
- Ambas herramientas son gratuitas y de código abierto — el coste real es el hardware y la electricidad.
- Ollama (~171K estrellas en GitHub a mayo 2026) se orienta a desarrolladores; LM Studio (~48K) a usuarios no técnicos y a quienes quieren GUI.
- Las dos usan llama.cpp como motor: el rendimiento con el mismo modelo y cuantización es practicamente identico.
- Ollama tiene la API más compatible con OpenAI del mercado local — permite reutilizar código existente apuntando a localhost.
- LM Studio incluye buscador integrado de Hugging Face y chat interactivo sin configuración adicional.
¿Por qué ejecutar modelos LLM en local?
Ejecutar modelos de lenguaje en tu propio hardware tiene tres ventajas que ninguna API en la nube puede igualar: privacidad total de los datos, coste marginal cero por consulta y disponibilidad sin dependencia de terceros. Si desarrollas agentes para sectores con requisitos legales estrictos sobre donde residen los datos — salud, finanzas, legal — o simplemente quieres experimentar sin que cada prueba cueste tokens, la IA local es la respuesta. Dentro del silo de comparativas de herramientas para agentes, Ollama y LM Studio son las dos opciones más maduras para este escenario en 2026.
Ollama es una herramienta de línea de comandos que actua como gestor y servidor de modelos: instala modelos con un comando, los expone via una API REST compatible con OpenAI y permite scripting completo. LM Studio es una aplicación de escritorio con interfaz gráfica que integra descarga de modelos desde Hugging Face, un chat interactivo y un servidor local — todo sin tocar la terminal. La elección entre las dos depende menos de la capacidad técnica del hardware y más del perfil del usuario y el flujo de trabajo.
Antes de entrar en la comparativa técnica, un dato relevante: la cifra de estrellas en GitHub refleja bien la diferencia de comunidades. Ollama supera actualmente las 171.000 estrellas en su repositorio oficial (github.com/ollama/ollama ), con un ecosistema de integraciones de terceros muy activo. LM Studio tiene alrededor de 48.000 estrellas (github.com/lmstudio-ai ) y una comunidad centrada en usuarios no técnicos y en flujos de trabajo con GUI. Ninguna cifra indica superioridad técnica — solo diferencia de audiencia. Datos verificados en mayo de 2026.
Si buscas una visión más amplia del ecosistema de modelos disponibles para ejecutar localmente, la guía de modelos LLM disponibles en 2026 cubre tanto modelos propietarios como abiertos. Y si te interesa el contexto de frameworks para construir agentes sobre modelos locales, la sección de frameworks para agentes IA es el punto de partida adecuado.
Tabla comparativa principal
| Característica | Ollama | LM Studio |
|---|---|---|
| Tipo de interfaz | Línea de comandos (CLI) | Aplicación de escritorio con GUI |
| Sistemas operativos | macOS, Linux, Windows | macOS, Windows, Linux (beta) |
| Formato de modelos | GGUF (llama.cpp) + Modelfile propio | GGUF (llama.cpp) |
| Repositorio de modelos | ollama.com/library (curado) + Hugging Face | Hugging Face (buscador integrado) |
| API compatible con OpenAI | Si — localhost:11434/v1 | Si — modo "Local Server" |
| Aceleración GPU | NVIDIA CUDA, AMD ROCm, Apple Metal | NVIDIA CUDA, AMD, Apple Metal |
| Soporte de cuantización | Q4_K_M, Q5_K_M, Q8_0, F16 y más | Q4_K_M, Q5_K_M, Q8_0, F16 y más |
| GPU offloading parcial | Si | Si |
| Chat integrado | No (requiere cliente externo) | Si — incluido en la app |
| Tamaño de comunidad | ~171K estrellas GitHub (mayo 2026) | ~48K estrellas GitHub (mayo 2026) |
| Precio | Gratuito — código abierto (Apache 2.0) | Gratuito para uso personal |
| Instalación | Un comando en terminal | Instalador gráfico (.dmg / .exe) |
| Actualizaciones de modelos | ollama pull <modelo> |
Boton en la interfaz |
| Ejecución en segundo plano | Si — daemon del sistema | Requiere la app abierta |
| Multimodal (visión) | Si (LLaVA, BakLLaVA) | Si (modelos compatibles) |
| Mejor para | Desarrolladores, automatización, agentes | Usuarios no técnicos, exploración, chat local |
¿Qué diferencia la experiencia de uso entre Ollama y LM Studio?
