- LlamaIndex es data-first: su fortaleza principal es conectar LLMs con fuentes de datos externas mediante RAG, indexación avanzada y query engines especializados.
- Más de 150 conectores (LlamaHub) cubren bases de datos, APIs, PDFs, sitios web, Google Drive, Notion, Slack y cualquier fuente de información estructurada o no estructurada.
- LlamaParse es el servicio de parseo de documentos complejos (PDFs con tablas, imágenes y fórmulas) con 1.000 páginas gratuitas al día.
- LlamaCloud ofrece RAG-as-a-service gestionado: pipeline de ingestión, indexación y query engine sin gestionar infraestructura propia.
- Compatible con cualquier LLM: OpenAI, Anthropic Claude, Google Gemini, modelos locales vía Ollama y cualquier proveedor con interfaz OpenAI-compatible.
¿Qué es LlamaIndex y qué problema resuelve en los agentes IA?
LlamaIndex nació en octubre de 2022 de la mano de Jerry Liu como un proyecto personal llamado GPT Index. La motivación era sencilla pero urgente: los LLMs son poderosos pero tienen dos limitaciones estructurales. Primera, su conocimiento se congela en la fecha de corte del entrenamiento. Segunda, su ventana de contexto — aunque ha crecido enormemente — no puede contener gigabytes de documentación propia. LlamaIndex fue diseñado desde el principio para resolver exactamente este problema: conectar de forma eficiente cualquier fuente de datos con cualquier modelo de lenguaje.
El repositorio principal se mantiene en github.com/run-llama/llama_index y la documentación oficial en docs.llamaindex.ai . Disponible en Python y TypeScript, el proyecto ha evolucionado desde una biblioteca de indexación simple hasta un framework completo que incluye conectores de datos, estrategias de indexación avanzadas, query engines, agentes, parseo de documentos y una plataforma gestionada en la nube.
