- Por qué Python domina el desarrollo de agentes IA y qué lo diferencia de otros enfoques.
- La arquitectura del bucle percibir-razonar-actuar y cómo se traduce en código estructurado.
- Los 5 pasos conceptuales para construir un agente: desde elegir framework hasta implementar memoria.
- Comparativa de los cuatro frameworks Python más usados: LangChain, CrewAI, PydanticAI y LlamaIndex.
- Buenas prácticas de producción: manejo de errores, gestión de tokens, seguridad y observabilidad.
¿Por qué Python es la mejor opción para crear agentes IA?
De todos los lenguajes disponibles, Python se ha consolidado como el estándar de facto para el desarrollo de agentes de inteligencia artificial por tres razones principales. Primera, concentra el ecosistema de frameworks más rico del sector: LangChain, CrewAI, PydanticAI, LlamaIndex, AutoGen y el Claude Agent SDK están escritos en Python y ofrecen integraciones nativas con docenas de proveedores LLM. Segunda, la sintaxis expresiva de Python hace que la lógica del agente sea legible y fácil de depurar, algo crítico cuando hay que entender por que el agente tomo una decisión erronea. Tercera, la mayoría de los SDKs de proveedores como Anthropic, OpenAI o Google AI tienen Python como lengua nativa.
En comparación con JavaScript (el segundo ecosistema más maduro para agentes), Python ofrece mejor soporte para computación numerica, embeddings y bases de datos vectoriales. Frente a Go o Rust, gana en velocidad de prototipado y en la cantidad de ejemplos y recursos disponibles. Si ya sabes un poco de Python, tienes el acceso más directo al estado del arte en agentes IA.
Esta guía no está ligada a una versión de framework ni a una libreria específica. Los conceptos arquitectonicos que aprenderás aquí son validos independientemente de que el ecosistema evolucione. La API de LangChain cambia. La arquitectura percibir-razonar-actuar no cambia.
Que necesitas antes de crear tu agente con Python
Los requisitos son intencionalmente bajos. No necesitas ser un experto en IA ni en machine learning. Lo que si necesitas tener resuelto antes de escribir la primera línea de código del agente:
Python 3.10 o superior instalado
La mayoría de frameworks de agentes requieren al menos Python 3.10. La versión estable
más usada en producción actualmente (mayo 2026) es la 3.12. Verifica tu versión con
python --version en la terminal y actualiza si es necesario desde
python.org .
pip y un entorno virtual
pip viene incluido con Python. Antes de instalar cualquier framework, crea un entorno
virtual con python -m venv .venv para aislar las dependencias del proyecto.
Esto evita conflictos entre proyectos y facilita reproducir el entorno en otros equipos
o en producción.
Clave de API de un proveedor LLM (o Ollama en local)
Si usas un modelo en la nube necesitas una clave de API de Anthropic (Claude), OpenAI (GPT) o Google (Gemini). Guardala siempre en una variable de entorno, nunca en el código. Si prefieres empezar sin coste, instala Ollama y descarga un modelo como Llama 3 o Mistral para ejecutarlo en local.
Conocimiento básico de Python
No necesitas ser un experto. Con saber definir funciones, importar módulos, manejar diccionarios y listas, y entender lo básico de clases orientadas a objetos tienes suficiente para seguir este tutorial. Los frameworks de agentes hacen el trabajo pesado: tu defines el objetivo y las herramientas, el framework gestiona el bucle.
Un caso de uso concreto definido
Este es el requisito más infravalorado. Antes de escribir código, define con precisión que tarea va a resolver tu agente, que información recibe como entrada y como se ve un resultado satisfactorio. Un agente con objetivo vago es el origen de la mayoría de los problemas de razonamiento y alucinaciones.