Ollama: terminal-first, diseñado para automatizar
Instalar Ollama en macOS o Linux es ejecutar un comando. En Windows, un instalador de 50 MB.
A partir de ahí, todo ocurre en la terminal: ollama pull llama3.2 descarga el modelo,
ollama run llama3.2 abre un chat en la propia terminal, y ollama serve
levanta el servidor REST. El daemon de Ollama arranca con el sistema operativo y permanece
en segundo plano — los modelos están disponibles aunque no haya ninguna ventana abierta.
Esta arquitectura es la que hace a Ollama natural para integraciones. Un script de Python puede llamar a la API local de Ollama igual que llamaria a la API de OpenAI, cambiando solo la URL base. Un agente construido con LangChain, LlamaIndex o cualquier framework con soporte de OpenAI puede apuntar a Ollama sin modificar la lógica del agente. Esto es especialmente valioso en entornos donde los datos no pueden salir del equipo pero se quiere usar el mismo código que en producción con modelos en la nube.
La ausencia de GUI propia de Ollama es una decisión de diseño, no un olvido. Existen proyectos de terceros como Open WebUI que añaden una interfaz web completa a Ollama (incluyendo historial de conversaciones, gestión de modelos y soporte multiusuario), pero requieren una instalación adicional con Docker o Python. Para el caso de uso de agente de fondo sirviendo peticiones, la GUI es innecesaria.
LM Studio: GUI-first, diseñado para explorar
LM Studio se presenta como una "IDE para modelos locales". La aplicación de escritorio integra tres funcionalidades en una sola ventana: un buscador de modelos conectado a Hugging Face que permite filtrar por tamaño, cuantización y arquitectura; un chat interactivo con historial de conversaciones; y un servidor local que expone una API compatible con OpenAI.
El flujo típico en LM Studio es: abrir la app, buscar un modelo, descargarlo con un clic, seleccionarlo y empezar a chatear. No hay terminal, no hay comandos, no hay configuración de rutas. Para alguien que quiere explorar capacidades de modelos sin comprometerse con una infraestructura, esta experiencia es considerablemente más accesible. Los ajustes de parámetros (temperatura, top_p, número de tokens de contexto) se hacen desde un panel lateral con sliders.
La limitación principal de LM Studio es que la aplicación debe estar abierta para que el servidor local funcione. No existe un modo daemon que arranque automáticamente con el sistema. Para flujos de trabajo interactivos esto no es un problema, pero para un agente que necesita el modelo disponible en segundo plano las 24 horas, Ollama es más adecuado. El modo "Local Server" de LM Studio es funcional para desarrollo pero menos adecuado para producción local sostenida.
Rendimiento, cuantización y compatibilidad de modelos
El motor compartido: llama.cpp
Tanto Ollama como LM Studio usan llama.cpp como motor de inferencia subyacente. Esto significa que, con el mismo modelo y el mismo nivel de cuantización, el rendimiento en tokens por segundo es practicamente identico en las dos herramientas. Las diferencias de velocidad que a veces se miden en comparaciones no se deben a la herramienta sino a diferencias en la cuantización elegida o en la configuración de GPU offloading.
Esta equivalencia es importante para tomar decisiones informadas: si el rendimiento fuera el criterio único, la comparativa seria un empate. La elección real entre Ollama y LM Studio se basa en flujo de trabajo, integración y experiencia de usuario — no en velocidad de inferencia.