El patrón que LlamaIndex populariza se llama RAG: en lugar de incluir toda la documentación en el prompt del modelo, el sistema recupera los fragmentos más relevantes en tiempo real y se los pasa al modelo junto con la pregunta del usuario. El resultado es que el modelo puede responder sobre contenido que nunca vio durante el entrenamiento y que el desarrollador puede actualizar la base de conocimiento sin reentrenar el modelo. Para comprender mejor los modelos LLM que se pueden usar con LlamaIndex, la guía de modelos ofrece el contexto completo sobre capacidades y precios.
A diferencia de otros frameworks como LangChain que abordan la orquestación de agentes de forma general, LlamaIndex es deliberadamente data-first: todas sus abstracciones (conectores, índices, query engines, retrievers) están diseñadas para optimizar la precisión de la recuperación de información. Esta especialización lo hace la opción natural para aplicaciones de base de conocimiento, asistentes de documentación, motores de búsqueda semántica y cualquier sistema que necesite que el agente trabaje con datos propios actualizados.
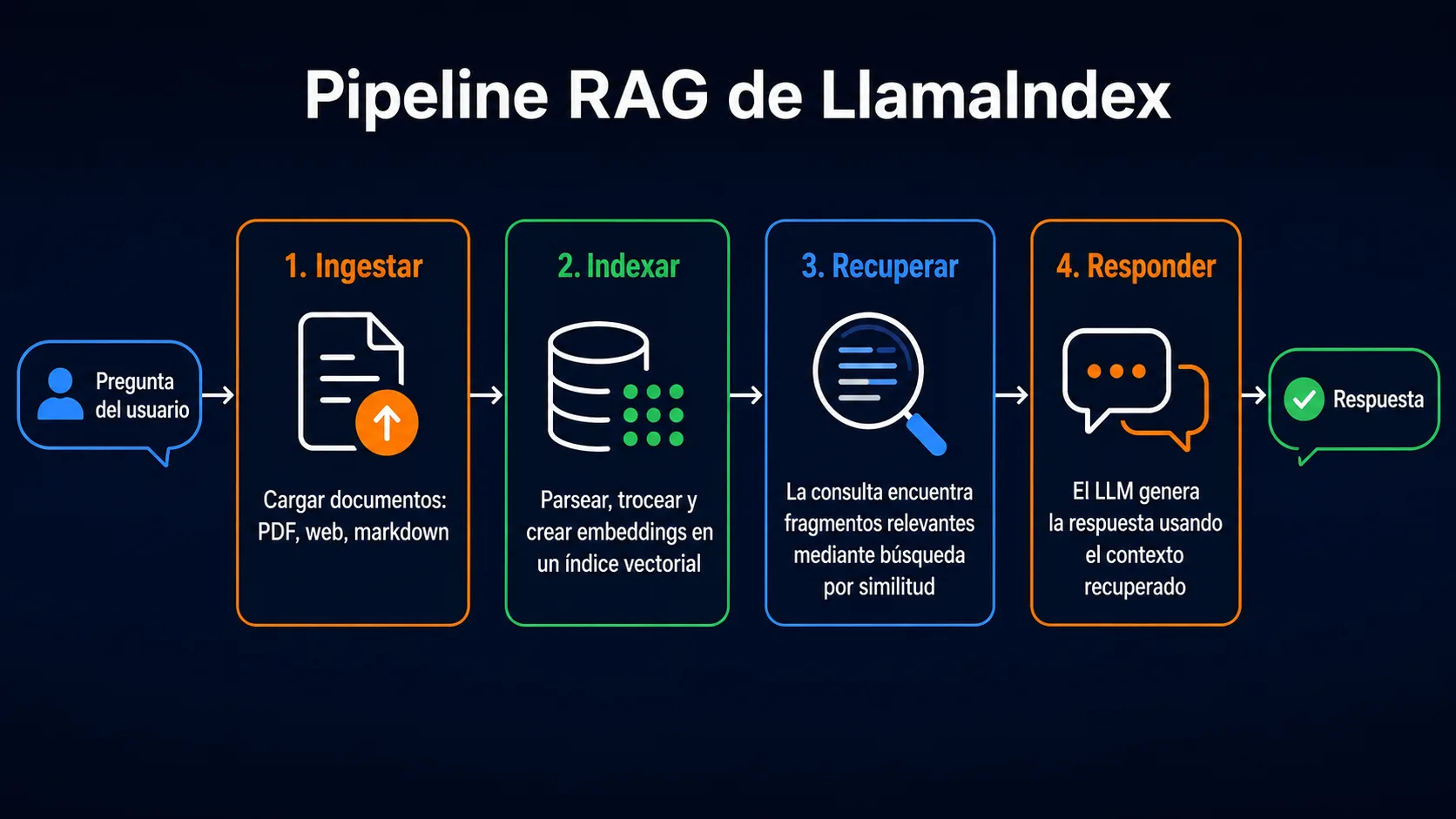
¿Cómo funciona el pipeline RAG en LlamaIndex?
LlamaIndex organiza el flujo de trabajo RAG en cuatro etapas: carga de datos, indexación, recuperación y síntesis de la respuesta. Entender cada una es esencial para construir pipelines precisos y eficientes.
Data Connectors: cargar datos desde cualquier fuente
Los conectores de datos (llamados Readers en LlamaIndex) se encargan de leer
información desde la fuente de origen y convertirla en objetos Document
que el framework puede procesar. LlamaHub, el repositorio comunitario de conectores,
incluye más de 150 integraciones: PDFs, Word, Google Drive, Notion, Confluence,
Slack, GitHub, bases de datos SQL, APIs REST, sitios web, YouTube y muchas más.
Instalar un conector es tan simple como pip install llama-index-readers-file
o el paquete específico del conector.