Como funciona la arquitectura de un agente IA
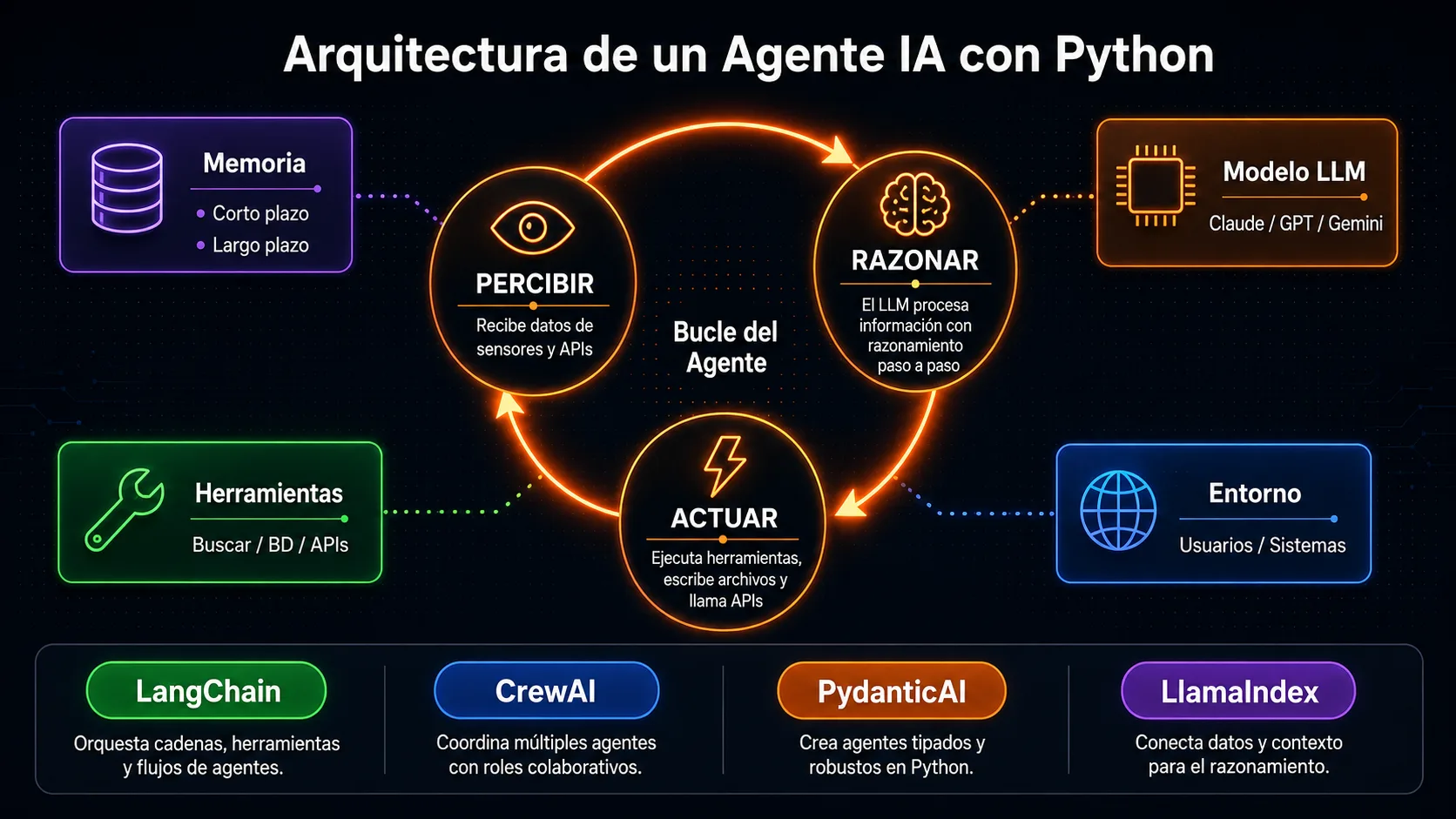
Todos los agentes IA en Python, independientemente del framework, implementan variaciones del mismo bucle fundamental: percibir, razonar y actuar. Entender este bucle es lo que te permite depurar cualquier agente, con cualquier libreria.