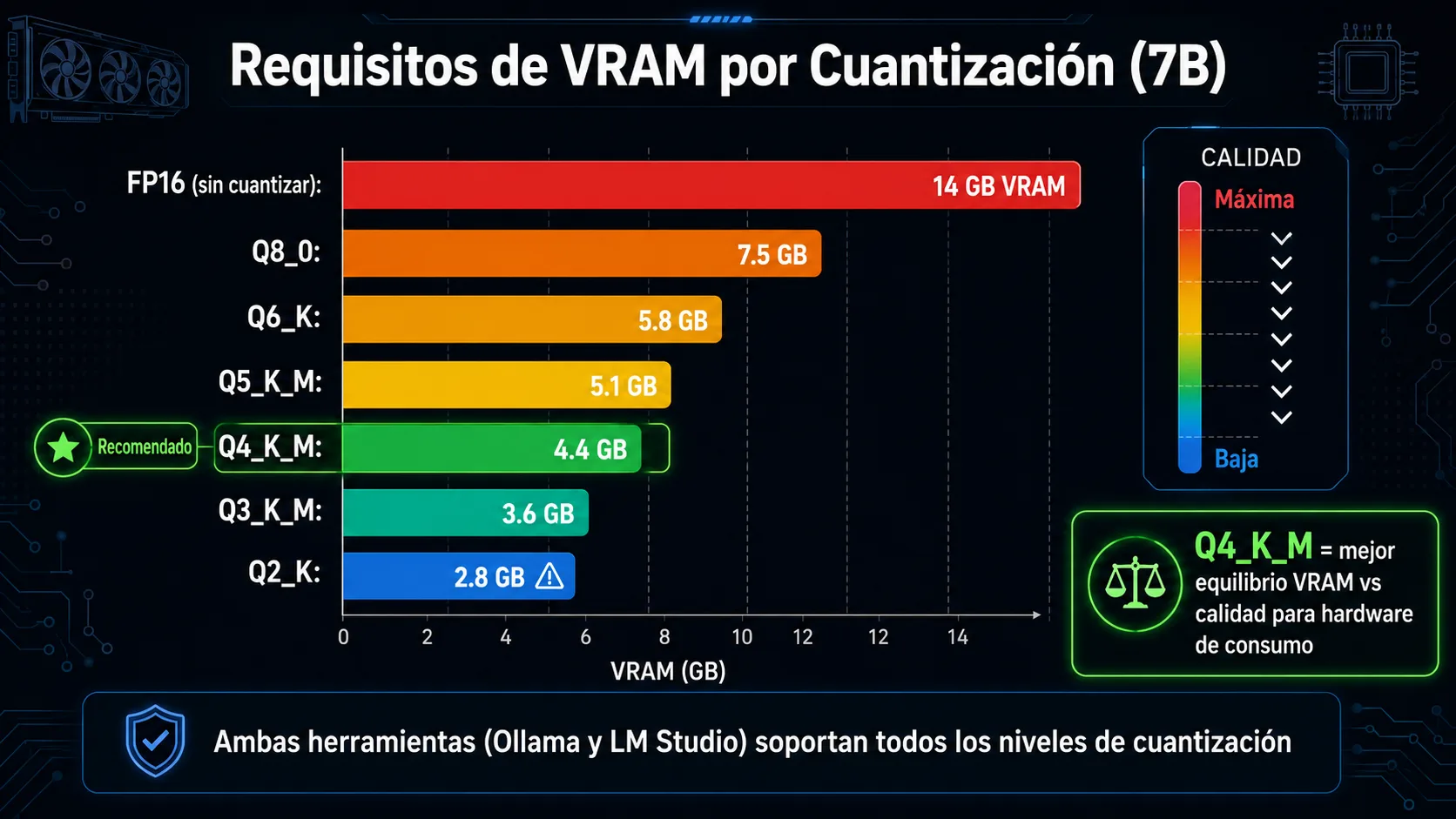
Cuantización GGUF: que nivel elegir
El formato GGUF de llama.cpp permite cuantizar modelos a distintos niveles de precisión, reduciendo el uso de VRAM a cambio de cierta pérdida de calidad. Ambas herramientas soportan todos los niveles de cuantización disponibles. La elección del nivel correcto depende del hardware disponible:
| Cuantización | VRAM aprox. (7B) | Calidad relativa | Recomendado para |
|---|---|---|---|
| Q4_K_M | ~4,5 GB | Buena | GPU 6-8 GB — equilibrio optimo |
| Q5_K_M | ~5,5 GB | Muy buena | GPU 8-12 GB — más precisión |
| Q8_0 | ~8 GB | Excelente | GPU 12+ GB — casi sin perdida |
| F16 (sin cuantizar) | ~14 GB | Original | GPU 16-24 GB — precisión total |
GPU offloading parcial: el truco para VRAM limitada
Una de las características más útiles que comparten ambas herramientas es el GPU offloading parcial: si el modelo no cabe entero en la VRAM de la GPU, es posible cargar solo una parte de las capas en GPU y el resto en RAM del sistema. El resultado es más lento que la inferencia completa en GPU, pero considerablemente más rápido que inferencia pura en CPU. Esto hace viable usar modelos de 13B o 34B en hardware con 8 o 12 GB de VRAM.