Índices: cómo LlamaIndex organiza el conocimiento
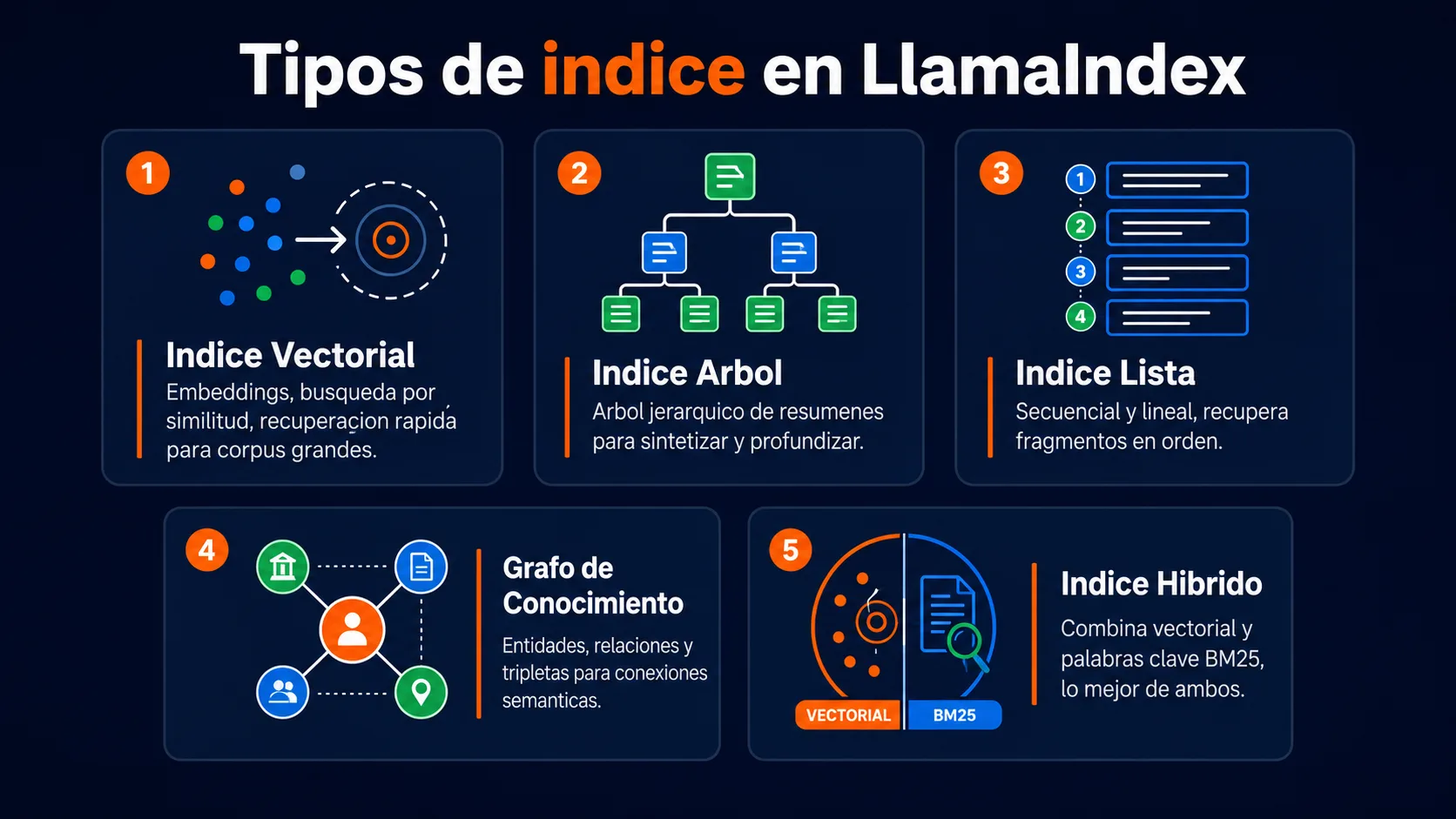
Una vez cargados los documentos, LlamaIndex los indexa para hacer posible la recuperación eficiente. El tipo de índice más usado es el VectorStoreIndex, que convierte los documentos en embeddings numéricos y los almacena en una base de datos vectorial. Pero LlamaIndex ofrece además: SummaryIndex (resúmenes jerárquicos), TreeIndex (árbol de nodos para textos muy largos), KeywordTableIndex (búsqueda por palabras clave) y KnowledgeGraphIndex (grafo de entidades y relaciones). La elección del índice tiene un impacto directo en la precisión de la recuperación.
Query Engines: el motor de respuesta inteligente
El query engine combina el retriever (que busca los nodos relevantes) con el response synthesizer (que genera la respuesta final a partir de los nodos recuperados). LlamaIndex incluye varios query engines preconfigurados: RetrieverQueryEngine (el estándar), SubQuestionQueryEngine (descompone preguntas complejas en subpreguntas), RouterQueryEngine (enruta la pregunta al índice más adecuado) y FLAREQueryEngine (busca de forma iterativa hasta tener suficiente información). Esta variedad permite adaptar la estrategia de recuperación al tipo de pregunta y de datos.