El bucle percibir-razonar-actuar
Un agente no es un programa que ejecuta pasos predefinidos en orden fijo. Es un sistema que observa su entorno, decide que hacer basandose en esa observación y ejecuta una acción que modifica el entorno. Después vuelve a observar el resultado de esa acción y repite el ciclo hasta que considera que el objetivo está completo. Este es el bucle de razonamiento.
Percibir significa recibir información: el mensaje del usuario, el resultado de una herramienta ejecutada en el paso anterior, el contenido de un documento, el estado de una base de datos. Todo lo que el agente puede "ver" en ese momento.
Razonar es la parte que ejecuta el LLM. Con toda la información disponible en el contexto (el historial de mensajes, las herramientas disponibles, el objetivo definido en el prompt del sistema), el modelo decide que hacer a continuación: responder al usuario, llamar a una herramienta externa, pedir más información o declarar la tarea completada.
Actuar es ejecutar la decisión: hacer una llamada a una API, buscar en una base de datos, ejecutar un fragmento de código, escribir un archivo o enviar un mensaje. El resultado de esa acción se devuelve al bucle como nueva información de entrada para el siguiente ciclo de razonamiento.
Los componentes de un agente en Python
Traduciendo el bucle percibir-razonar-actuar a código Python, un agente bien estructurado tiene cinco componentes separados con responsabilidades claras:
Estructura conceptual del código
Independientemente del framework que uses, la estructura conceptual de un agente Python sigue este patrón. No es código ejecutable con imports reales — es la anatomia que encontrarás traducida a la sintaxis de cada framework:
# 1. Definir las herramientas disponibles para el agente
def buscar_en_web(consulta: str) -> str:
"""Busca informacion actualizada en internet sobre una consulta."""
# implementacion: llamada a API de busqueda
...
def consultar_base_de_datos(tabla: str, filtros: dict) -> list:
"""Consulta registros de la base de datos interna."""
# implementacion: query SQL
...
# 2. Definir el prompt del sistema (objetivo y restricciones)
SYSTEM_PROMPT = """
Eres un asistente especializado en [dominio].
Objetivo: [tarea concreta].
Restricciones: [limites de comportamiento].
Cuando no tengas informacion suficiente, usa las herramientas antes de responder.
"""
# 3. Configurar el LLM
llm = ProveedorLLM(modelo="modelo-elegido", temperatura=0)
# 4. Crear el agente con sus herramientas
agente = Framework.crear_agente(
llm=llm,
herramientas=[buscar_en_web, consultar_base_de_datos],
prompt_sistema=SYSTEM_PROMPT,
memoria=MemoriaPersistente(backend="sqlite")
)
# 5. Ejecutar el bucle percibir-razonar-actuar
resultado = agente.ejecutar(input_usuario="consulta del usuario")Los 5 pasos para crear tu agente IA con Python
Estos pasos son independientes del framework que elijas. Seguirlos en orden te evitara los errores más frecuentes en el desarrollo de agentes.
¿Qué framework Python elegir para tu agente?