En Ollama, el número de capas en GPU se controla con la variable de entorno OLLAMA_GPU_LAYERS
o en el Modelfile. En LM Studio, hay un slider en la interfaz de configuración del modelo.
La experiencia de LM Studio es más visual para este ajuste — puedes ver en tiempo real cuanta
VRAM se usa antes de iniciar la inferencia.
Modelos disponibles y actualizaciones
Ollama mantiene un repositorio curado en ollama.com/library
con los modelos más populares preconfigurados: Llama 3.2, Gemma 2, Mistral, Phi-3, Qwen 2.5,
DeepSeek, Code Llama y decenas más. Cada modelo tiene un Modelfile preconfigurado con los
parámetros optimos — temperatura, contexto, plantilla de prompt — lo que elimina la necesidad
de configuración manual. La actualización de modelos es un comando: ollama pull llama3.2
descarga la versión más reciente si ya tienes una anterior.
LM Studio conecta directamente con Hugging Face, lo que da acceso a un catalogo mucho más amplio — practicamente cualquier modelo en formato GGUF disponible en el Hub. El buscador integrado permite filtrar por autor, arquitectura, cuantización y tamaño. La contrapartida es que no todos los modelos tienen configuraciones preoptimizadas: a veces hay que ajustar manualmente la plantilla de prompt para que el modelo responda correctamente, especialmente con modelos menos populares.
Cómo se integra cada herramienta con aplicaciones y agentes?
API de Ollama: compatibilidad nativa con OpenAI
Ollama expone su API en http://localhost:11434/v1 siguiendo exactamente
el mismo formato que la API de OpenAI para los endpoints /chat/completions,
/completions, /embeddings y /models. Esto significa
que cualquier libreria o framework que soporte la API de OpenAI — el SDK oficial de Python,
LangChain, LlamaIndex, Haystack, cualquier cliente HTTP — puede apuntar a Ollama cambiando
solo la URL base y el nombre del modelo. Cero cambios en la lógica del agente.
Servidor local de LM Studio
LM Studio incluye un "Local Server" en la pestana de la misma aplicación que activa un servidor REST compatible con OpenAI en el puerto 1234 por defecto. El comportamiento es similar al de Ollama: acepta peticiones en formato de chat completions y las procesa con el modelo que tengas cargado. La diferencia clave es que el servidor solo funciona mientras la aplicación de escritorio este abierta, y el modelo debe estar cargado manualmente antes de recibir peticiones. Para pruebas de desarrollo esto es suficiente; para servicios locales que arrancan automáticamente, Ollama es más robusto.
Ejemplo: usar Ollama con el SDK de OpenAI
La integración de Ollama con el SDK de OpenAI para Python es literal: cambiar la URL base.
Con un modelo como llama3.2 ya descargado en Ollama, el código es identico
al que usarias con la API de Anthropic o OpenAI, salvo la URL base y el nombre del modelo.
Esto permite desarrollar localmente con modelos gratuitos y desplegar en producción con
modelos en la nube sin cambiar la lógica del agente — solo las credenciales y la URL.
Integraciones de ecosistema: Ollama lleva ventaja
El ecosistema de herramientas que soportan Ollama como proveedor de modelos es considerablemente más amplio que el de LM Studio. Continue, Cursor, VS Code con extensiones de IA, Open WebUI, Obsidian con plugins de IA, Home Assistant y decenas de proyectos de código abierto tienen integración nativa con Ollama. LM Studio tiene integraciones similares pero menos exhaustivas y con actualizaciones menos frecuentes por parte de los proyectos de terceros. Si un framework que usas necesita un proveedor de modelos local, probablemente soporte Ollama antes que LM Studio.
Embeddings y modelos especializados
Ollama soporta modelos de embeddings (nomic-embed-text, mxbai-embed-large) a traves del mismo endpoint de API, lo que permite construir pipelines RAG (Retrieval-Augmented Generation) completamente locales: tanto el modelo de chat como el modelo de embeddings se sirven desde Ollama. LM Studio también soporta modelos de embeddings pero la integración está menos documentada. Para agentes que necesitan busqueda semántica sobre documentos locales sin enviar datos a ningún servicio externo, Ollama ofrece una solución más completa.
Cuál elegir según tu situación?
Cuatro escenarios reales con recomendación clara. Si tu caso no encaja exactamente en ninguno, la regla general es: si vas a escribir código, elige Ollama; si no vas a tocar la terminal, elige LM Studio.