Node Parsers y chunking: dividir bien para recuperar bien
Antes de indexar, los documentos se dividen en nodos (chunks). La estrategia de chunking tiene un impacto enorme en la calidad del RAG. LlamaIndex ofrece: SentenceSplitter (divide por oraciones respetando la semántica), SemanticSplitter (usa embeddings para detectar los cambios de tópico), TokenTextSplitter (divide por tokens con overlap configurable) y MarkdownNodeParser (respeta la estructura de encabezados de documentos Markdown). Un chunking inadecuado es la causa más frecuente de respuestas imprecisas en sistemas RAG.
Retrievers y reranking: precisión más allá de la similitud
La recuperación básica por similitud coseno funciona bien para preguntas directas pero pierde precisión en preguntas complejas o cuando los documentos tienen mucha redundancia. LlamaIndex incluye estrategias avanzadas: BM25Retriever (búsqueda por palabra clave clásica), HybridRetriever (combina búsqueda semántica y keyword), RecursiveRetriever (sigue referencias entre nodos) y soporte para rerankers externos como Cohere Rerank o los modelos de cross-encoder de HuggingFace que reordenan los resultados con mayor precisión.
| Etapa | Qué hace | Componentes disponibles | Impacto en la precisión |
|---|---|---|---|
| Carga (Load) | Lee documentos desde la fuente y los convierte en objetos Document | +150 readers en LlamaHub: PDF, web, SQL, APIs, Drive... | Alto: datos mal cargados producen respuestas incorrectas |
| Chunking (Transform) | Divide documentos en nodos con metadatos | SentenceSplitter, SemanticSplitter, MarkdownNodeParser... | Muy alto: el tamaño y método de chunk determina la recuperación |
| Indexación (Index) | Convierte nodos en representaciones buscables | VectorStoreIndex, SummaryIndex, KnowledgeGraphIndex... | Alto: diferente índice para diferente tipo de pregunta |
| Recuperación (Retrieve) | Busca los nodos más relevantes para la pregunta | VectorRetriever, BM25, HybridRetriever, rerankers... | Muy alto: top-k y estrategia de fusión afectan directamente |
| Síntesis (Synthesize) | Genera la respuesta final combinando nodos recuperados y LLM | CompactAndRefine, TreeSummarize, Accumulate... | Medio: el modelo final determina la coherencia de la respuesta |
¿Cómo instalar LlamaIndex y construir tu primer pipeline RAG?
LlamaIndex usa una arquitectura modular: el paquete base es ligero y solo instalas las integraciones que necesitas.
Instalación
El paquete principal es llama-index. Los modelos de embeddings, bases
de datos vectoriales y lectores de datos se instalan por separado según el proveedor
que uses:
# Paquete base
pip install llama-index
# Con integracion OpenAI (embeddings + LLM)
pip install llama-index llama-index-llms-openai llama-index-embeddings-openai
# Con Anthropic Claude
pip install llama-index llama-index-llms-anthropic
# Con modelos locales vía Ollama
pip install llama-index llama-index-llms-ollama llama-index-embeddings-ollama
# Con Chroma como base de datos vectorial
pip install llama-index llama-index-vector-stores-chromaPipeline RAG mínimo funcional
El siguiente ejemplo carga un directorio de documentos, los indexa en memoria y responde preguntas sobre ellos. Es el punto de partida de cualquier aplicación RAG:
import os
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
# Configuración global (evita pasar el LLM en cada llamada)
Settings.llm = OpenAI(model="gpt-4o-mini", temperature=0.1)
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small")
Settings.chunk_size = 512 # Tamaño de cada nodo en tokens
Settings.chunk_overlap = 50 # Solapamiento entre nodos consecutivos
# 1. Cargar documentos desde un directorio (PDF, TXT, MD, etc.)
documents = SimpleDirectoryReader("./data/").load_data()
print(f"Cargados {len(documents)} documentos")
# 2. Indexar los documentos (crea embeddings y los almacena en memoria)
index = VectorStoreIndex.from_documents(documents)
# 3. Crear el query engine
query_engine = index.as_query_engine(
similarity_top_k=5, # Recupera los 5 nodos más similares
streaming=True, # Respuesta en streaming para mejor UX
)
# 4. Hacer una pregunta
respuesta = query_engine.query(
"¿Cuál es la política de devolución de productos?"