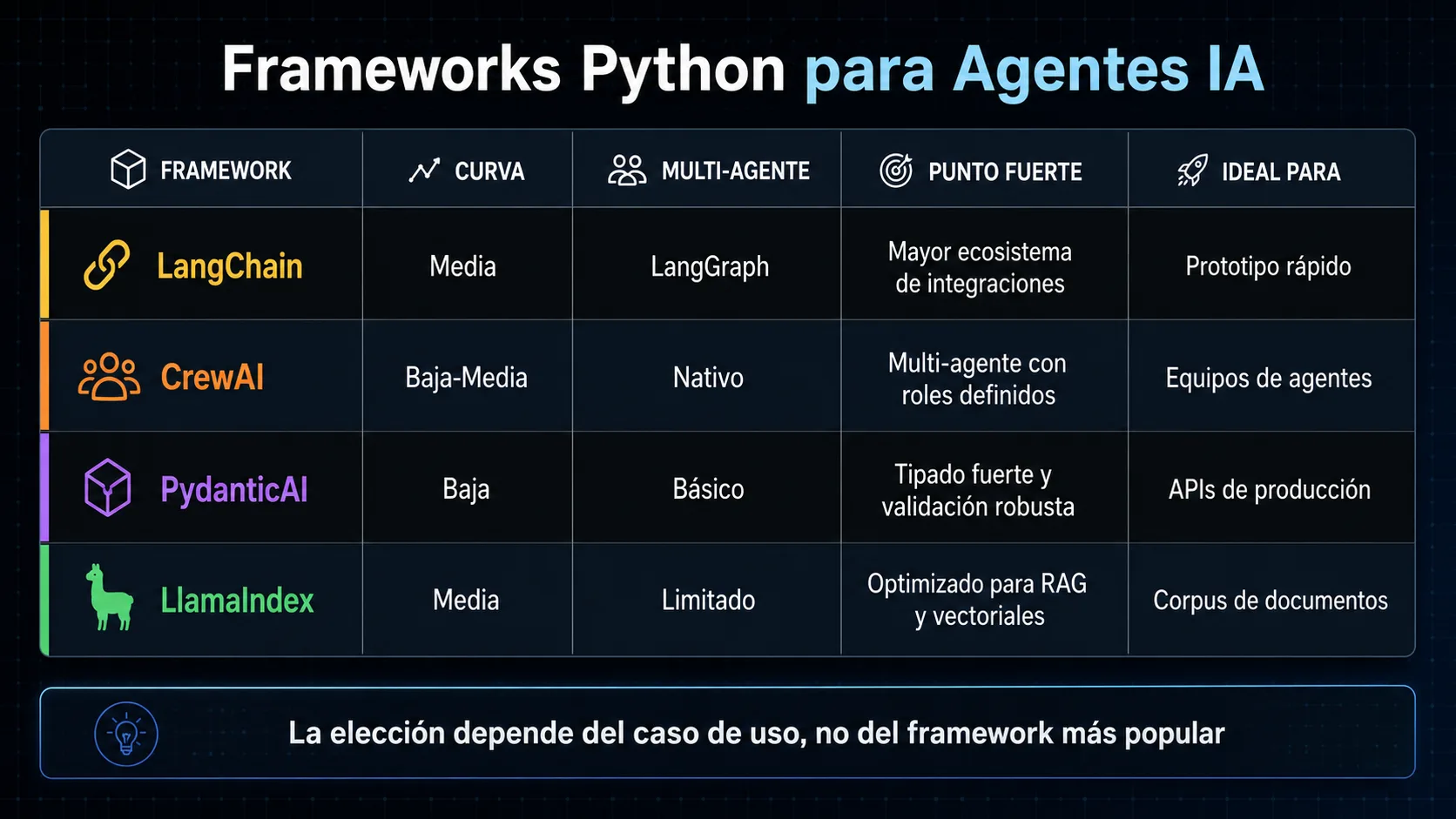
El ecosistema Python de agentes IA evoluciona rápido. Estos cuatro frameworks son los más usados en producción actualmente (mayo 2026). Para una comparativa exhaustiva con más opciones, consulta nuestra guía de frameworks para agentes IA.
