propio paquete npm (@mastra/github,
@mastra/slack, etc.) para que el bundle final solo incluya las
dependencias que el proyecto realmente necesita.
Mastra vs LangChain vs CrewAI vs Claude Agent SDK: ¿cuál elegir?
Cada framework tiene un caso de uso principal. Esta comparativa ayuda a elegir el más adecuado según el lenguaje del equipo y los requisitos del proyecto.
| Criterio | Mastra | LangChain | CrewAI | Claude Agent SDK |
|---|---|---|---|---|
| Lenguaje principal | TypeScript | Python (JS secundario) | Python | Python (JS en beta) |
| Tipos e inferencia | Nativa — todo tipado con Zod | Parcial — Pydantic manual | Parcial — Pydantic manual | Parcial |
| Motor de workflows | Integrado — pasos, bifurcaciones, paralelo | LangGraph (paquete aparte) | Sequential / Hierarchical | Básico |
| RAG integrado | Si — @mastra/rag | Si — pero requiere más configuración | Básico | No nativo |
| Integraciones preconstruidas | ~100 | +600 | ~100 | Vía MCP (extensible) |
| Sistemas multi-agente | Posible via workflows | LangGraph sub-grafos | Nativo declarativo | Posible via handoffs |
| Modelos soportados | OpenAI, Anthropic, Google AI | +30 proveedores | OpenAI, Anthropic, Google, otros | Claude exclusivamente |
| Observabilidad | OpenTelemetry integrado | LangSmith dedicado | CrewAI+ integrado | Básica |
| Coste del framework | Gratuito — open source | Gratuito (LangSmith de pago) | Gratuito (CrewAI+ de pago) | Gratuito |
| Estrellas GitHub (mayo 2026) | ~10k | ~92k | ~50k | ~15k |
| Mejor para | Equipos TypeScript con workflows complejos | Python, muchas integraciones, flujos complejos | Equipos de agentes con roles declarativos | Máxima fidelidad con Claude de Anthropic |
Regla de decisión rápida
Elige Mastra cuando tu equipo trabaje en TypeScript o JavaScript y necesites un framework batteries-included con workflows, RAG e integraciones sin cambiar de lenguaje. Elige LangChain cuando trabajes en Python y necesites el ecosistema de integraciones más amplio disponible o flujos de control complejos con LangGraph. Elige CrewAI cuando el caso de uso sea un sistema multi-agente con roles bien definidos y quieras la API más declarativa posible. Elige Claude Agent SDK cuando quieras la integración más directa con Claude de Anthropic, en particular si usas funcionalidades específicas de Claude como computer use, extended thinking o MCP nativo.
Preguntas frecuentes sobre Mastra
Mastra es un framework TypeScript de código abierto para construir agentes IA, workflows y pipelines RAG. Diseñado desde cero para el ecosistema JavaScript y TypeScript, incluye un motor de workflows con ejecución paso a paso, bifurcaciones y paralelismo, un pipeline RAG integrado con chunking, embeddings y búsqueda vectorial, más de 100 integraciones preconstruidas con servicios externos, y soporte nativo para OpenAI, Anthropic Claude y Google AI. A mayo de 2026 supera las 10.000 estrellas en GitHub y es la alternativa de referencia a LangChain para desarrolladores TypeScript.
La diferencia principal es el lenguaje: LangChain es Python-first mientras que Mastra es TypeScript-first. Mastra ofrece tipos nativos en todo el API, inferencia de tipos en las definiciones de herramientas y workflows, y una experiencia de desarrollo integrada con el ecosistema Node.js. LangChain tiene un ecosistema más amplio (más de 600 integraciones frente a las 100 de Mastra), pero Mastra es la opción natural para equipos que trabajan en TypeScript y no quieren cambiar de lenguaje para el backend de IA.
Sí. Mastra es completamente gratuito y de código abierto. Puedes instalarlo
con npm install @mastra/core y usarlo sin coste en proyectos
comerciales. Los únicos costes son los de los modelos LLM que uses (OpenAI,
Anthropic, etc.) y los servicios de terceros que integres (bases de datos
vectoriales, APIs, etc.). No hay un plan SaaS ni licencias de pago del
propio framework a mayo de 2026.
Mastra soporta nativamente OpenAI (GPT-5.5, GPT-5, o3), Anthropic Claude (Claude Opus 4.7, Sonnet, Haiku y versiones posteriores) y Google AI (Gemini 3.1 Pro, Flash). Para otros proveedores, Mastra acepta cualquier endpoint compatible con la API de OpenAI, lo que incluye modelos locales servidos por Ollama, LM Studio o servicios como Together AI y Groq. La abstracción del proveedor se hace a nivel del constructor del agente, lo que permite cambiar de modelo sin modificar la lógica de negocio.
Mastra se instala con npm install @mastra/core. Si quieres
capacidades adicionales, instala los paquetes correspondientes:
@mastra/rag para el pipeline RAG o @mastra/memory
para la gestión de memoria. Mastra requiere Node.js 18 o superior y TypeScript
5.0 o superior. La configuración mínima es un objeto con el modelo del proveedor
elegido, el system prompt del agente y la lista de herramientas disponibles.
Elige Mastra cuando tu stack sea TypeScript o JavaScript y quieras un framework batteries-included sin cambiar de lenguaje, cuando necesites workflows complejos con bifurcaciones y ejecución paralela de pasos, o cuando quieras RAG integrado sin configurar una pipeline de vectores desde cero. Elige CrewAI si trabajas en Python y necesitas un sistema de agentes con roles declarativos. Elige Claude Agent SDK si quieres la integración más directa con Claude de Anthropic sin abstracciones adicionales.