)
print(respuesta)RAG con Chroma como base de datos vectorial persistente
En producción es preferible usar una base de datos vectorial externa para que el índice persista entre reinicios y pueda crecer sin límites de memoria:
import chromadb
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, StorageContext
from llama_index.vector_stores.chroma import ChromaVectorStore
# Inicializar Chroma con persistencia en disco
chroma_client = chromadb.PersistentClient(path="./chroma_db")
chroma_collection = chroma_client.get_or_create_collection("documentos_empresa")
# Crear el vector store de LlamaIndex apuntando a Chroma
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# Primera ejecucion: indexar documentos y persistir en Chroma
documents = SimpleDirectoryReader("./data/").load_data()
index = VectorStoreIndex.from_documents(
documents,
storage_context=storage_context,
)
# Ejecuciones posteriores: cargar desde Chroma sin re-indexar
# index = VectorStoreIndex.from_vector_store(vector_store)
# Query engine con metadata filtering
query_engine = index.as_query_engine(
similarity_top_k=5,
# Filtrar por metadatos del documento (si se definieron al cargar)
# filters=MetadataFilters(filters=[ExactMatchFilter(key="tipo", value="contrato")])
)
respuesta = query_engine.query("Resumen de los contratos vigentes en 2026")
print(respuesta.source_nodes[0].score) # Puntuación de relevancia del primer nodo
Para producción con alta precisión, combina búsqueda semántica (vectorial) con búsqueda
por palabra clave (BM25) y aplica un reranker para ordenar los resultados finales.
LlamaIndex incluye QueryFusionRetriever que combina varios retrievers
con el algoritmo Reciprocal Rank Fusión (RRF) sin necesidad de configuración adicional.
Esto reduce significativamente los falsos negativos en la recuperación (documentos
relevantes que la búsqueda vectorial no encontró).
Agentes en LlamaIndex: ReAct, function calling y Workflows
LlamaIndex no es solo RAG. Su framework de agentes permite construir sistemas que razonan, usan herramientas y ejecutan pipelines complejos de forma autónoma.
ReActAgent: razonar antes de recuperar
El agente ReAct de LlamaIndex combina el patrón Reasoning + Acting con el acceso a herramientas que incluyen query engines sobre índices propios. Esto permite al agente decidir cuándo buscar en tus documentos, cuándo buscar en internet y cuándo responder directamente con lo que ya sabe:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.tools import QueryEngineTool, FunctionTool
from llama_index.core.agent import ReActAgent
from llama_index.llms.anthropic import Anthropic
# Herramienta 1: base de conocimiento propia
documentos = SimpleDirectoryReader("./docs/").load_data()
indice = VectorStoreIndex.from_documents(documentos)
herramienta_docs = QueryEngineTool.from_defaults(
query_engine=indice.as_query_engine(),
name="base_conocimiento",
description=(
"Busca información en la documentación interna de la empresa. "
"Usa esta herramienta para preguntas sobre políticas, productos "
"y procedimientos internos."
),
)
# Herramienta 2: función Python personalizada
def obtener_tipo_cambio(divisa: str) -> str:
"""Devuelve el tipo de cambio actual de la divisa indicada frente al euro."""
# Aquí iría la llamada a una API de tipos de cambio
tipos_ejemplo = {"USD": 1.08, "GBP": 0.86, "JPY": 163.5}
tasa = tipos_ejemplo.get(divisa.upper(), "No disponible")
return f"1 EUR = {tasa} {divisa.upper()}"
herramienta_cambio = FunctionTool.from_defaults(fn=obtener_tipo_cambio)
# Crear el agente con Claude Sonnet
llm = Anthropic(model="claude-sonnet-4-6", temperature=0)
agente = ReActAgent.from_tools(
tools=[herramienta_docs, herramienta_cambio],
llm=llm,
verbose=True, # Muestra el razonamiento interno (Thought/Action/Observación)
max_iterations=10,
)
respuesta = agente.chat(
"¿Cuál es la política de descuento para pedidos internacionales "
"y cuánto sería en dólares un pedido de 500 euros?"