| Framework | Punto fuerte | Curva de aprendizaje | Multi-agente | Ideal para |
|---|---|---|---|---|
| LangChain | Ecosistema más amplio, máximas integraciones | Media | Básico (LangGraph) | Prototipado rápido, proyectos con muchas integraciones |
| CrewAI | Multi-agente con roles, muy expresivo | Baja-Media | Nativo y potente | Equipos de agentes especializados, flujos colaborativos |
| PydanticAI | Tipado fuerte, validación robusta, minimalista | Baja (si ya sabes Pydantic) | Básico | Agentes en APIs de producción, cuando la seguridad de tipos importa |
| LlamaIndex | Optimizado para RAG y bases de datos vectoriales | Media | Limitado | Agentes que razonan sobre grandes corpus de documentos |
Recomendación practica: si es tu primer agente en Python, empieza con PydanticAI si ya conoces Pydantic, o con LangChain si no tienes preferencia. Una vez entiendas el patrón de agente con herramientas y memoria, migrar a otro framework es más sencillo de lo que parece porque los conceptos son los mismos. También puedes consultar la guía de agentes sin código para comparar con el enfoque visual si aun no estAs seguro de que Python es tu camino.
Buenas practicas para un agente Python en producción
La diferencia entre un prototipo que funciona en tu maquina y un agente estable en producción se reduce a estas ocho practicas. Incorporarlas desde el principio es mucho más barato que anadirlas después.
Manejo de errores en cada herramienta
Envuelve cada herramienta en un bloque try-except y devuelve un mensaje de error descriptivo en lugar de lanzar una excepción. El agente puede usar ese mensaje de error como información para decidir su siguiente paso. Sin este patrón, un fallo de red en una herramienta detiene el bucle completo.
Gestión activa del consumo de tokens
Define un limite máximo de iteraciones del bucle para evitar bucles infinitos costosos. Implementa una estrategia de compresión del historial (resumir mensajes antiguos) cuando el contexto se acerque al limite del modelo. Monitoriza el coste por sesión desde el primer día para detectar comportamientos anómalos antes de que se conviertan en facturas inesperadas.
Seguridad: nunca confiar en el output del LLM para ejecutar código
Si tu agente puede ejecutar código (via una herramienta), valida y sanea siempre el
código antes de ejecutarlo. Ejecuta en entornos aislados (Docker, sandboxes). Nunca
pases directamente a eval() o exec() la salida de un LLM.
Define listas de herramientas permitidas en lugar de exponer capacidades genericas.
Observabilidad: loguea cada ciclo del bucle
Guarda en un sistema de logs el estado completo de cada iteración: input recibido, decisión del LLM, herramienta invocada, parámetros usados y resultado obtenido. Herramientas como LangSmith (para LangChain) o Langfuse (independiente del framework) facilitan visualizar y depurar el razonamiento del agente sin instrumentar manualmente cada paso.
Timeouts en herramientas y en el bucle completo
Configura timeouts individuales para cada llamada a herramienta externa (APIs, bases de datos, scrapers). Define también un timeout máximo para el bucle completo del agente. Sin timeouts, un servicio externo lento puede bloquear indefinidamente un hilo de ejecución y agotar los recursos del servidor.
Versionado del prompt del sistema
Trata el prompt del sistema como código: guardalo en un archivo de texto en el repositorio, versionalo con Git y documenta los cambios. Un cambio en el prompt puede alterar radicalmente el comportamiento del agente, y necesitas poder hacer rollback si algo sale mal en producción.
Variables de entorno para credenciales
Nunca escribas claves de API directamente en el código. Cargalas siempre desde
variables de entorno con os.environ.get() o una libreria como
python-dotenv. En producción, usa el gestor de secretos de tu
proveedor de nube (AWS Secrets Manager, Azure Key Vault, etc.) en lugar de archivos
.env.
Temperatura del modelo a cero para tareas deterministicas
Para agentes que ejecutan tareas con respuestas correctas e incorrectas (extracción de datos, clasificación, llamadas a herramientas con parámetros precisos), configura la temperatura del LLM a 0 o muy cerca de 0. Esto reduce la variabilidad de las respuestas y hace el comportamiento del agente más predecible y testeable. Reserva temperaturas más altas para agentes de generación creativa.
Preguntas frecuentes sobre agentes IA en Python
python --version en tu terminal y actualiza si es necesario.
Si tienes múltiples proyectos con versiones distintas de Python, usa
pyenv en Linux/Mac o el Python Launcher en Windows para gestionarlas.