Escenario 1: Desarrollador construyendo un agente con modelos locales
Recomendación: Ollama. Si el objetivo es integrar un modelo local en una aplicación Python, TypeScript o cualquier otro lenguaje, Ollama es la elección clara. La compatibilidad nativa con el formato de la API de OpenAI elimina fricción, el daemon en segundo plano garantiza disponibilidad y el ecosistema de integraciones es más maduro. El coste de aprender cuatro comandos de terminal se amortiza rápidamente con la facilidad de integración.
Escenario 2: Explorar capacidades de modelos sin escribir código
Recomendación: LM Studio. Para investigadores, redactores, analistas o cualquier persona que quiera probar modelos de distintas arquitecturas y tamaños sin tocar la terminal, LM Studio es el mejor punto de entrada. El buscador integrado de Hugging Face y el chat interactivo permiten pasar de descarga a conversación en menos de cinco minutos. Los controles de parámetros en la GUI fácilitan entender como cambia el comportamiento del modelo según la temperatura o el contexto.
Escenario 3: Datos sensibles que nunca pueden salir del sistema
Recomendación: Ollama para producción, LM Studio para validación. En entornos con requisitos de privacidad estrictos — historias clinicas, documentos legales confidenciales, código propietario — la IA local es la única opción. Para un servicio que debe estar disponible permanentemente procesando documentos, Ollama como daemon es más fiable. LM Studio es útil en la fase de evaluación para que los usuarios no técnicos comprueben la calidad del modelo antes de la implementación.
Escenario 4: Usar los dos a la vez
Recomendación: Ollama + LM Studio son compatibles. Nada impide tener ambas herramientas instaladas simultaneamente — usan puertos diferentes y no interfieren entre si. Un flujo comun es usar LM Studio para explorar y comparar modelos rápidamente gracias a su GUI, y luego desplegar el modelo elegido en Ollama para la integración con el agente o la aplicación. Las dos herramientas se complementan bien en el mismo flujo de trabajo.
Preguntas frecuentes
Depende del perfil del usuario. Ollama es mejor para desarrolladores que quieren automatización, scripting y una API compatible con OpenAI para integrar modelos locales en sus aplicaciones. LM Studio es mejor para usuarios que prefieren una interfaz gráfica, quieren explorar modelos sin tocar la terminal y necesitan un entorno listo para usar sin configuración adicional. Técnicamente, el rendimiento con el mismo modelo es identico en las dos porque comparten el motor llama.cpp.
Ambas herramientas usan llama.cpp como motor de inferencia y ofrecen soporte para cuantización GGUF, por lo que el consumo de VRAM con el mismo modelo y cuantización es equivalente. La diferencia es que LM Studio tiene una interfaz gráfica que consume algo de RAM adicional (típicamente 200-400 MB de RAM del sistema, no VRAM), mientras que Ollama en modo servidor es más ligero en overhead total. Para hardware con RAM ajustada, Ollama tiene ventaja marginal.
Si. Ambas herramientas soportan el formato GGUF de llama.cpp. Cuálquier modelo disponible en Hugging Face en formato GGUF puede usarse en las dos. Ollama además tiene su repositorio propio en ollama.com/library con modelos preconfigurados y listos para descargar con un comando. LM Studio permite buscar y descargar modelos directamente desde Hugging Face con su buscador integrado, lo que da acceso a un catalogo más amplio aunque menos curado.
Ollama en si es una herramienta de terminal sin interfaz gráfica propia. Sin embargo, existen clientes de terceros como Open WebUI (instalable con Docker) que proporcionan una interfaz web completa conectada a Ollama, con historial de conversaciones, gestión de modelos y soporte multiusuario. Si necesitas GUI y quieres usar Ollama como backend, Open WebUI es la combinación más popular. LM Studio incluye su propia interfaz gráfica sin necesidad de herramientas adicionales.
Ollama ofrece una API REST completamente compatible con el formato de la API de OpenAI
en localhost:11434/v1. Esto permite usar el SDK oficial de Python de OpenAI,
LangChain u otros frameworks apuntando a esa URL sin cambios de código. LM Studio también
ofrece un servidor local compatible con OpenAI en su modo "Local Server" (puerto 1234),
pero requiere que la aplicación de escritorio este abierta y el modelo cargado. Para
integraciones de producción local o servicios en segundo plano, Ollama es más robusto.