)
print(respuesta)Workflows: pipelines de agentes tipados y asíncronos
Los Workflows de LlamaIndex son la abstracción más avanzada para pipelines multi-paso. Funcionan como un grafo de eventos donde cada paso es una función Python asíncrona tipada con Pydantic. Son equivalentes a LangGraph pero con una sintaxis más simple basada en decoradores:
from llama_index.core.workflow import (
Workflow, Event, StartEvent, StopEvent, step
)
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from pydantic import BaseModel
# Definir los eventos del workflow (tipado con Pydantic)
class ResultadoBusqueda(Event):
nodos: list[str]
pregunta: str
class RespuestaFinal(BaseModel):
respuesta: str
fuentes: list[str]
# Definir el workflow
class WorkflowRAG(Workflow):
@step
async def recuperar(self, ev: StartEvent) -> ResultadoBusqueda:
"""Paso 1: recuperar nodos relevantes del índice."""
indice = VectorStoreIndex.from_documents(
SimpleDirectoryReader("./docs/").load_data()
)
retriever = indice.as_retriever(similarity_top_k=5)
nodos = await retriever.aretrieve(ev.pregunta)
textos = [nodo.get_content() for nodo in nodos]
return ResultadoBusqueda(nodos=textos, pregunta=ev.pregunta)
@step
async def sintetizar(self, ev: ResultadoBusqueda) -> StopEvent:
"""Paso 2: generar respuesta a partir de los nodos recuperados."""
contexto = "\n\n---\n\n".join(ev.nodos)
# Aqui iria la llamada al LLM para sintetizar la respuesta
respuesta = f"Respuesta basada en {len(ev.nodos)} fragmentos: [respuesta generada]" # noqa
return StopEvent(result=respuesta)
# Ejecutar el workflow
async def main():
workflow = WorkflowRAG(timeout=60)
resultado = await workflow.run(pregunta="¿Cómo solicitar vacaciones?")
print(resultado)
import asyncio
asyncio.run(main())| Mecanismo | Descripción | Mejor para | Complejidad |
|---|---|---|---|
| QueryEngine | Recupera nodos y genera una respuesta en un solo paso | Preguntas directas sobre documentos propios | Baja |
| ReActAgent | Bucle razona-actúa con herramientas (incluido query engines) | Tareas que requieren múltiples herramientas y razonamiento | Media |
| FunctionCallingAgent | Usa tool calling nativo del modelo para mayor fiabilidad | Agentes de producción con modelos OpenAI, Anthropic o Gemini | Media |
| Workflow | Grafo asíncrono de pasos tipados con eventos Pydantic | Pipelines complejos con bifurcaciones, paralelismo y estado | Alta |
| SubQuestionQueryEngine | Descompone preguntas complejas en subpreguntas sobre distintos índices | Análisis comparativo entre múltiples fuentes de datos | Media-baja |
¿Qué incluye el ecosistema de LlamaIndex en mayo de 2026?
LlamaIndex ha crecido más allá del framework core para incluir herramientas de parseo, una plataforma gestionada y un repositorio comunitario de conectores.
LlamaParse: parseo de documentos complejos con alta fidelidad
Los PDFs con tablas, fórmulas, imágenes o formato de varias columnas son el
punto débil del parseo genérico. LlamaParse es el servicio especializado de
LlamaIndex para este problema: extrae texto, tablas e imágenes de documentos
complejos preservando la estructura original con mayor precisión que las
alternativas open source. Disponible como API con 1.000 páginas gratuitas
al día. Se integra directamente en el pipeline de ingestión con
LlamaParse() como reader. Documentación en
docs.llamaindex.ai .
LlamaCloud: RAG-as-a-service gestionado
LlamaCloud es la plataforma gestionada que convierte el pipeline RAG en un servicio sin necesidad de gestionar vectores, índices ni infraestructura. El desarrollador conecta sus fuentes de datos a través de la interfaz web o la API, y LlamaCloud se encarga de la ingestión, el chunking, los embeddings, el almacenamiento vectorial y la actualización automática cuando los documentos cambian. Los query engines de LlamaCloud son accesibles vía API REST o vía el SDK de Python con la misma interfaz que el framework local.
LlamaHub: repositorio comunitario de conectores e integraciones
LlamaHub es el equivalente de npm o PyPI para el ecosistema LlamaIndex: un
repositorio comunitario con más de 150 conectores de datos, modelos de
embeddings, bases de datos vectoriales y utilidades compatibles con el
framework. Cada paquete se instala de forma independiente
(pip install llama-index-readers-notion,
pip install llama-index-vector-stores-pinecone, etc.) para no
cargar dependencias innecesarias. El catálogo completo está en
llamahub.ai .
| Categoría | Integraciones disponibles (selección) |
|---|---|
| Lectores de documentos | PDF, Word, PowerPoint, Excel, Markdown, HTML, ePub, LaTeX, Notion, Confluence |
| Bases de datos vectoriales | Chroma, Pinecone, Weaviate, Qdrant, Milvus, Faiss, Redis, PgVector, MongoDB Atlas |
| Fuentes de datos en la nube | Google Drive, OneDrive, Dropbox, S3, Azure Blob, GitHub, GitLab, Slack |
| Bases de datos SQL y NoSQL | PostgreSQL, MySQL, SQLite, MongoDB, DynamoDB, BigQuery, Snowflake |
| Modelos de embeddings | OpenAI, Anthropic, Cohere, HuggingFace, Ollama, FastEmbed, VoyageAI |
| Proveedores LLM | OpenAI, Anthropic, Google, Mistral, Groq, Together AI, Ollama, Replicate |
¿Cuánto cuesta usar LlamaIndex? Precios del framework y LlamaCloud
El framework core es gratuito. Los costes reales provienen del proveedor LLM que elijas y, si lo usas, de LlamaCloud.
| Producto | Plan gratuito | Plan de pago | Qué incluye el de pago |
|---|---|---|---|
| LlamaIndex (framework) | Gratuito, MIT | Gratuito siempre | El framework open source no tiene planes de pago — es MIT completo |
| LlamaParse | 1.000 páginas / día | Desde 3 USD / 1.000 páginas extra | Volumen ilimitado, parseo prioritario, soporte para imágenes complejas |
| LlamaCloud Starter | No disponible | Desde 97 USD / mes | Pipeline de ingestión gestionado, 1M tokens de embedding / mes, 1 pipeline |
| LlamaCloud Pro | No disponible | Desde 497 USD / mes | Pipelines ilimitados, actualización automática de índices, SSO, SLA garantizado |
| LlamaCloud Enterprise | No disponible | Precio bajo consulta | Despliegue on-premise o VPC privada, soporte dedicado, integraciones personalizadas |
El coste dominante en la mayoría de sistemas RAG no es el framework sino el proveedor LLM. Para estimar el coste real debes considerar: el modelo de embeddings (llamada al indexar cada documento y al procesar cada consulta), el LLM de síntesis (el modelo que genera la respuesta final) y la base de datos vectorial (si usas Pinecone, Weaviate o similar con coste mensual). Para desarrollo y volúmenes bajos, usar Ollama con modelos locales gratuitos es la opción más económica. Para producción con requisitos de calidad alta, los costes de un pipeline RAG bien optimizado con LlamaIndex son típicamente inferiores a los de llamadas directas al LLM sin RAG, porque el contexto inyectado es más conciso.
LlamaIndex vs LangChain vs CrewAI: ¿cuándo elegir cada uno?
Los tres frameworks se solapan en capacidades pero tienen fortalezas distintas. Esta comparativa ayuda a tomar la decisión correcta según el caso de uso.
| Criterio | LlamaIndex | LangChain | CrewAI |
|---|---|---|---|
| Paradigma principal | Data-first (RAG) — indexación y recuperación precisa | Chain-first — orquestación y composición | Role-first — equipos de agentes especializados |
| RAG avanzado | Especializado — la fortaleza principal del framework | Bueno con muchos retrievers | Básico (RagTool) |
| Conectores de datos | +150 en LlamaHub con instalación independiente | +600 integraciones (incluyendo no-RAG) | ~100 herramientas |
| Parseo de documentos complejos | LlamaParse — servicio especializado | Parseo básico o vía LlamaParse | Vía herramientas externas |
| Plataforma gestionada | LlamaCloud — RAG-as-a-service | LangSmith (observabilidad), LangGraph Cloud | CrewAI+ (despliegue y observabilidad) |
| Multi-agente | Vía Workflows o AgentRunner | LangGraph con sub-grafos | Nativo y declarativo (Crew/Pipeline) |
| Curva de aprendizaje | Media — foco en conceptos de indexación | Media-alta — muchas abstracciones | Baja — API intuitiva |
| TypeScript / JS | SDK oficial con paridad de funciones | LangChain.js (completo) | No oficial |
| GitHub stars (mayo 2026) | ~40k | ~92k | ~25k |
| Mejor para | RAG sobre documentos propios, bases de conocimiento, motores de búsqueda semántica | Agentes con muchas integraciones, flujos complejos con LangGraph | Equipos de agentes con roles claros, prototipos rápidos |
Regla de decisión rápida
Elige LlamaIndex cuando el núcleo de tu aplicación sea hacer que un LLM responda con información de tus documentos propios: manuales, contratos, base de conocimiento de soporte, documentación técnica o cualquier corpus de texto propio que el modelo no conoce. Elige LangChain cuando necesites el mayor ecosistema de integraciones posible, cuando el flujo del agente requiera estado persistente y bifurcaciones complejas (LangGraph) o cuando la observabilidad de producción sea una prioridad con LangSmith. Elige CrewAI cuando el caso de uso se describe como un equipo de especialistas con roles bien definidos y quieres la curva de aprendizaje más baja posible. Los tres son compatibles entre sí: es habitual usar LlamaIndex como retriever dentro de un agente LangChain o de un crew de CrewAI. Para una visión global de todos los modelos LLM compatibles, la guía de modelos ofrece el mapa completo.
Preguntas frecuentes sobre LlamaIndex
LlamaIndex es un framework de datos de código abierto (licencia MIT) para construir aplicaciones RAG (Retrieval Augmented Generation) y agentes IA que acceden a fuentes de datos externas. Permite conectar modelos LLM con bases de datos, PDFs, APIs, sitios web y cualquier fuente de información a través de más de 150 conectores. Fundado en 2022 por Jerry Liu, es el framework más especializado en indexación y recuperación de información dentro del ecosistema de agentes IA.
LlamaIndex está especializado en datos: conectar fuentes de información con LLMs, indexarlas de forma eficiente y recuperarlas con alta precisión. LangChain es un framework de orquestación de propósito general con mayor enfoque en agents y chains. Ambos soportan RAG, pero LlamaIndex ofrece más opciones de indexación (vectorial, árbol, lista, grafo de conocimiento, híbrida) y sus query engines están optimizados para la recuperación precisa. LangChain tiene mayor ecosistema de integraciones generales y mejores herramientas de observabilidad con LangSmith. En proyectos de producción es habitual ver los dos usados juntos.
El framework LlamaIndex es completamente gratuito bajo licencia MIT. Puedes usarlo en producción sin ningún coste de licencia. LlamaCloud, la plataforma gestionada de RAG-as-a-service, tiene planes de pago que empiezan en 97 USD al mes. LlamaParse, el servicio de parseo de documentos complejos, tiene una capa gratuita de 1.000 páginas al día y planes de pago para volúmenes mayores. El coste real de un sistema RAG proviene principalmente del proveedor LLM que elijas y de la base de datos vectorial si usas un servicio externo.
RAG (Retrieval Augmented Generation) es el patrón por el que un LLM responde preguntas buscando información relevante en una base de datos antes de generar la respuesta, en lugar de responder solo con lo que aprendió en el entrenamiento. LlamaIndex es el framework más especializado en RAG porque proporciona: más de 150 conectores de datos, múltiples estrategias de indexación, query engines con fusión de resultados, reranking semántico, evaluadores de relevancia y pipelines de ingestión configurables. El resultado es mayor precisión en las respuestas con menor porcentaje de alucinaciones respecto a enfoques sin RAG.
LlamaParse es el servicio de parseo de documentos complejos de LlamaIndex. Está diseñado para extraer texto, tablas e imágenes de PDFs con alta fidelidad, preservando la estructura original del documento — algo que el parseo genérico con PyPDF2 o pdfplumber no consigue con informes financieros, documentación técnica con tablas anidadas o formularios de varias columnas. Tiene una capa gratuita de 1.000 páginas al día y se integra directamente en el pipeline de ingestión. Conviene usarlo cuando el parseo básico produce chunks con texto desordenado o cuando los documentos tienen tablas que son críticas para las respuestas del sistema RAG.
LlamaIndex soporta todos los proveedores LLM principales a través de paquetes
de integración independientes: OpenAI (GPT-5, o1), Anthropic (Claude Opus 4,
Sonnet 4.6, Haiku 4.5), Google (Gemini), Mistral, Cohere, Groq, Together AI
y modelos locales a través de Ollama, HuggingFace y llama.cpp. La integración
se hace a través de la clase Settings.llm que proporciona una
interfaz común independientemente del proveedor elegido. Cambiar de OpenAI a
Anthropic es tan simple como cambiar una línea de configuración.